Daily Scrum Meeting
Этот митинг проходит каждое утро в начале дня. Он предназначен для того, чтобы все члены команды знали, кто и чем занимается в проекте. Длительность этого митинга строго ограничена и не должна превышать 15 минут. Цель митинга - поделиться информацией. Он не предназначен для решения проблем в проекте. Все требующие специального обсуждения вопросы должны быть вынесены за пределы митинга.
Скрам митинг проводит Скрам Мастер. Он по кругу задает вопросы каждому члену команды
Что сделано вчера? Что будет сделано сегодня? С какими проблемами столкнулся?
Скрам Мастер собирает все открытые для обсуждения вопросы в виде Action Items, например в формате что/кто/когда, например
Обсудить проблему с отрисовкой контрола Петя и Вася Сразу после скрама
Демо и ревью спринта
Рекомендованная длительность: 4 часа
Команда демонстрирует инкремент продукта, созданный за последний спринт. Product Owner, менеджмент, заказчики, пользователи, в свою очередь, его оценивают. Команда рассказывает о поставленных задачах, о том как они были решены, какие препятствия были у них на пути, какие были приняты решения, какие проблемы остались нерешенными. На основании ревью принимающая сторона может сделать выводы о том, как должна дальше развиваться система. Участники миитинга делают выводы о том, как шел процесс в команде и предлагает решения по его улучшению.
Скрам Мастер отвечает за организацию и проведение этого митинга. Команда помогает ему составить адженду и распланировать кто и в какой последовательности что представляет.
Подготовка к митингу не должна занимать у команды много времени (правило - не более двух часов). В частности, именно поэтому запрещается использовать презентации в Power Point. Подготовка к митингу не должна занимать у команды более 2-х часов.
Команда (Team)
В методологии Scrum команда является самоорганизующейся и самоуправляемой. Команда берет на себя обязательства по выполнению объема работ на спринт перед Product Owner. Работа команды оценивается как работа единой группы. В Scrum вклад отдельных членов проектной команды не оценивается, так как это разваливает самоорганизацию команды.
Обязанности команды таковы:
Отвечает за оценку элементов баклога Принимает решение по дизайну и имплементации Разрабатывает софт и предоставляет его заказчику Отслеживает собственный прогресс (вместе со Скрам Мастером). Отвечает за результат перед Product Owner
Размер команды ограничивается размером группы людей, способных эффективно взаимодействовать лицом к лицу. Типичные размер команды - 7 плюс минус 2.
Команда в Scrum кроссфункциональна. В нее входят люди с различными навыками - разработчики, аналитики, тестировщики. Нет заранее определенных и поделенных ролей в команде, ограничивающих область действий членов команды. Команда состоит из инженеров, которые вносят свой вклад в общий успех проекта в соответствии со своими способностями и проектной необходимостью. Команда самоорганизуется для выполнения конкретных задач в проекте, что позволяет ей гибко реагировать на любые возможные задачи.
Для облегчения коммуникаций команда должна находиться в одном месте (colocated). Предпочтительно размещать команду не в кубиках, а в одной общей комнате для того, чтобы уменьшить препятствия для свободного общения. Команде необходимо предоставить все необходимое для комфортной работы, обеспечить досками и флипчартами, предоставить все необходимые инструменты и среду для работы.
Обзор методологии SCRUM
,
Certified Scrum Master
Process Architect и Agile Coach
Компания
Источник:
Независимое некоммерческое сообщество, объединяющее ИТ-профессионалов, занимающихся или интересующихся гибкими методологиями разработки ПО
Остановка спринта (Sprint Abnormal Termination)
Остановка спринта производится в исключительных ситуациях. Спринт может быть остановлен до того, как закончатся отведенные 30 дней. Спринт может остановить команда, если понимает, что не может достичь цели спринта в отведенное время. Спринт может остановить Product Owner, если необходимость в достижении цели спринта исчезла.
После остановки спринта проводится митинг с командой, где обсуждаются причины остановки спринта. После этого начинается новый спринт: производится его планирование и стартуются работы.
Планирование спринта
В начале каждого спринта проводится планирование спринта. В планировании спринта участвуют заказчики, пользователи, менеджмент, Product Owner, Скрам Мастер и команда.
Планирование спринта состоит из двух последовательных митингов.
Планирование спринта, митинг первый
Участники: команда, Product Owner, Scrum Master, пользователи, менеджемент
Цель: Определить цель спринта (Sprint Goal) и Sprint Backlog -функциональность, которая будет разработана в течение следующего спринта для достижения цели спринта.
Артефакт: Sprint Backlog
Планирование спринта, митинг второй
Участники: Скрам Мастер, команда
Цель: определить, как именно будет разрабатываться определенная функциональность для того, чтобы достичь цели спринта. Для каждого элемента Sprint Backlog определяется список задач и оценивается их продолжительность.
Артефакт: в Sprint Backlog появляются задачи
Если в ходе спринта выясняется, что команда не может успеть сделать запланированное на спринт, то Скрам Мастер, Product Owner и команда встречаются и выясняют, как можно сократить scope работ и при этом достичь цели спринта.
Product Backlog
Product Backlog - это приоритезированный список имеющихся на данный момент бизнес-требований и технических требований к системе.
Product Backlog включает в себя use cases, defects, enhancements, technologies, stories, features, issues, и т.д.. Product backlog также включает задачи, важные для команды, например "провести тренинг", "добить всем памяти"
Рис. 2.
Product Backlog постоянно пересматривается и дополняется - в него включаются новые требования, удаляются ненужные, пересматриваются приоритеты. За Product Backlog отвечает Product Owner. Он также работает совместно с командой для того, чтобы получить приближенную оценку на выполнение элементов Product Backlog для того, чтобы более точно расставлять приоритеты в соответствии с необходимым временем на выполнение.
Product Owner
Product Owner - это человек, отвечающий за разработку продукта. Как правило, это product manager для продуктовой разработки, менеджер проекта для внутренней разработки и представитель заказчика для заказной разработки. Product Owner - это единая точка принятия окончательных решений для команды в проекте, именно поэтому это всегда один человек, а не группа или комитет.
Обязанности Product Owner таковы:
Отвечает за формирование product vision Управляет ROI Управляет ожиданиями заказчиков и всех заинтересованных лиц Координирует и приоритизирует Product backlog Предоставляет понятные и тестируемые требования команде Взаимодействует с командой и заказчиком Отвечает за приемку кода в конце каждой итерации
Product Owner ставит задачи команде, но он не вправе ставить задачи конкретному члену проектной команды в течении спринта.
Роли
В методологии Scrum всего три роли.
Scrum Master Product Owner Team
Скрам Мастер (Scrum Master)
Скрам Мастер (Scrum Master) - самая важная роль в методологии. Скрам Мастер отвечает за успех Scrum в проекте. По сути, Скрам Мастер является интерфейсом между менеджментом и командой. Как правило, эту роль в проекте играет менеджер проекта или тимлид. Важно подчеркнуть, что Скрам Мастер не раздает задачи членам команды. В Agile команда является самоорганизующейся и самоуправлямой.
Основные обязанности Скрам Мастера таковы:
Создает атмосферу доверия, Участвует в митингах в качестве фасилитатора Устраняет препятствия Делает проблемы и открытые вопросы видимыми Отвечает за соблюдение практик и процесса в команде
Скрам Мастер ведет Daily Scrum Meeting и отслеживает прогресс команды при помощи Sprint Backlog, отмечая статус всех задач в спринте.
ScrumMaster может также помогать Product Owner создавать Backlog для команды
Sprint Backlog
Sprint Backlog содержит функциональность, выбранную Product Owner из Product Backlog. Все функции разбиты по задачам, каждая из которых оценивается командой. Каждый день команда оценивает объем работы, который нужно проделать для завершения задач.

Рис. 3. Пример Spint Backlog
Сумма оценок оставшейся работы может быть построена как график зависимости от времени. Такой график называется Sprint Burndown chart. Он демонстрирует прогресс команды по ходу спринта.
Рис. 4.
Спринт (Sprint)
В Scrum итерация называется Sprint. Ее длительность составляет 1 месяц (30 дней).
Результатом Sprint является готовый продукт (build), который можно передавать (deliver) заказчику (по крайней мере, система должна быть готова к показу заказчику).
Короткие спринты обеспечивают быстрый feedback проектной команде от заказчика. Заказчик получает возможность гибко управлять scope системы, оценивая результат спринта и предлагая улучшения к созданной функциональности. Такие улучшения попадают в Product Backlog, приоритезируются наравне с прочими требованиями и могут быть запланированы на следующий (или на один из следующих) спринтов.
Каждый спринт представляет собой маленький "водопад". В течение спринта делаются все работы по сбору требований, дизайну, кодированию и тестированию продукта.
Scope спринта должен быть фиксированным. Это позволяет команде давать обязательства на тот объем работ, который должен быть сделан в спринте. Это означает, что Sprint Backlog не может быть изменен никем, кроме команды.
одна из самых популярных методологий
Scrum - одна из самых популярных методологий гибкой разработки. Одна из причин ее популярности - простота. Scrum по-настоящему прост, его можно описать в одной короткой статье, что я и постараюсь сделать в этом обзоре.
Еще раз о пользе отчетов
При любой технологии производства, отчеты - один из самых полезных видов документации. Сделайте отчеты стандартом в вашей организации, вне зависимости от ее размера и рода деятельности. При этом постарайтесь использовать наиболее простую и удобную для ваших сотрудников форму, для того, чтобы не усложнять им жизнь.
я привожу список возможных документов,
Подводя итоги, я привожу список возможных документов, разрабатываемых в рамках вышеописанного технологического процесса
Общая управляющая документация:
Технологическая инструкция "Технология разработки ПО на стадии планирования" Технологическая инструкция "Технология управления запросами на поддержку"
Управляющая проектная документация: Документ "Образ и границы проекта" Документ "Требования к системе"
Другая управляющая документация: Документ "Запрос на поддержку" Документ "Общий список учета запросов на поддержку" Отчеты
Общие рекомендации по организации процесса разработки
Прежде, чем озаботиться созданием основ технологии, необходимо по максимуму решить все организационные проблемы. В литературе часто рассматривается вопрос организации рабочей среды в компании-разработчике ПО, однако, для компании, в которой отдел разработки совсем небольшой (1-3 человека), многие из этих рекомендаций покажутся излишними. Тем не менее, таким компаниям рекомендации нужны не меньше. Из своего опыта я могу рекомендовать следующее:
Постарайтесь, насколько возможно, разделить территориально разработчиков ПО и других специалистов
При современном подходе к разработке ПО весьма высоко ценится легкость коммуникации. Несомненно, прекрасно, когда разработчик может, сделав два шага, уточнить у непосредственного заказчика способ решения проблемы, входные данные или что-либо еще, но, посадив менеджера по продажам и разработчика за соседние столы, вы самое малое в четверть снизите продуктивность труда последнего. Запретите кому бы то ни было, кроме менеджера проекта, непосредственно давать указания разработчикам
Проект с большой долей вероятности выйдет из-под контроля, если разработчики будут выполнять такие, пусть даже срочные, распоряжения. Требования не будут фиксироваться, тесты не будут производиться, модификации будут осуществляться на ходу, разработчики будут вынуждены под давлением давать слишком оптимистичные оценки трудозатрат и всегда чувствовать себя неуспевающими, так как никто не будет знать, сколько работы они выполнили. Выделите либо человека, либо время на обсуждение задач
Практика показывает, что задачи по сопровождению-разработке ПО возникают постоянно в течение дня, обстоятельства почти всегда требуют немедленного выяснения. Если вы имеете двух разработчиков, пусть они по очереди общаются с представителями заказчика, если у вас есть специально выделенный для этого менеджер - пусть общается он. Проблема здесь в том, что административные функции (выяснение обстоятельств проблем, степени их важности, взаимодействие с заинтересованными лицами) требуют оперативности, в то время как техническая реализация запросов, наоборот, наиболее эффективна при возможности сосредоточиться на проблеме на длительное время.
Постоянное отвлечение внимания разработчика, кроме снижения эффективности работы, имеет еще один отрицательный результат: трудность адекватной оценки фактических трудозатрат. Между тем, без фиксирования фактических затрат, разработчик теряет навык делать правильные оценки. Выделите для разработчиков отдельный телефонный номер
Не привлекайте разработчиков к секретарской работе. Разработчики часто ответственные и пунктуальные люди - у менеджеров, при всем к ним уважении, часто нет времени. Не чувствуя характер работы разработчика они могут, безо всякой задней мысли, скинуть половину звонков на них. И вообще, никогда ни при каких обстоятельствах не привлекайте разработчиков к неквалифицированному труду
Если вы, конечно, не боитесь потерять разработчика. Помните, разработчик чрезвычайно ценит свою квалификацию. Хороший разработчик всегда сможет найти себе новую работу, а вы вряд ли легко найдете нового разработчика. Это в крупных организациях с развитым процессом разработки разработчика можно заменить без значительных затрат - а в такой небольшой компании, которая описывается здесь, разработчик может быть единственным носителем знаний о функционирующих программных продуктах, или вообще их единственным автором. Считайте и учитывайте занятость разработчика
В изменяющемся мире бизнеса, например, в телекоммуникационном бизнесе, число задач, связанных с поддержкой существующих систем остается примерно постоянным. Небольшие изменения в существующем ПО требуются регулярно. В процессе разработки нового ПО число систем, которые необходимо сопровождать, растет. Что получается? Суммарное число задач растет со временем. Если разработчик говорит, что он перестает справляться с объемом задач, скорее всего это так. Возьмите еще одного человека, либо закажите разработку и сопровождение части ПО другим организациям. Обеспечьте для разработчиков обучение и обмен опытом
Как руководитель, вы не можете быть в курсе всех последних изменений в мире разработки ПО. Вы можете считать, что человеку, который умеет программировать учиться больше не надо, вполне достаточно опыта, получаемого в процессе работы.Однако если разработчики не будут в курсе последних технологий, ваше ПО устареет очень быстро и станет сдерживающим фактором на пути к новым завоеваниям рынка. В конце концов, создайте документ, описывающий организационную структуру предприятия
Какой бы небольшой ни была ваша компания, такой документ просто необходим. Как минимум, он необходим разработчику, для того, чтобы знать, с кем контактировать по какому вопросу
Я не могу утверждать, что данный список является полным, и вполне вероятно, что можно дать еще некоторые рекомендации, такие, как, например, обеспечить разработчиков всем необходимым аппаратным и программным обеспечением. Дело в том, что я даю рекомендации относительно лишь тех пунктов, которые вызывали наибольшие проблемы в период моей работы в компании описываемого уровня.
Описание специфики разработки
Большое число задач (более половины) связано с сопровождением, поддержкой и доработкой существующего ПО; Задачи, связанные с сопровождением существующих систем практически независимы друг от друга, могут быть решены за небольшое время, но возникают часто и требуют оперативного решения; Разработка и сопровождение ведется небольшой группой специалистов, а зачастую и вообще одним человеком; Как следствие, отсутствует явное разделение ролей в процессе: один и тот же человек может совмещать позиции разработчика, аналитика, архитектора, тестера, системного администратора, менеджера проектов и т.д.; Проекты чаще всего не выходят за рамки внутреннего использования.
Как следствие, процесс разработки ПО в таких компаниях в силу объективных причин достаточно примитивен. Многие технологические процессы отсутствуют или присутствуют в сильно упрощенном варианте. Тем не менее, и такими процессами необходимо управлять и гарантировать приемлемое качество их выполнения.
Планирование реализации требований
Планировать реализацию требований можно в какой угодно форме, однако, мне кажется, что если требований достаточно для того, чтобы спланировать хотя бы одну итерацию, лучше планировать итерацию. Суть итерации заключается в том, что она вмещает в себя полный цикл всех мероприятий по реализации требований: от проектирования архитектуры до поставки новой версии разрабатываемого ПО. При таком подходе в конце каждой итерации мы получаем работоспособный продукт, хоть и с частично реализованной функциональностью. Это позволяет уже через очень короткое время получить первый отзыв заказчика о продукте, подтвердить правильность выбранной реализации, контролировать сроки разработки и, возможно, даже предоставить заказчику для использования наиболее важную функциональность. Для более подробного изучения итеративного процесса разработки я предлагаю обратиться к соответствующей литературе, здесь я постараюсь перечислить некоторые конкретные рекомендации по планированию итераций.
Определите размер итерации
Я всегда планировал двухнедельные итерации и, по моему мнению, это достаточно подходящий размер, потому что за две недели можно сделать не так уж мало, и, в то же время, можно достаточно часто получать результаты и своевременно корректировать ход разработки. Определите объем занятости в человеко-часах на каждую итерацию
Только не пытайтесь спланировать все рабочее время на проектную деятельность. По моим наблюдениям, даже в компании-разработчике ПО у программистов средняя проектная занятость достигает максимум 6 часов в день. Остальное время уходит на организацию работы, деловую переписку, сборку версий, поиск информации в Интернете, установку обновлений, новых версий программ и просто общение. В случае совмещения нескольких обязанностей, я бы не рискнул планировать более половины времени на разработку. Таким образом, приблизительная оценка может быть такой:
| 4 часа в день * 2 недели * 5 дней * 2 разработчика = 80 человеко-часов на итерацию |
Поспешу заверить, что это не так уж мало, как может показаться Планируйте время на выполнение каждого требования
Такие оценки следует доверить разработчику - он лучше всех представляет, сколько времени может потребоваться на реализацию каждого требования. Не спланировав время на выполнение требований, невозможно спланировать итерацию Фиксируйте время, на самом деле потраченное на реализацию каждого из требований
Это необходимо для того, чтобы анализировать, насколько точны оценки, даваемые разработчиком, для того, чтобы оценивать, сколько может потребоваться времени на реализацию похожей функциональности, а главное, это показатель, который фиксирует актуальный объем занятости группы разработки на итерацию на вашем предприятии. Это основная цифра, из которой надо исходить, планируя следующую итерацию Определите порядок определения требований, реализуемых в рамках итерации и действующих лиц
Будет полезно составить технологическую инструкцию, описывающую технологию разработки ПО на стадии планирования конкретно на вашем предприятии.
Основными пунктами такой инструкции могут быть:
Список лиц, утверждающих и согласовывающих документ; Общее описание документа и его предназначения; Описание ролей участников процесса (Заказчик, разработчик). Стоит описать, какие решения принимает каждый из участников и общий характер взаимодействия участников; Пошаговый порядок взаимодействия участников процесса; Перечень разрабатываемых артефактов.
Как и до этого, я рекомендую на начальном этапе включать в такую инструкцию только основные, совершенно необходимые шаги. Ключевым критерием должна быть уверенность, что вы сможете добиться исполнения перечисленных шагов.
Результатом процесса должны стать утвержденные требования к системе, с указанием планируемых трудозатрат, с расставленными приоритетами и распределенные по итерациям. Определите список заинтересованных лиц для каждого проекта
Важно как можно раньше выяснить, кем представлен каждый из классов пользователей при сборе требований, кто назначает приоритеты требованиям и т.д.
Очень важно выяснить, кто должен быть оповещен при выпуске версий!
Если версии не доходят до заинтересованных лиц, нет смысла в их частом выпуске Добейтесь участия в процессе всех заинтересованных лиц
Как показывает практика, бывает так, что люди, заинтересованные в продукте узнают о его разработке только после окончания последней. В этот момент выясняется, что их требования не учтены. Будьте уверены, вам придется реализовать и эти требования, но на поздних этапах работы над проектом, что станет причиной существенных сложностей.
Убедите всех участников обсуждения в том, что их пожелания важны и будут рассмотрены. Только спустя некоторое время работы над проектом, я стал понимать, что некоторые из участников обсуждений не представляли, насколько значимы их предложения для остальных. Как следствие, многие пожелания не высказывались по причине того, что людям казалось, что их пожелания не будут рассмотрены Приоритетами должен управлять 1 человек, и этот процесс должен быть максимально формализован!
По опыту общения с людьми, заинтересованными в проекте, я могу сказать, что у каждого из них, скорее всего, будет свое видение важности реализации каждого из требований. Часто эти люди не могут договориться между собой. Не берите на себя ответственность за то, чтобы решать, чье мнение важнее: это не ваша забота. Пусть руководитель определит, что наиболее приоритетно в его бизнесе Планируйте изменения в итерации
В вышеуказанной инструкции опишите, что должно выполняться в следующих случаях:
Сокращено время проектной занятости группы разработки на текущую итерацию Заказчик изменяет приоритет требований Заказчик изменяет состав требований
Так как заказчик, скорее всего внутренний, вы должны быть готовы в любом из этих случаев идти ему на встречу. Предусмотрите то, как вы будете перераспределять задачи и относитесь к этому с легкостью. Единственное, что не рекомендую делать - это сдвигать сроки завершения итераций - иначе они поплывут, и планирование в какой-то момент прекратится. Старайтесь больше общаться с заказчиком
Даже если вы спланировали завершить итерацию через две недели, поставьте промежуточную версию уже через неделю.Предупредите, что версия может содержать ошибки и не должна использоваться в реальных задачах. Не настаивайте на том, чтобы заказчик смотрел эту версию в работе. Однако, если заказчик заинтересован в продукте и у него найдется время, он сможет вам что-то подсказать или найти ошибку до того, как вы найдете ее сами (если найдете). Таким образом, вы сможете ненавязчиво привлечь заказчика к тестированию Храните документ с требованиями в общедоступном месте
Приучите заказчика и себя к тому, что он (заказчик) может в любой момент ознакомиться с ходом работы и еще раз оценить зафиксированные результаты планирования
Направления улучшения данного процесса:
Ввести более или менее формальную процедуру оценивания заказчиком продукта. Фиксировать отзывы заказчика о продукте Определить, как будет учитываться время на организацию работы, выяснение деталей реализации, совещания и т.д.
Разработка требований
По данному вопросу существуют хорошая и гораздо более подробная и глубокая, чем данная статья, литература. Здесь я опишу тот минимум работы, который, по моему мнению, нужно выполнить для того, чтобы в организации появился повторяемый процесс управления требованиями.
Определите источники требований
В качестве таких источников могут выступать:
Начальники любого уровня Сами разработчики Инженеры других отделов Сотрудники коммерческого отдела, менеджеры Представители сотрудничающей организации Отдел клиентской поддержки (Customer service) Конечные клиенты (Retail customers)
Определите, кто, как и когда может вносить на рассмотрение требования к ПО
При этом не следует ограничивать всех вышеперечисленных действующих лиц какими-либо форматами или средствами. Будьте готовы, что при необходимости требования будут озвучены устно или по телефону, будут отправляться письмом или по ICQ, при чем в том виде, в котором удобно тому, кто данное требование высказывает. В разработке требований будут участвовать самые нетехнические специалисты или даже не специалисты. Главное здесь добиться следующего:
Чтобы разработчик мог работать, не отвлекаясь (см. общие требования по организации процесса разработки). Дать понять всем участникам процесса, что тот факт, что требование зафиксировано, не означает того, что оно будет выполнено.
Участвуйте в разработке требований
Может случиться так, что по разным причинам, вы окажетесь не вовлеченными в процесс обсуждения разрабатываемой системы, и не будете иметь информации о проводимых совещаниях и их результатах. Вместо этого вы будете иметь дело с уже написанными документами. Такое вполне может произойти, если ваша основная позиция - разработчик и считается, что ваша задача - исполнять требования, а не тратить время на их обсуждение. Такое может случиться, если компания имеет несколько территориально удаленных филиалов. В любом случае, постарайтесь убедить руководство в том, что вам, как лицу, осуществляющему планирование и управление процессом разработки, необходимо участвовать в таких обсуждениях
Фиксируйте требования!
Насколько этот пункт важен, настолько же часто им и пренебрегают. Еще раз о том, для чего нужно фиксировать требования:
Чтобы формально утверждать Чтобы планировать работу Чтобы проверять работу Чтобы аргументированно спорить с заказчиком Чтобы обучать разработчиков и пользователей Чтобы иметь возможность проверить правильность работы системы при модификациях Чтобы иметь возможность заменить одну часть системы другой
Фиксируйте источники требований
Это касается как высокоуровневых требований, так и конкретных технических деталей. Если требование или пожелание к системе принято в процессе дискуссии, фиксируйте, кто принимал участие в дискуссии. Это позволит при необходимости выяснить детали, причины требований непосредственно с тем, кто данное требование высказал. Кроме того, вы сможете проанализировать, чьи требования учтены, а чьи - нет.
Утверждайте требования
Определите тех лиц, кто должен утверждать требования. Не приступайте к разработке до того момента, пока требования не утверждены. Сделайте это правилом и не отступайте от этого никогда, иначе вы будете постоянно переделывать одну и ту же функциональность и убирать следы сделанных изменений
В самом простом варианте, я предлагаю следующий формат документа, содержащего утвержденные требования к системе
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| # | User Story | Comments | Priority (1,2...) | Realize in iteration # | Realize in version # | Man-hours estimated | Man-hours used |
Направления улучшения данного процесса:
Фиксировать все требования, а не только утвержденные Хранить версии требований и историю изменений
Своими силами: управление процессом разработки ПО небольшой командой специалистов
,
В любой организации существует необходимость в том, чтобы автоматизировать некоторые, свойственные только ей процессы. В случае, когда потребность в создании специального ПО существенно влияет на бизнес, такое ПО может быть заказано для разработки в сторонних компаниях. Однако зачастую организация вполне способна справится с автоматизацией своими собственными силами - с помощью небольшой группы разработки (от одного до трех человек). Риск заключается в том, что управление процессом разработки в этом случае может лечь на плечи людей, основная специальность которых не связана напрямую с такой деятельностью - программистов, инженеров других специальностей или менеджеров, не знакомых со спецификой разработки ПО. Это может быть первый опыт такого рода для данной организации. При этом не менее важно обеспечить приемлемый уровень качества процессов, связанных с разработкой.
Эта статья написана на основе опыта, полученного мной за год работы менеджером проекта и разработчиком ПО в небольшой телекоммуникационной компании. В ней рассматриваются основные процессы, связанные с разработкой ПО, которые я смог выделить и формализовать. Я стараюсь дать основные рекомендации, которые могут быть полезны при управлении разработкой ПО в такого рода компаниях.
Чтобы стало более понятно, о чем идет речь, для начала я постараюсь дать общую картину производства в области разработки и сопровождения ПО в компаниях, профиль которых не связан напрямую с разработкой ПО.
Управление запросами на поддержку
Процесс разработки и планирования реализации требований, описанный выше, более подходит при разработке нового ПО или существенных доработках существующего, когда требований достаточно много, они взаимосвязаны и относительно невелики по объему. В случае возникновения запросов на поддержку существующего ПО, часто приходится иметь дело с единичными, не связанными друг с другом и достаточно крупными изменениями. Примером такого запроса может служить, например, запрос на модификацию существующих в системе отчетов или запрос на изменение способа обмена данными со сторонней организацией.
В связи с вышеуказанными особенностями, для управления запросами на поддержку в большей степени может подойти несколько отличный от принятого для управления требованиями способ работы и формат документов. Рекомендации тут следующие:
Создайте шаблон документа для того, чтобы фиксировать запросы на поддержку
Рекомендуемое содержание данного документа:
Описание того, как в настоящий момент функционирует система. Здесь следует указать, что в данной реализации работает неправильно Суть изменений, которые следует реализовать в системе Возможные преимущества после исправления недостатков. Этот пункт должен заполнить заказчик Предложения по технической реализации. Если у решения несколько вариантов, здесь должны быть изложены все Предварительная оценка трудозатрат Детали технической реализации. Этот пункт описывает, как конкретно были реализованы изменения Реальные трудозатраты
Даже если с текущей документацией на проект у вас не все в порядке, фиксация запросов на поддержку в таком виде позволит вам в некоторой степени восполнить этот пробел. Если вам необходимо определить, какая документация должна создаваться в первую очередь - вы можете смело приступить именно к фиксации вышеуказанных пунктов Отслеживайте состояние всех запросов на поддержку
Хороший вариант - создать документ приблизительно следующего содержания:
| 1 | 2 | 3 | 4 |
| <SR Name> | Status | To be executed before | Finish date |
| On consideration | |||
| Resolved | |||
| On schedule | |||
| Rejected |
Упомянутых статусов ("На рассмотрении", "Выполнено", "На исполнение", "Отменено") может быть вполне достаточно, чтобы контролировать ход работ. Точное время для выполнения запроса назначать не обязательно, достаточно указать дату, когда запрос должен быть выполнен. Полезным наверняка окажется учет фактической даты окончания работ над запросом Определите порядок обработки запросов на поддержку и действующих лиц
Тут, как и при планировании итераций полезной может стать инструкция, описывающая технологию управления запросами на поддержку. Данный документ по структуре будет практически аналогичным инструкции, определяющей технологию разработки ПО на стадии планирования. Что касается содержания, то одно из отличий проявляется в том, что кроме роли разработчика и заказчика, можно выделить отдельную роль руководителя. Если в случае с требованиями, подразумевается, что руководитель уже дал согласие на начало работ по проекту, а требования утверждает заказчик в лице человека, ответственного за такие решения, то в случае с запросами на поддержку, решение о принятии запроса на исполнение может и не быть принято в силу различных причин
Направления улучшения данного процесса:
Возможно, понадобится более четко определять сроки реализации запросов на поддержку.
Выделение основных процессов
Когда организационные проблемы решены на достаточном уровне, можно сконцентрироваться на процессе разработки.
Несомненно, вряд ли в этом случае удастся реализовать какой-либо тяжеловесный процесс разработки, и литература по данному вопросу, скорее всего, не сильно поможет, но формализовать существующие процессы и сделать их более эффективными постараться стоит.
Мое мнение состоит в том, что основная рекомендация, которую здесь можно дать, звучит так: "Ничего лишнего". Если вы имеете возможность начать с малого, формализуйте только те процессы, которые можете формализовать и создавайте только те документы, которые будут использоваться.
Наиболее вероятно, что вы сможете выделить следующие процессы:
Разработка требований
Планирование реализации требований (Планирование итераций)
Реализация требований
Планирование и реализация запросов на поддержку существующего ПО
Тестирование
На каком-то этапе даже этих процессов будет достаточно. Далее в статье я более подробно разберу процессы, связанные с планированием и управлением проектами и процессом разработки в целом, и попытаюсь дать рекомендации по формализации этих процессов.
Структурное руководство проектом. Серебряная пуля?
 Издательство: КУДИЦ-ОБРАЗ |
ООО ИК СИБИНТЕК
"Кстати, если вампиры на вас все же нападут, [...] с серебряными пулями лучше не баловаться. Ерунда все это, сам пробовал" Емец Д.А. Таня Гроттер и трон Древнира |
Оказывается, серебряная пуля для ИТ проектов появилась уже 10 лет тому назад! А теперь про нее можно прочитать и по-русски. Вот только так ли она действенна, как принято считать?
Увы, разработка программного обеспечения остается одним из самых рискованных занятий. Процент неуспешных проектов, в том числе не уложившихся в сроки или бюджет, наиболее высок именно в области информационных технологий и именно среди проектов, связанных с разработкой ПО. Можно долго рассуждать, почему проекты проваливаются. А можно подумать о том, почему же часть проектов все-таки выполняется успешно. И по второму пути идут очень и очень многие. Существует масса рекомендаций касательно того, как нужно выполнять проект, чтобы "наверняка" или "почти наверняка" выполнить его в срок, в рамках бюджета и удовлетворить все пожелания Заказчика.
Чтобы тебя заметили в такой ситуации, новая методология должна называться как-то очень необычно. Ну, например, "эКСтремальное Программирование", "Кристально ясная", или хотя бы "Рациональный Унифицированный Процесс". А что делать, если новый метод называется просто "Структурное руководство проектами"? Ничего выдающегося... Приходится придумывать запоминающееся название для книги, описывающей вашу методологию.
Именно так и поступил Фергус О'Коннэл, дав своей книжке с достаточно скучным названием "Как успешно руководить проектами" подзаголовок "Серебряная пуля". Собственно, под этим названием она и известна среди англоязычных специалистов. А теперь ее можно прочитать и по-русски (Фергус О'Коннел. Как успешно руководить проектами. Серебряная пуля. М.: КУДИЦ-ОБРАЗ, 2003. - 288 с.).
Для тех, кто не знает. Серебряная пуля - это не только радикальное средство от вампиров.
Этот термин достаточно давно и активно используется в ИТ как символ технологического прорыва, который позволит разрабатывать ПО намного быстрее и качественнее. Дело в том, что Фред Брукс в 1987 году опубликовал очень широко известную статью под названием "No Silver Bullet" - "Серебряной пули не существует" - в которой доказывал, что нет и не предвидится никакого существенного прогресса в процессе разработки программного обеспечения.
Назвать книгу с описанием своей методологии "Серебряная пуля" - это серьезная претензия. И нельзя сказать, что она необоснованна. Как-никак, на английском первое издание "Серебряной пули" вышло в 1993 году. На русский язык книга переведена с третьего издания, вышедшего в 2001 году. Значит, интерес к ней не пропал. Значит, в ней действительно есть что-то важное и полезное, не потерявшее своего значения за 10 лет достаточно бурного развития ИТ. Но, с другой стороны, ведь и спустя десять лет мы говорим все про те же проблемы...
Сам автор говорит, что он написал книгу не про Методологию, а просто про методологию. В чем разница? Чем структурное управление проектами отличается от многочисленных методологий разработки ПО, хотя бы от упомянутых выше?
Самое главное отличие состоит в том, что это книга написана для руководителей проектов. И ТОЛЬКО для руководителей проектов. В ней нет попыток объять необъятное и дать рекомендации и ценные указания всем участникам разработки. Конечно, никто не запрещает читать ее аналитикам или программистам. Но в узко профессиональном смысле они не найдут там почти ничего, адресованного именно им. Зато если вы руководите проектами или собираетесь этим заниматься, то эта книга для вас. В ней описано, что должен сделать человек, руководящий проектом. В каком порядке. И как проверить, что он сделал все как надо.
Суть структурного руководства проектами заключена в 10 этапах, через которые нужно пройти, выполняя проект:
Наглядное представление цели; сосредоточьтесь на призе. Разработка списка задач, которые должны быть выполнены. Должен быть только один лидер. Закрепление людей за задачами. Управление ожидаемыми результатами, расчет резервов для ошибок, выработка запасных позиций. Использование подходящего стиля руководства. Знание того, что происходит. Информирование исполнителей о том, что происходит.. Повторение этапов 1-8 до этапа 10. Приз.
И если вы сумеете выполнить их, успех вашему проекту гарантирован.
При внешней простоте формулировок и некотором сумбуре (часть перечисленных этапов являются скорее принципами, которых нужно придерживаться, чем стадиями разработки в традиционном понимании) здесь скрыты очень серьезные вещи.
Начнем по порядку с первого этапа. Начиная любой проект, вы должны явно представлять, чего вы хотите добиться. Собираетесь ли вы просто заработать на жизнь себе и семье, выполнив проект с минимально необходимым качеством и, соответственно, с минимально необходимыми усилиями? Хотите ли вы освоить новые технологии? Или вы хотите, чтобы этот проект стал переломным в вашей карьере? Для вашей организации?
А что получат от участия в проекте остальные его участники? А что получит Заказчик? Чему будет радоваться он?
Сформулировав для себя ответы на эти, казалось бы, лирические вопросы, вы сможете соотносить каждый свой шаг с реальными целями. И оценивать его именно с этой точки зрения. Приближает ли он вас к достижению цели или ведет в сторону от нее?
Конечно, думать о чем-то, кроме текущих задач, может только достаточно опытный руководитель. Но если вы не будете пытаться, вы этому никогда и не научитесь. Зато, освоив этот прием, вы сможете значительно успешнее планировать работы, решать проблемы с мотивацией (как это теперь называется) ваших сотрудников, договариваться с Заказчиком и многое другое.
Второй этап, я думаю, уже вызвал возмущение среди многих приверженцев современных методологий, которые выучили, что "водопад - это плохо" (имеется в виду водопадный стиль разработки, когда сначала осуществляется анализ, потом последовательно проектирование всей системы, разработка кода, сборка и комплексная отладка). Но обратите внимание на этап 9! Основной особенностью структурного управления проектами является то, что задачи, которые необходимо выполнить для выполнения проекта, выявляются как можно раньше. Как только вы поняли, что вам придется это делать - запишите! Вот, собственно, и вся суть этапа.
При этом, как и в большинстве современных методологий, разработка ведется итерациями. На ближайшую итерацию (обычно, длительностью от 4 до 6 недель) составляется точный и детальный план. На остальные - более общий и приблизительный. Но если вы знаете, что через три итерации вам придется настраивать СУБД для обеспечения максимальной производительности системы, то и запишите это прямо сейчас! У вас будет лишнее время, чтобы подумать, кто и как будет выполнять это работу.
Третий этап (скорее, это все-таки принцип) я, честно говоря, считаю одним из самых принципиальных с точки зрения успешного выполнения проекта. По мнению автора, всякая попытка разделить руководство проектом между несколькими людьми, например, разделив его на техническое и административное, и даже просто наличие слишком сильного неформального лидера в коллективе приводят почти со 100 процентной вероятностью к провалу проекта. Но не менее пагубно сказывается на проекте и любое нежелание руководителя брать ответственность на себя. Руководитель проекта должен помнить днем и ночью, что он отвечает за все! Совсем необязательно и даже совсем нежелательно Руководителю делать все самому. У него есть более важные занятия. Но в любом случае, перед Руководством и Заказчиком за все в проекте отвечает именно он! Я бы добавил, что если вы не согласны отвечать за все, лучше не занимайтесь руководством проектами. Найдите себе более спокойное занятие вроде укрощения диких зверей или одиночных плаваний через океан.
Пожалуй, я бы добавил к данному разделу, что Руководитель проекта должен обладать достаточными полномочиями. Мало того, чтобы все управление проектом шло через единственного Руководителя. Этот Руководитель должен обладать существенными правами в части формирования цели и планов выполнения проекта, возможности непосредственно договариваться с Заказчиком, поощрения и наказания участников и много чего еще. Только в таких условиях единоличная ответственность за выполнение проекта не раздавит, а мобилизует руководителя проекта.
Четвертый этап можно считать развитием принципов предыдущего. У каждого дела внутри проекта должна быть фамилия. Это позволяет более-менее равномерно загрузить сотрудников. Это гарантирует персональную ответственность за выполнение каждой задачи. Здесь, конечно, имеется в виду ответственность внутри команды, для внешнего мира Руководитель отвечает за все.
Возможных исполнителей для каждой задачи можно разделить на несколько категорий. Лучший вариант, если человек заведомо может и при этом хочет выполнить именно эту задачу! Несколько хуже, если его приходится уговаривать (возможно, в следующий раз уговоры не подействуют). Если он недостаточно квалифицирован, но, тем не менее, готов взяться за задачу - его можно обучить (если на это есть деньги и время). Значительно хуже, если он не хочет за нее браться или не может с ней справиться даже после обучения. Хорошо, если для такого сотрудника есть другие задачи, которыми он хочет и может заниматься. Если нет - увы!
При назначении исполнителей необходимо учитывать их общую загрузку. Возможно, человек, на которого вы рассчитываете, уже участвует в других проектах. Или выполняет какие-то другие обязанности. Значит, в вашем проекте он не сможет участвовать пять дней в неделю.
И еще один момент, о котором часто забывают. Административная работа тоже требует времени! И чем больше участников в проекте, тем больше времени нужно на администрирование. Соответственно, и нагрузку на себя руководитель должен планировать с учетом административных задач. Чтобы сократить объем административных задач для Руководителя (например, если он превосходит естественные возможности) можно ввести среди участников проекта внутреннюю структуру и назначить руководителей групп. В этом случае административную работу придется планировать и для них. Причем учтите, что если у вас нет обученных и проверенных руководителей групп, в начальный период вам придется тратить на работу с ними существенно больше времени, чем на рядовых подчиненных!
Пятая стадия - планирование резерва.
Как бы тщательно вы ни планировали, в проект надо заложить определенный резерв на случай непредвиденных ситуаций. Увы, руководство и Заказчики редко соглашаются с этим тезисом. Возможный вариант преодоления такой ситуации - подготовьте несколько планов с разным временем выполнения, штатом и бюджетом (но каждый с запасом). Пусть лучше они выбирают из предложенных планов, а не ковыряются в единственном. Так больше шансов на то, что они не будут возражать против резервов.
А помимо резервов стоит иметь заранее заготовленные планы, что вы будете делать, если что-то пойдет не так. Впрочем, это обычно называется управлением рисками. И в любом руководстве по управлению рисками все это описано более детально.
Пятая стадия знаменует завершение планирования очередной итерации. Теперь пора браться за выполнения планов. И здесь правила не сложнее.
Стадия шесть. Определите, кто из исполнителей требует какого контроля с вашей стороны. Идеальный исполнитель выполняет все, что ему поручили. За другими приходится следить, контролировать скорость выполнения, помогать принимать технические решения... С первыми работать приятно. А с остальными - необходимо. Увы, надо больше времени уделять тому, что необходимо. Таким образом, стадия переходит в принцип: "уделяйте больше внимания тем, кому ваша помощь необходима".
Стадия семь. А здесь, наоборот, принцип превращается в набор работ. Вы должны знать все, что происходит в проекте. И поэтому рабочий день Руководителя начинается с того, что он выясняет, завершены ли работы, которые должны были быть завершены. Начаты ли работы, которые должны были быть начаты. И у кого какие проблемы возникли.
Кроме того, в понедельник хорошо собрать всех (или хотя бы руководителей групп, если проект слишком велик) и обговорить планы на неделю. А в пятницу подвести итоги недели.
Ну а еще нужно контролировать ход проекта по косвенным признакам. Если люди получают удовольствие, - скорее всего, все идет нормально. А вот если есть проблемы в личных отношениях, никто не радуется, то это подозрительно.
Даже если проект пока идет по графику.
Стадия восемь. Информация о ходе выполнения проекта должна быть доступна всем: участникам проекта, Руководству и Заказчику. Может быть, не все должны знать все в полном объеме. Но лгать нельзя никому. Идеальное решение, это еженедельный отчет. Желательно сделать его многоуровневым. Так чтобы на самом верхнем уровне можно было получить ответ на вопрос "Проект в графике?". А на нижнем - сведения по отдельным задачам.
Если все в курсе состояния дел по проекту, то все и действуют адекватно этому состоянию. То есть, если вдруг обнаружилось некоторое отставание, то участники хорошо сработавшейся команды стараются повысить производительность или задержаться после конца рабочего для даже не рассчитывая на оплату сверхурочных. Кстати говоря, и с Заказчиком проще договориться о продлении сроков проекта, если он был в курсе возникавших проблем.
И так до конца итерации. Потом повторить все с самого начала. Не забудьте проверить, не изменились ли ваши цели! Спланируйте следующую итерацию. И выполните ее.
И вот после последней итерации вы, наконец, завершили этот проект! Как пишут в рекламе, вы это заслужили! Но пока все еще в памяти, не забудьте подвести итоги. Что оказалось не так, как вы предполагали изначально? Почему?
На этом книга не заканчивается. В ней приведена масса же конкретных рекомендаций по другим достаточно важным проблемам, часто встающим перед руководителями проектов. Это особенности работы при необходимости одновременно вести несколько проектов. Это принципы разработки и рецензирования планов проекта. Это способы снятия напряжения, приемы разрешения проблем и принятия решений, ведения переговоров и многое другое. И в заключение достаточно полный курс для освоения MS Project.
Надо отметить, что для иллюстрации этапов и принципов управления проектами автор использует много интересных примеров из истории экспедиций Амундсена и Скотта к Южному полюсу и из истории Гражданской войны в США.
Но вернемся к началу.
Сумел ли автор найти серебряную пулю? Неужели разработка ПО остается рискованной только потому, что не все прочитали эту книгу?
Честно говоря, странное ощущение осталось у меня после этой книги. С одной стороны, ну что здесь нового? Все содержание книги можно пересказать в одной фразе. Тщательно управляйте проектом!!! Именно так, с тремя восклицательными знаками. И это - чудодейственная серебряная пуля?
А с другой стороны, разве этого не достаточно, чтобы гарантировать успех? Ведь успешные проекты были во все времена, с использованием всех методологий разработки. И отличались они ни чем иным, как наличием качественного управления. Оно часто было практически незаметно. Начальник не драл глотку и не стучал кулаком по столу. Просто каждый знал, за что отвечает лично он. Когда он должен это сделать. И чем будет заниматься после.
А если вдруг происходило какое-то неприятное и вроде бы совершенно непредвиденное событие, то оказывалось, что к нему все в существенной мере уже готовы. А недостающие детали быстро уточняются и доводятся до всех участников. И проект, лишь слегка поскрипывая на, казалось бы, непреодолимых буераках, весело катит вперед к успешному завершению.
Но если все так просто, то почему же мы никак не забудем про проекты, не уложившиеся в график, в смету, а то и вовсе завершившиеся пшиком? И даже не исследовательские, экспериментальные, прорывные, а такие скромные, типовые проекты...
Потому, что научить правильному стилю руководства очень сложно. Если вы прочитали книжку по UML, то, худо-бедно, вы будете рисовать и понимать UML диаграммы. Если вы прочитали руководство по IDEF1, вы будете понимать диаграммы в нотации IDEF1. А если вы прочитали книжку по структурному управлению проектами, вы, конечно, можете выучить 10 стадий. Но не факт, что вы сумеете их применить.
Вы не верите? Начнем с ключевой стадии. Готовы ли вы признать, что, если проект провалился, то это именно вы лично как руководитель проекта привели его к провалу?
На словах все мы готовы согласиться с тем, что Руководитель должен отвечать за проект.
А на деле часто думаем примерно так: "Но ведь я хороший! Это вот только подчиненные мне достались так себе, если не сказать прямее… Иванов в три раза дольше, чем было запланировано, возился со своим модулем! А Петрова вообще в декрет ушла! А кем я ее заменю? А Сидоров? Ну, переназначили его пять раз на новую задачу до того, как он предыдущую доделал. Но ведь это для проекта так нужно было, а он обижается! И после этого, вы скажете, что я плохо руководил, и поэтому проект затянулся на три года вместо шести месяцев? Да дали бы мне нормальных программистов, я бы... А если я планы не писал, так это для того, чтобы больше времени самому программировать. Если бы не я, вообще неизвестно, закончили ли бы мы этот проект хоть когда-нибудь!"
К сожалению (для проектов, но к счастью для нас самих), человеку свойственно оправдывать самого себя. Поэтому подчиненные валят все на начальников, а начальники - на подчиненных. И далеко не у всех хватает характера и навыков реально проанализировать "А что я сделал не так? А как это можно было сделать лучше?" И еще у меньшего числа людей получается после честных ответов на эти вопросы в следующий раз действительно сделать все лучше, чем в предыдущий. А то ведь тоже нередко можно услышать: "Нет, писать детальные планы - это не для меня!"
Так что серебряные пули есть. Просто они не всем помогают. И если у героя, которому принадлежат слова, взятые в качестве эпиграфа, с ними ничего не получилось, то надо еще разбираться, в чем проблема: в пулях или в герое.
Если же вы все-таки сумеете переломить себя и тщательно спланировать проект… Пусть даже не в MS Project, и даже не на бумаге, а в голове по дороге на работу… Если вы будете помнить, кто из разработчиков чем занят, и тщательно продумывать, кому какую следующую работу лучше назначить… Короче, попробуйте, а вдруг у вас получится!
Ну и еще одно замечание. Даже с самыми замечательными серебряными пулями, чтобы проект был выполнен качественно и в срок, нужно много пота.В том числе от Руководителя проекта. Не скажу, что это гарантирует успех. Скажу по-другому, это делает успех возможным.
Так что не надейтесь, что, прочитав эту книгу, вы получите чудодейственное средство, с помощью которого вы решите все ваши проблемы. Но знакомство с ней позволит вам если не качественнее выполнять ваши обязанности, то, по крайней мере, сравнить свои навыки и привычки как руководителя с опытом неплохого специалиста.
Анализ и трансформации исполняемых UML моделей
Волкова Е.Д., Страбыкин А.Д.,
Труды Института системного программирования РАН
Анализ исполняемых UML-моделей
С целью выявления особенностей использования конечных автоматов UML в реальных промышленных проектах было проведено статистическое исследование набора моделей. Все рассмотренные модели описывают поведение системы с использованием конечных автоматов, по которым можно сгенерировать исполняемый код.
Конечные автоматы UML могут описывать поведение следующих элементов исполняемых моделей:
активный класс (active class); операция (operation); составное состояние (composite state).
В зависимости от своего происхождения, все исследованные модели UML можно разделить на два класса:
модели, изначально спроектированные на языке UML (например, в таких программных системах, как Rational Rose, Telelogic Tau G2, I-Logix Rhapsody, Borland Together); модели, изначально спроектированные на языке SDL (например, в таких программных системах, как Telelogic SDL Suite, Verilog ObjectGeode) и трансформированные в UML вручную или при помощи специальных утилит (например, Telelogic Tau G2 - Import SDL).
Исполняемые UML-модели второго класса в основном описывают различного рода коммуникационные системы (то есть такие классы систем, для моделирования которых предназначен язык SDL). Исполняемые модели первого класса в связи с универсальностью языка UML описывают гораздо более широкий спектр систем.
Аннотация
В статье рассмотрены конечные автоматы языка UML, представлен подход к анализу исполняемых моделей UML. На основании выборки моделей, использованных в промышленных проектах, исследованы их количественные свойства и продемонстрирована актуальность трансформации моделей. Выделены образцы, часто используемые при построении автоматов. Предложены новые трансформации, улучшающие структуру модели, описан процесс их применения к реальной системе. Анализ и трансформации исполняемых UML моделей
Характеристика конечных автоматов
Общая статистика по исследованным моделям представлена в . Перечисленные модели были заимствованы из реальных проектов коммерческих компаний. Для сбора и анализа необходимой информации был разработан дополнительный модуль к промышленной среде UML-моделирования Telelogic Tau G2.
Ожидалось, что модели, используемые в реальных проектах, будут иметь достаточно высокий уровень сложности. Тем не менее, более 90% от всех описанных автоматов содержат не более трех состояний, а доля автоматов без состояний (включающих только один начальный переход) близка к 75% (рис. 1). Причем доля таких автоматов растет вместе с размером модели.
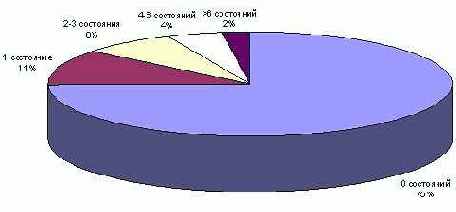
Рис. 1. Количество состояний в конечных автоматах
Следует отметить, что автомат без состояний практически не обладает семантикой автомата и может использоваться только в качестве одной из форм записи некоторой последовательности действий, выполняемой в процессе во время начального перехода. Более того, текстовый синтаксис кажется намного более удобным средством для подобных спецификаций. Таким образом, оказывается, что в промышленных проектах примерно в половине случаев конечные автоматы используются не по своему прямому назначению. Причиной этому может служить недостаточный уровень владения инструментом у разработчиков модели или же, например, требование унифицировать все описания поведенческих аспектов системы с использованием для этого конечных автоматов.
На основе полученных данных использование конечных автоматов без состояний может быть объяснено следующим образом. В рассмотренных моделях операции практически не обладали семантикой состояний, поэтому 99% операций описывались автоматами без состояний, вырождаясь в императивную последовательность действий. Таким образом, использование автоматов для спецификации операций, как правило, не оправдано, и, тем не менее, широко применяется на практике.
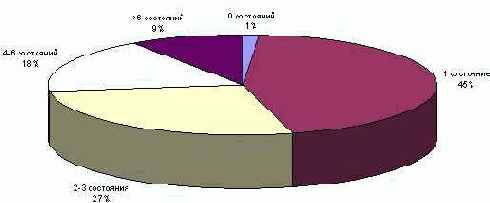
Рис. 2. Количество состояний в конечных автоматах, реализующих классы
Если рассмотреть автоматы, реализующие классы, то распределение количества состояний значительно изменяется (рис. 2).
Для спецификации классов практически не используются автоматы без состояний, в то время как преобладают автоматы, имеющие одно состояние. Такая структура характерна для классов, не обладающих сложной внутренней логикой, а реализующих некоторый сервис для других компонентов системы. В единственном имеющемся состоянии, которое очень часто носит имя "Idle" или "Wait", класс ожидает запроса на выполнение какой-либо операции. Получение запроса инициирует срабатывание перехода, в процессе которого выполняются необходимые действия. По завершении обработки класс вновь возвращается в исходное состояние.
Автоматы, специфицирующие иерархические состояния, составили чуть менее 2% от всех обнаруженных автоматов и были найдены всего лишь в нескольких из рассмотренных моделей, что позволяет сделать вывод об их достаточно редком использовании, несмотря на их выразительную мощность. Причиной тому может служить тот факт, что составные состояния не являлись частью языка SDL до его версии SDL-2000. Большинство крупных промышленных моделей SDL, впоследствии трансформированных в UML, было разработано до того, как появился новый стандарт SDL-2000.
На рис. 3 приведена статистика количества переходов, которые могут сработать в каждом из состояний автомата. И здесь снова 84% процента состояний достаточно просты в понимании, так как имеют не более 6 переходов. Однако состояния с большим числом переходом могут заметно затруднить понимание автомата, а их доля приближается к 15%; более того, как правило, эти состояния являются ключевыми в понимании алгоритмов, заложенных в конкретный автомат.
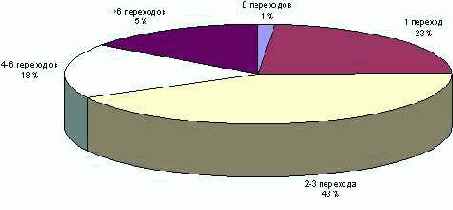
Рис. 3. Количество переходов из состояния
Таким образом, в среднем автомат, реализующий класс, содержит 3 состояния и около 12 переходов и 4 диаграмм, при этом около 90% автоматов содержат не более 6 состояний, и, следовательно, их понимание не должно вызывать серьезных затруднений у разработчиков. Однако внутренняя логика работы системы, как правило, реализуется оставшимися 10%, среди которых встречаются автоматы, насчитывающие до 30 состояний.
Вполне очевидно, что умственные затраты на понимание такого автомата достаточно велики; соответственно, значительно затрудняется процесс его модификации, поиска ошибок и проч. Поэтому средства, уменьшающие сложность автоматов, сохраняя их внешние свойства, действительно востребованы на практике.

Рис. 4. Распределение количества символов на диаграммах
Анализ диаграмм состояний показал (см. рис. 4), что в среднем автомат, реализующий класс, включает в себя 3-4 диаграммы, каждая из которых содержит около 9 символов и 9 линий, что не должно в значительной степени препятствовать пониманию. В то же время для 10% автоматов, описывающих внутреннюю логику работы системы и содержащих более 6 состояний и переходов, количество диаграмм, на которых описан автомат, возрастает до пятидесяти, что очень сильно затрудняет понимание целостной картины работы системы.
Img12b.shtml

Рис. 12. Краткое описание всего конечного автомата
Используемые конструкции
Для повышения уровня выразительности и упрощения описания сложных систем в состав средств описания конечных автоматов UML был включен ряд специальных конструкций. Их использование позволяет во многом упростить и сократить описание сложных автоматов, и поэтому одной из целей проведенного исследования было выявление характера использования подобных конструкций. Далее приведен обзор полученных результатов.
За счет использования операторов ветвления в действиях, выполняемых при срабатывании перехода в автомате, один и тот же переход может в различных условиях перевести автомат в различные состояния. Максимально возможное использование ветвления означало бы наличие в каждом состоянии не более чем одного перехода для любого сигнала. В этом случае выбор состояния, в которое перейдет автомат, происходил бы в процессе интерпретации действий, приписанных переходу. Результаты статистического исследования приведены на рис. 5.

Рис. 5. Ветвистость переходов
Как и следовало ожидать, большинство переходов не разветвляются, а около 90% из них имеет не более трех ветвей. Однако 3% переходов, имеющие более 5 ветвей, могут заметно усложнить понимание логики работы системы. Абсолютный максимум составил 21 ветвь в одном переходе.
Использование графического синтаксиса позволяет проводить графическую декомпозицию диаграмм состояний - распределять сложные автоматы по нескольким графическим сущностям, не упрощая при этом структуру автомата. Этот подход позволяет облегчить процесс понимания деталей работы сложного автомата, однако затрудняет восприятие автомата как единого целого, что немаловажно для понимания логики работы сложной системы.
Одним из средств графической декомпозиции UML являются метки. Они позволяют графически отделить участки диаграммы состояний, чтобы, например, перенести их на другую диаграмму или расположить отдельно на исходной диаграмме. Кроме того, введение меток способствует повторному использованию фрагментов диаграмм, так как переход на единожды описанную метку может быть выполнен многократно из различных частей автомата.
Статистика использования меток приведена на рис. 6.
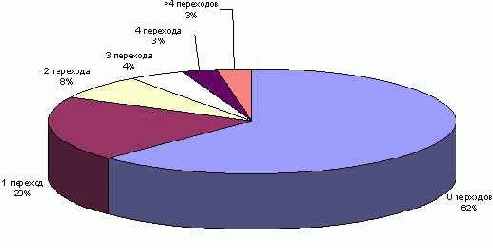
Рис. 6. Распределение переходов на метки
Распределение количества команд перехода на метки очень похоже на распределение количества ветвей. В обоих случаях наиболее простые варианты (одна ветвь и отсутствие переходов на метки) обеспечивают около 60% случаев, а следующие по сложности варианты (две ветви и одна команда перехода на метку) - около 20%, в то время как остальные варианты имеют по 3-4%. Однако в автоматах встречались и переходы, перегруженные командами перехода на метки. Для некоторых переходов в автомате максимальное количество команд перехода на метку превысило 20.
Чтобы избежать дублирования переходов для различных состояний, можно использовать несколько приемов. В UML в символе состояния можно перечислить несколько имен состояний, и тогда все переходы, выходящие из этого символа, будут относиться ко всем перечисленным состояниям. Кроме того, если в качестве имени состояния указать символ «*», то переходы, выходящие из этого символа, будут относиться ко всем состояниям автомата. Также имеется возможность исключить определенные состояния из множества состояний, описываемого символом «*». Умелое использование этих возможностей позволяет значительно упростить описание переходов, применимых более чем к одному состоянию. Результаты статистического исследования показали, что символ * присутствует в 12% символов состояния, что свидетельствует о достаточно активном использовании этой подстановки и необходимости более детального изучения вариантов ее использования и возможных трансформаций с выделением или заменой символа «*».
Кроме того, при описании состояния, в которое должен быть совершен переход, UML позволяет использовать символ «-», означающий состояние, в котором был инициирован исходный переход. Согласно статистике более трети символов состояния содержит символ «-». Это снова свидетельствует об удобстве и востребованности этой конструкции, а также о необходимости исследовать затрагивающие ее трансформации.
Литература
| [1] | Фаулер М., Бек К., Брант Д., Робертс Д., Апдайк У. Рефакторинг: улучшение существующего кода. - СПб.: Символ-Плюс, 2002. - 432 с. |
| [2] | William F. Opdyke, "Refactoring Object-Oriented Frameworks". PhD Thesis, University of Illinois at Urbana-Champaign. Also available as Technical Report UIUCDCS-R-92-1759, Department of Computer Science, University of Illinois at Urbana-Champaign. |
| [3] | Tom Mens. A Survey of Software Refactoring, IEEE Transactions on Software Engineering, Vol. 30, No. 2, February 2004. |
| [4] | Van Gorp, P.; Stenten, H.; Mens, T. and Demeyer, S. Towards Automating Source Consistent UML Refactorings, in Proc. Unified Modeling Language Conf. 2003, 2003. |
| [5] | Astels. D., 'Refactoring with UML', in Marchesi, M and Succi, G (eds). XP 2002 - Proceedings of the 3rd International Conference on eXtreme Programming and Flexible Proceses in Software Engineering, 2002. |
| [6] | Tom Mens, Niels Van Eetvelde, Dirk Janssens, and Serge Demeyer. Formalising refactorings with graph transformations. Fundamenta Informaticae, 2003. |
| [7] | Robert France, Dae-Kyoo Kim, Sudipto Ghosh, and Eunjee Song, "A UML-Based Pattern Specification echnique," IEEE Transactions on Software Engineering, Vol.30, No.3, pp. 193-206, March 2004. |
| [8] | Marciniak J. J. The Encyclopedia of Software Engineering // Wiley Publishers. 2002. - 2076p.: il. |
| [9] | Буч Г., Рамбо Д., Джекобсон А. UML Руководство пользователя // М.: ДМК Пресс. 2001. - 432 с.: ил. |
| [10] | Меллор С., Кларк Э., Футагами Т. // Сайт журнала «Открытые Системы» (2005. 25 июня). |
| [11] | Селич Б., // Сайт журнала «Открытые системы» (2005. 25 июня). |
| [12] | Zs. Pap, I. Majzij, A. Pataricza, A. Szegi. Completeness and Consistency Analysis of UML Statechart Specifications // I.Maizik homepage: URL: (2005. 25 июня). |
| [13] | Unified Modeling Language: Superstructure // OMG official website: URL: (2005. 25 июня). |
| [14] | UML 2.0 OCL Specification // OMG official website: URL: |
| [15] | H. Eriksson, M. Penker, B. Lyons, D. Fado. UML2 Toolkit // Indiapolis: Wiley Publishing Inc. 2004. - 511 p. il. |
| 1(к тексту) | Работа выполнена при поддержке РФФИ, проект 05-01-00998-а. |
Пример «Мобильный телефон»
Продемонстрируем применение трансформации «Выделение части конечного автомата в метод» на одном из конечных автоматов системы Mobile, моделирующей работу мобильного телефона.
В исходной системе конечный автомат представлен на 28 диаграммах, каждая из которых описывает ровно один переход (рис. 11).
Рис. 11. Исходный вид конечного автомата
Такое представление не позволяет понять цельную структуру конечного автомата. Для упрощения понимания была создана дополнительная диаграмма, схематично описывающая весь конечный автомат, иллюстрирующая все состояния и переходы со всеми ветвлениями (рис. 12).
Рис. 12. Краткое описание всего конечного автомата
Приведённый алгоритм позволяет найти и выделить из данного конечного автомата три метода. На первом шаге в метод Initialize() выделяются четыре последовательных состояния (рис. 13).
Рис. 13. Выделение метода Initialize
На втором шаге выделяется метод TalkingThePhone() (рис. 14), после чего становится возможным выделить ещё один метод, который назовём Working().
Рис. 14. Выделение метода TalkingThePhone
Обратим внимание на то, что выделение метода Working возможно только после выделения метода TalkingThePhone. Процесс применения трансформации итеративный. Поиск частей конечного автомата, которые можно вынести в отдельный метод, можно автоматизировать.
В результате применения трансформаций исходный конечный автомат сильно упростился и свободно помещается на одной диаграмме (рис. 15). Теперь он содержит только одно состояние (вместо четырнадцати состояний в исходном автомате) и вызов двух методов.
Рис. 15. Результат трансформации
Выделены три метода Initialize(), TalkingThePhone() (рис. 16) и Working() (рис. 17), содержащие 4, 5 и 4 состояния соответственно.
Рис. 16. Метод Working
Рис. 17. Метод TalkingThePhone
Tab1.shtml
| Aircraft Simulator | Симулятор самолета | UML | 371 | 1 | 2 | 0 | 0 | 34 |
| Central Interface | Система контроля доступа | UML | 253 | 4 | 0 | 1 | 8 | 24 |
| IOS Algorithms | Система ввода/вывода | UML | 1 611 | 11 | 41 | 2 | 70 | 203 |
| Llama Simulator | UML | 894 | 6 | 2 | 0 | 31 | 126 | |
| MMI | UML | 3267 | 17 | 20 | 0 | 45 | 112 | |
| MV-IOS6 | UML | 675 | 5 | 0 | 0 | 14 | 118 | |
| 3gN | UML | 8660 | 12 | 175 | 0 | 2708 | нет инф | |
| ATM and Banklib | Банкомат | SDL | 144 | 4 | 1 | 0 | 4 | 12 |
| Local Exchange | SDL | 178 | 3 | 5 | 0 | 2 | 13 | |
| Access Control | Система контроля доступа | SDL | 281 | 8 | 1 | 0 | 10 | 34 |
| DEL_REL | SDL | 190 | 3 | 2 | 0 | 21 | 22 | |
| Inres | SDL | 121 | 4 | 0 | 0 | 4 | 15 | |
| Mobile | Мобильный телефон | SDL | 772 | 14 | 0 | 0 | 27 | 156 |
| Pager | Пейджер | SDL | 161 | 3 | 4 | 0 | 4 | 14 |
| cc_layer | SDL | 1066 | 3 | 19 | 0 | 45 | 39 | |
| common Executor | SDL | 1396 | 5 | 39 | 0 | 12 | 89 | |
| 1xevdo | SDL | 21817 | 21 | 482 | 0 | 350 | 1457 | |
| ATC_ENV | SDL | 5710 | 17 | 62 | 0 | 867 | 226 | |
| CpCallm | SDL | 67295 | 9 | 760 | 0 | 2262 | 1009 | |
| S | SDL | 380 | 1 | 9 | 0 | 0 | 34 | |
| SS_RCS | SDL | 20572 | 3 | 94 | 0 | 175 | 547 | |
| Tarif_c7 | SDL | 881 | 2 | 25 | 0 | 4 | 104 | |
| DC2000_5 | SDL | 19420 | 33 | 226 | 0 | 447 | 1483 | |
| 23 модели | 7 - UML 16 - SDL | 152 М | 189 | 1969 | 3 | 7110 | 5871 | |
| В среднем: | 6.6 М | 8 | 86 | 0 | 309 | 267 |
Таблица 1. Общая статистика по исследованным UML-моделям.
1 В колонке "пассивные типы данных" учитывались следующие типы: пассивный класс, тип данных (datatype), перечислимый тип (enum), синоним типа (syntype), объединение (choice)
Типичные способы построения конечных автоматов
Анализ полученной выборки не выявил каких-либо стандартов или «правил хорошего тона» при разработке конечных автоматов. Единственным «паттерном» можно считать применяемую одной из компаний методику, когда при описании автомата для каждого перехода из заданного состояния используется отдельная диаграмма, и еще одна диаграмма используется для всех общих описаний. Естественным недостатком такого подхода является сложность получения целостного представления о моделируемом автомате по причине разрозненности отдельных диаграмм, описывающих состояния.
Трансформация «выделение метода» для конечных автоматов UML
Идея трансформации "Extract method" состоит в создании нового метода и переносе части исходного автомата в добавленный метод. Данная трансформация во многом аналогична известному рефакторингу «Extract Method» для объектно-ориентированных языков программирования, описанному в каталоге Фаулера []. Суть традиционной трансформации состоит в выделении участка кода и перемещении его в другой метод. Это позволяет сделать код исходного метода более понятным и повышает вероятность повторного использования выделенного метода.
Для корректного выполнения традиционного рефакторинга "Extract method" требуется тщательный анализ потока данных в выделяемом участке кода, так как все используемые переменные должны быть переданы в метод в качестве параметров, а все изменения переменных должны быть тем или иным образом возвращены исходному методу, если измененные переменные используются в нем далее.
Для первичного рассмотрения проблемы выделения метода в автомате эту проблему можно обойти следующим образом. Если используемая переменная является атрибутом автомата или сущности, содержащей автомат, то она будет видна и в выделенном методе и, следовательно, ее не нужно передавать в качестве параметра. Если же используемая переменная является локальной для действий, выполняемых в переходе, то при перенесении всех действий перехода в выделяемый метод определение локальной переменной и все ее использования будут также перенесены. Для выделения метода, в который помещаются не все действия, выполняемые в переходе, требуется дополнительный анализ потока данных.
Следует подчеркнуть исключительную важность автоматизированной поддержки рефакторинга при проведении подобных преобразований, ибо сложность проводимого анализа будет способствовать ошибкам.
Идея, лежащая в основе традиционного рефакторинга "Extract method", может быть применена к конечным автоматам несколькими способами.
Для конечных автоматов UML можно применить традиционную трансформацию «выделение метода», которая состоит из выделения подпоследовательности действий одного из переходов конечного автомата в метод. В рамках описываемого исследования был разработан новый вариант трансформации «выделение метода», специфичный только для конечных автоматов UML - «выделение в метод части конечного автомата», который подразумевает перенос в выделяемый метод не только действий, связанных с переходом, но и самих переходов и состояний.
При создании сложных инженерных систем
При создании сложных инженерных систем принято использовать приемы моделирования. Сложность большинства создаваемых сегодня программных систем не уступает сложности многих инженерных сооружений, поэтому моделирование программных систем является весьма актуальной задачей. Более того, в таких концепциях, как MDA (Model Driven Architecture - архитектура на основе моделей) и MDD (Model Driven Development - разработка на базе моделей), моделям отводится центральная роль в процессе создания программного продукта. Основной идеей этих концепций является представление процесса создания программного продукта в виде цепочки трансформаций его исходной модели в готовую программную систему.
Почти во всех инструментальных средствах, воплощающих идеи MDD, в качестве языка моделирования используется язык UML (Unified Modeling Language - унифицированный язык моделирования), целиком или какие-либо его части.
UML - это язык, предназначенный для визуализации, специфицирования, конструирования и документирования программных систем. Слово «унифицированный» в названии языка означает, что UML может использоваться для моделирования широкого круга приложений от встроенных систем и систем реального времени до распределенных web-приложений. Выразительные средства языка позволяют описать систему со всех точек зрения, имеющих отношение к разработке и развертыванию.
В свете инициатив MDA и MDD роль моделей в жизненном цикле программного обеспечения (ПО) претерпевает значительные изменения. Если ранее моделирование рассматривалось как одно из удобных средств документирования, и, соответственно, жизненный цикл моделей был близок к жизненному циклу артефактов документации, то в последнее время работа с моделями становится все более похожа на работу с исходными кодами. Подобный подход ставит перед исследователями новые задачи исследования применимости к моделям методик и приемов работы, используемых для работы с исходными кодами. Одной из таких методик является рефакторинг.
Рефакторинг - это изменение внутренней структуры ПО, имеющее целью облегчить понимание и упростить модификацию, но не затрагивающее при этом наблюдаемого поведения.
Рефакторинг, как набор методик преобразования программ, помогает решать две глобальные задачи: облегчение процесса повторного использования каких-либо компонентов программной системы и снижение расходов на поддержку и сопровождение системы. Первые рефакторинги появились в результате обобщения опыта нескольких экспертов в области объектно-ориентированного проектирования. В этом отношении рефакторинги достаточно близки к широко известным на сегодняшний день паттернам проектирования.
Существует много исследовательских работ и публикаций, посвященных методам и алгоритмам применения рефакторинга. Полноценная поддержка рефакторинга ставит перед производителями следующий ряд задач:
поиск плохо спроектированных участков кода (модели), для которых требуется проведение рефакторинга; определение рефакторинга (синтез из поддерживаемых базовых рефакторингов), который следует применить; проверка или доказательство неизменности поведения системы после выполнения преобразований; реализация применения рефакторинга и, в частности, разработка пользовательского интерфейса и диалогов, поддерживающих процесс применения рефакторинга; сохранение целостности модели, то есть распространение произведенных изменений на другие части модели (диаграммы, тесты); оценка эффекта, полученного в результате применения рефакторинга.
По каждому из указанных пунктов ведутся научные разработки, но лишь в немногих из них учитывается специфика UML.
Анализ существующих UML моделей, приводимый в данной статье, показывает, что их структура сложна для понимания и содержит недостатки, которые можно было бы устранить путём проведения эквивалентных трансформаций. Особое внимание уделяется анализу и поиску методов рефакторинга для конечных автоматов языка UML, которые являются основой для полностью автоматической генерации исполняемого кода по UML-моделям. На базе проведённого анализа и выявленных недостатков описывается новая трансформация, специфичная для UML.
Выделение в метод части конечного автомата
Рассмотрим определение части конечного автомата, представленное на рис. 7.

Риc. 7. Часть автомата, допускающая выделение метода
Выбрав часть перехода вместе со следующим состоянием, можно выделить метод, в которую войдет часть состояний конечного автомата, начиная с состояния Y. Будем называть такую трансформацию Extract Sub State Machine.
Применимость данной трансформации связана со следующим свойством. Состояния, переносимые в выделяемый метод, перестают принадлежать исходному автомату и, следовательно, команды перехода, приводящие из состояний исходного автомата в состояния, перенесенные в выделенный автомат, некорректны. Такие команды перехода (смены состояния) должны быть заменены командами вызова выделяемого метода. Однако у автомата, реализующего метод, может быть только одна входная точка, поэтому либо все такие команды должны осуществлять переход в одно и то же состояние, либо можно использовать целочисленный параметр для передачи номера того состояния, с которого должно начаться выполнение метода. Но введение такого параметра и добавление его обработки в начальном переходе усложняет выделяемый автомат и затрудняет его понимание.
Для обработки обратных переходов из состояний выделенного метода в состояния исходного автомата может быть применен следующий прием. Все состояния исходного метода, в которые можно попасть из выделяемого метода, нумеруются последовательными натуральными числами. Все команды перехода, ведущие из состояний выделяемого метода в состояния исходного, заменяются командами возврата из метода, использующими в качестве возвращаемого значения номер того состояния, в которое должен был бы осуществиться переход. После замены тела выделенного метода его вызовом возвращаемое им значение присваивается новой локальной переменной, и после возврата из метода оно анализируется для определения состояния, в которое должен был осуществиться переход. Описанный прием, хотя и позволяет при выделении метода не накладывать ограничений на количество обратных переходов, на практике зачастую только затрудняет понимание автомата, что противоречит целям проведения рефакторинга.
Часть автомата, выделенная в метод, обладает следующей семантикой: получив сигнал Sig3(), автомат выполняет некоторые действия, начиная с состояния y, по завершении которых возвращается в состояние x. Подобная логика близка по смыслу к вызову метода: выполнение задачи с последующим возвратом в исходное состояние. Именно это и служит основанием для выделения метода.
В результате преобразования выделяется структурная единица автомата - метод, а диаграмма, описывающая конечный автомат, уменьшается, что упрощает его понимание Результат преобразования представлен на рис. 8. Выделенный метод показан на рис. 9. Выделенный метод можно использовать повторно для уменьшения дублирования кода.
Существует несколько частных случаев трансформации Extract Sub State Machine.
Ни для одного состояния из RS(x, y) нет перехода в x. Это значит, что возврат из созданного метода невозможен, в конечном автомате найден бесконечный цикл; возможно, это «серверная составляющая» исходного автомата. Множество RS(x,y) содержит символ stop, и ни для одного состояния из RS(x, y) нет перехода в x. Это означает, что выделенная в метод часть автомата рано или могла завершить его работу: либо выделенные действия реализуют необходимую подготовку к завершению работы автомата (аналог деструктора в объектно-ориентированном программировании), либо найдена «серверная составляющая» исходного автомата (только если есть цикл).
Во втором случае выделение метода корректно при выполнении следующих условий:
в выделенном методе все команды завершения работы автомата (stop) должны быть заменены командами возврата из метода (return); вместо действий, приписанных исходному переходу, должен быть добавлен вызов метода P() и команда завершения работы автомата (stop).
В рассматриваемом случае преобразованный автомат будет выглядеть так, как показано на рис. 10
Рис. 10. Результаты применения второго варианта трансформации
Таким образом, задача трансформации моделей
Таким образом, задача трансформации моделей UML является достаточно актуальной. Проведенные исследования подтвердили гипотезу о возможности улучшения структурных качеств и упрощения понимания моделей, применяемых в реальных промышленных проектах. Это ставит перед исследователями задачи поиска новых трансформаций, в которых учитывается специфику моделей UML. Для оценки применимости и полезности трансформаций необходимо продолжение работы по формализации подмножества конечных автоматов UML, описанию семантики их выполнения, а также создание инструментальных средств, автоматизирующих сбор необходимой информации и процесс трансформации моделей.
Аннотация.
Модельно-ориентированный подход к разработке ПО позволяет решить проблемы, связанные с постоянно увеличивающимся количеством технологических платформ, а так же может ускорить разработку и интеграцию систем. Но он станет по настоящему эффективным только когда будут разработаны программные инструменты для его поддержки, что в свою очередь требует разработки технологии автоматизированной трансформации моделей ПО. В данной статье рассмотрены различные подходы к разработке такой технологии, а так же предложен язык программирования, предназначенный для описания трансформаций объектных моделей.
Язык описания трансформации
Описание трансформации представляет собой один или более блоков трансформации. Каждый блок имеет уникальное имя и состоит из последовательности правил трансформации. В заголовке блока может быть также указан параметр, определяющий порядок выполнения этого блока. Ниже приведены фрагменты синтаксической нотации языка трансформации, заданной с помощью расширенных БНФ (форм Бэкуса-Наура). transformation::= <stage>*; stage::= stage <name> [<sequence>] { <transformation_rule>* }; sequence::= [reversed] (linear | loop | rollback | rulebyrule);
Каждое правило имеет уникальное имя и состоит из секции выборки, определяющей, в каких случаях применимо правило, и секции генерации, в которой задаются действия, совершаемые при применении правила.
transformation_rule::= rule <name> { <select_section> <generate_section> };
Секция выборки состоит из последовательности операторов выборки. Каждый оператор выборки объявляет новую переменную, называемую переменной выборки. Имя этой переменной должно быть уникальным в пределах данного правила, а область значений - множество элементов модели, задаваемое с помощью навигационного выражения. Кроме того, секция выборки может содержать уточняющие условия - логические выражения, в котором могут использоваться переменные выборки, объявленные вышестоящими (в рамках правила) операторами выборки.
select_section::= (<select_operator>|<constraint>)*; select_operator::=forall <name> from <nav_expression>; constraint::= where <condition>;
Навигационное выражение - это последовательность направлений навигации, начинающаяся с имени ранее объявленной переменной (назовём её базовой переменной), в качестве разделителя используется символ "/". Направление навигации - это имя ассоциации в метамодели UML, соответствующей трансформируемой UML-модели (если в трансформации участвует несколько моделей с разными метамоделями, то метамодель определяется по тому, на элемент какой модели указывает начальная переменная).
nav_expression::=<name> iteration_pair(/, <nav_direction>);
При вычислении навигационного выражения происходит последовательный переход от одного UML-элемента к другому по ассоциации метамодели, соответствующей очередному направлению навигации, начиная со значения базовой переменной. Под кардинальностью направления навигации будем понимать множественность (multiplicity) соответствующей ассоциации метамодели. Если кардинальность очередного направления навигации больше единицы и существует неоднозначность в выборе элемента модели для перехода, то переход осуществляется по всем вариантам, то есть в результат включаются все подходящие элементы. Формально результат вычисления навигационного выражения можно описать с помощью индукции:
для выражения, состоящего только из имени переменной, результатом является значение этой переменной; процесс вычисления разобьём на шаги: первый шаг - выражение, состоящее только из базовой переменной; на каждом следующем шаге будем добавлять к вычисляемому выражению очередное (слева направо в исходном выражении) направление навигации; результатом вычисления очередного шага будет множество элементов модели, достижимых хотя бы из одного элемента, полученного на предыдущем этапе, переходом по текущему (то есть последнему добавленному) направлению навигации; если исходное выражение содержит последовательность из N направлений навигации, то на (N+1) шаге будет получен результат вычисления этого выражения.
Таким образом, результатом вычисления навигационного выражения является список из всех возможных элементов модели, которых можно достичь из начального элемента, определяемого значением базовой переменной, по заданным направлениям перехода. У навигационного выражения можно выделить следующие характеристики:
Тип - элемент метамодели, соответствующий элементам модели, входящим в результат. Так как навигация задаётся с помощью метамодели, все элементы результата вычисления выражения имеют общий тип. Тип выражения определяется статически (то есть не зависит от конкретной модели, на которой вычисляется выражение). Кардинальность - максимальное число элементов в результате.
Кардинальность выражения равна 1, если кардинальность всех направлений навигации равна 1. Кардинальность определяется статически, по метамодели. Значение - множество элементов модели, являющееся результатом вычисления выражения.
Навигационное выражение может начинаться с любой ранее объявленной локальной или глобальной переменной. Под локальными переменными понимаются переменные, объявленные в исполняемом на данный момент правиле. Разумеется, в каждом конкретном операторе допустимо использовать только локальные переменные, объявленные в вышестоящих (в описании правила) операторах: так как выполнение правила происходит сверху вниз, локальные переменные, порождённые нижестоящими операторами, на момент выполнения текущего оператора ещё не инициализированы. Глобальными переменными являются имена моделей, участвующих в трансформации. Очевидно, что навигационное выражение самого первого оператора выборки каждого правила может начинаться только с глобальной переменной, так как ни одна локальная переменная ещё не объявлена.
Секция генерации - это последовательность операторов создания, изменения или удаления элементов модели. Оператор создания элемента позволяет добавить новый элемент модели в последовательность элементов, оператор удаления - исключить элемент из списка. Соответствующие навигационные выражения указывают на изменяемый список и определяют тип добавляемого элемента. Кардинальность навигационного выражения должна быть больше 1. Оператор изменения позволяет менять значение того или иного поля данных или атрибута; при этом навигационное выражение указывает на изменяемый элемент (и кардинальность выражения должна быть равна единице). Также существуют операции добавления в список уже существующего элемента и исключения элемента из списка; они предназначены для использования в тех случаях, когда в метамодели имеются циклы или один и тот же метаэлемент доступен сразу по нескольким ассоциациям: в таких случаях для формирования модели может оказаться недостаточно операций создания и удаления элементов.
generate_section::= (<create_operator> | <update_operator> | <delete_operator> | <include_operator> | <exclude_operator> )*; create_operator::=make <name> in <nav_expression>; ; update_operator::= <nav_expression> = <expression>; ; delete_operator::= delete <nav_expression>; ; include_operator::=include <name> in <nav_expression>; ; exclude_operator::= exclude <name> in <nav_expression>; ;
Литература
Martin Flower. UML Distilled: A Brief Guide to the Standard Object Modeling Language, Third Edition. Addison Wesley, 2003.
Daniel Varro, Andras Pataricza. UML Action Semantics For Model Transformation Systems. Periodica Polytechnica, no. 3-4, 2003.
Jernej Kovse, Theo Härder. Generic XMI-Based UML Model Transformations. ZDNet UK Whitepapers, 2002.
Keith Duddy, Anna Gerber. Declarative Transformation for Object-Oriented Models. Transformation of Knowledge, Information, and Data: Theory and Applications, 2003.
Krzysztof Czarnecki, Simon Helsen. Classification of Model Transformation Approaches. University of Waterloo, Canada, 2003.
Agrawal, G. Karsai and F. Shi. Graph Transformations on Domain-Specific Models. Journal on Software and Systems Modeling, 2003.
Common Warehouse Metamodel (CWM) Specification. OMG Documents, Feb. 2001.
Anna Gerber, Michael Lawley, Kerry Raymond, Jim Steel, Andrew Wood. Transformation: The Missing Link of MDA. Proceedings 1st International Conference on Graph Transformation (ICGT 2002), 2002.
Anneke Kleppe, Jos Warmer, Wim Bast. MDA Explained. The Model Driven Architecture: Practice and Promise. Pearson Education, 2003.
MDA Guide Version 1.0. Joaquin Miller and Jishnu Mukerji(eds.), 2003.
XSL Transformations (XSLT) v1.0. W3C Recommendation, Nov. 1999.
Meta-Object Facility (MOF) specification, version 1.4 . OMG Documents, Apr. 2002.
D. Chamberlin. XQuery: An XML query language. IBM systems journal, no 4, 2002.
Александр Цимбал. "Технология CORBA для профессионалов". Санкт-Петербург, ЗАО "Питер Бук", 2001.
Механизмы уточнений правил и шаблоны
Для улучшения структуры языка трансформации в него добавлено понятие уточнения правил. При описании любого правила можно объявить, что оно уточняет одно из ранее объявленных правил в рамках того же блока трансформации. Для этого в заголовке правила после его имени указывается имя уточняемого правила. Возможно создание многоярусных древовидных иерархий за счёт дальнейшего уточнения уточняющих правил и создания нескольких уточняющих правил для одного уточняемого. При написании операторов выборки уточняющего правила помимо переменных, объявленных в предыдущих операторах данного правила могут использоваться все переменные выборки из уточняемого правила, а при написании секции генерации - все переменные секций выборки и генерации уточняемого правила.
transformation_rule::= rule <name> [ : <name>] { <select_section> ; <generate_section> };
Уточняющее правило применимо в тех случаях, когда выполняются все условия из следующего списка:
применимо уточняемое правило; найдена выборка, удовлетворяющая секции выборки уточняющего правила; это уточняющее правило ранее не применялось к данному применению уточняемого правила и данной выборке.
Применение уточняющего правила заключается в выполнении операторов секции генерации. После выполнения секции генерации происходит замена трансформационной связи, порождённой применением уточняемого правила, на расширенную трансформационную связь, включающую как старые переменные, так и переменные, объявленные уточняющим правилом. Трансформационная связь при этом именно расширяется за счёт добавления новых полей, старые же поля сохраняются, по аналогии с классическим механизмом наследования. Такая трансформационная связь будет соответствовать как выборкам из совокупности трансформационных связей, нацеленных (с помощью навигационного выражения) на связи, порождённые уточняемым правилом, так и выборкам из связей, порождённых уточняющим правилом. Применение уточнений позволяет структурировать совокупность трансформационных связей и создавать древовидные иерархии наследования среди связей. Так как трансформационные связи можно использовать в описаниях других правил, подобные иерархии позволяют более эффективно описывать трансформации, а также задавать трансформации, которые было бы невозможно задать по-другому.
Шаблон - это специальная разновидность правила, описание которого начинается с ключевого слова "abstract". Сам по себе шаблон не применим никогда, вне зависимости от его секции выборки. Но на основе шаблона за счёт механизма уточнения можно создавать новые правила, которые уже могут быть применены при соответствии выборки и трансформируемой модели. Как и при применении обычных уточнений, использование шаблонов позволяет структурировать совокупность трансформационных связей для её последующего использования в других правилах трансформации. Возможно создание шаблонов как уточнений других шаблонов, но нельзя создать шаблон, являющийся уточнением обычного правила.
Полнота языка трансформации моделей.
Важным требованием к языку описания трансформаций при его использовании в MDA является универсальность - возможность описать с его помощью любое преобразование из PIM в PSM для любой технологии. Причём необходимо учитывать не только все существующие технологии, но и те, которые будут разработаны в будущем. Это означает, что язык должен позволять задавать любые отображения моделей. Будем считать, что все метамодели связны, то есть любой элемент метамодели достижим из корневого элемента метамодели с помощью навигационных выражений.
Теорема 1. С помощью предложенного языка трансформации можно задать любое однозначное отображение моделей.
Для доказательства нам понадобятся две леммы.
Лемма 1. Для любой конечной модели можно написать правило, которое бы было применимо к ней и не применимо к любой другой модели.
Доказательство.
Применимость правила определяется его секцией выборки. Приведём алгоритм построения нужной нам секции выборки, которая бы соответствовала определённой модели a и не соответствовала никакой другой. Для каждого элемента модели ri из a построим оператор выборки forall ri from model/nav_expression, где nav_expression - навигационное выражение, позволяющее выбрать данный элемент (и все остальные элементы того же типа) в модели. Для каждого атрибута ej со значением fj построим уточняющее выражение where ri/ej=fj. Для каждой относящейся к данному элементу связи sj с кардинальностью 1 добавим уточняющее условие where ri/sj=rk, где rk - элемент модели, на который указывает связь. Для каждой связи sj с кардинальностью больше 1, которая связывает данный элемент с элементами rj1…rjn, добавим уточняющее условие where (rj1 belongsto ri/sj) and … and ( rjn belongsto ri/sj) and ((ri/sj exclude rj1 exclude rj2 … exclude rjn)=null) (если связь sj пуста, то есть n=0, то такое уточняющее условие вырождается в where ri/sj=null). Если создать такие операторы выборки и уточнения для всех элементов модели a, то полученная секция выборки будет удовлетворять необходимым свойствам: она применима к модели a и не применима ни к какой другой.
Лемма 2. Для любой модели можно написать правило, которое бы при выполнении создавало эту модель.
Доказательство этой леммы элементарно. Секция генерации позволяет императивно описывать процесс создания модели элемент за элементом. Поэтому для того, чтобы правило генерировало определённую модель a, следует в секцию генерации добавить операторы создания для каждого элемента модели и инициализировать все атрибуты и ссылки их значениями, взятыми из модели.
Доказательство теоремы 1.
Пусть есть множество исходных моделей A и множество генерируемых моделей B, и отображение U, которое каждой исходной модели ставит в соответствие определённую генерируемую модель. Необходимо доказать, что это отображение можно задать с помощью правил трансформации, то есть что ∃T: ∀ a∈A T(a)=U(a), где Т это описание трансформации, а T(a) - результат применения этой трансформации к модели a из A.
Будем строить это описание трансформации следующим образом. Представим отображение U в виде множества пар вида (,). Для каждой такой пары (a,b) в описание трансформации добавим правило специального вида.
Его секция выборки должна быть применима только на модели a, причём ровно один раз. То, что такая секция выборки возможна, доказано в лемме 1. А для того, чтобы правило никогда не применялось дважды (это могло бы случиться, если модель a обладает симметрией), добавим уточняющее условие вида where rules/rule_name=null, где rule_name - имя данного правила. После первого применения правила соответствующее множество трансформационных связей будет не пусто, а условие - ложно, что гарантированно не допустит повторного применения правила.
Секция генерации этого правила при выполнении должна создавать модель b со всеми содержащимися в ней элементами. Существование такой секции генерации доказано в лемме 2.
Итак, правило такого вида будет порождать модель b, если исходная модель - a, и не будет делать ничего (ни разу не будет применено), если исходная модель отлична от a.
Если создать такие правила для всех пар из исходного отображения U и объединить их в блок трансформации, то полученное описание трансформации T и будет искомым. Порядок следования и выполнения правил в блоке может быть любым. Доказательство того, что T- искомое описание трансформации, элементарно:
Возьмём произвольную модель a из множества исходных моделей, ей однозначно соответствует некоторая модель из множества генерируемых моделей, назовём её b. То есть выполняется U(a)=b. Тогда в описании трансформации T содержится правило t, соответствующее паре моделей (a,b), то есть t(a)=b. Так как отображение U однозначно, никаких других правил, применимых к модели а, в описании T не существует. Тогда T(a)=t(a)=b=U(a). Так как a - произвольная исходная модель, доказано что ∀ a∈A T(a)=U(a), то есть построенное нами описание трансформации T задаёт отображение U.
Доказательство окончено.
Существенным недостатком данной теоремы является то, что не гарантируется конечность описания трансформации, то есть если отображается бесконечное множество моделей, то и количество правил трансформации будет не ограничено. Даже если ограничить максимальное число элементов в модели, описание трансформации всё равно может быть бесконечным. Например, существует бесконечно много моделей, состоящих ровно из одного класса без атрибутов и операций, и различающихся только именами класса. Разумеется, на практике такое описание трансформации, состоящее из бесконечного количества правил, реализовано быть не может. Поэтому необходимо знать условия, при которых бы гарантированно существовало конечное описание трансформации.
Определение. Структурой модели назовём набор её элементов и связей между ними, без учёта значений атрибутов. Будем говорить, что две модели (определённые на общей метамодели) имеют общую структуру, если существует взаимно однозначное соответствие между элементами этих моделей, сохраняющее тип элемента и связи между элементами. На практике это означает, что модели имеют одинаковые элементы и связи между ними, но возможно разные значения атрибутов.
Определение. Будем называть модель конечной, если она состоит из конечного числа элементов метамодели. На практике, очевидно, все модели конечны.
Теорема 2. Пусть существует однозначное отображение U(x) множества исходных моделей A на множество генерируемых моделей B, и пусть все модели конечны. Пусть структура любой генерируемой модели зависит только от структуры исходной модели, но не от значений её атрибутов (то есть для любых исходных моделей a1 и a2 с общей структурой их образы U(a1) и U(a2) так же должны иметь общую структуру). И, наконец, пусть значение любого атрибута генерируемой модели может быть выражено как функция от исходной модели с использованием только алгебраических, строковых и теоретико-множественных операций. Тогда существует конечное описание трансформации T, задающее отображение U, причём это описание трансформации всегда выполнимо за конечное время.
Доказательство.
Множество исходных моделей A разобьём на минимальное число групп так, чтобы все модели внутри группы имели одинаковую структуру (то есть отличались только значениями атрибутов). Число таких групп будет конечно, так как по условию число элементов в любой модели конечно, а из конечного числа элементов можно составить конечное число моделей с различной структурой. Так как структура генерируемой модели зависит только от структуры исходной модели, отображение такой группы оператором U так же будет состоять из моделей с одинаковой структурой. Назовём её структурно однородной группой. Следовательно, отображение U можно представить в виде конечного множества отображений U1…Un, каждое из которых отображает структурно однородную группу моделей в структурно однородную группу. Представим это множество отображений в виде конечного множества пар (a, b=U(a)), где a и b - группы моделей с одинаковой структурой. Так же как и в доказательстве теоремы 1, построим правило трансформации для каждой такой пары.
Секция выборки строится аналогично теореме 1, за исключением того, что не добавляются уточняющие условия на значения атрибутов, так как правило пишется сразу для группы моделей и следовательно эти значения не определены.
В секции генерации, так же как и в доказательстве теоремы 1, явным образом используем операторы создания элемента и установления связей между ними. Так как модели в группе имеют общую структуру, генерация элементов и связей одинакова для всех моделей группы. А вот значения атрибутов для разных моделей могут отличаться, поэтому уже невозможно явно присвоить значения атрибутов. Но по условию теоремы, значение любого атрибута r из генерируемой модели bi∈ b может быть представлено как r=f(ai), где аi∈a, а f() - функция, которая может быть выражена через простейшие операции. Функция f() одна и та же для всех аi∈a. Следовательно, если для каждого атрибута r использовать оператор присваивания r=f(a), можно задать значения атрибутов сразу для всех bi∈b.
Итак, полученное правило t будет применимо ко всем моделям группы a, и ни к каким другим. При этом генерируемая модель всегда будет иметь структуру, соответствующую группе b, а значения атрибутов будут соответствовать отображениям конкретной исходной модели, то есть t(ai)=U(ai). Объединив множество таких правил для всех групп, получим описание трансформации T и ∀ а∈A T(a)=U(a). Число правил в описании трансформации равно числу групп моделей с одинаковой структурой. Так как число групп конечно (при условии что все модели конечны), описание трансформации T конечно. Так как для любой исходной модели при трансформации применяется ровно одно правило и только один раз, порядок применения правил в блоке трансформации T не влияет на результат. То есть мы можем назначить линейный порядок, в таком случае трансформация гарантированно завершится за конечное время. Все утверждения теоремы доказаны.
Замечание: на самом деле не обязательно наличие одной общей функции, выражающей атрибуты. Достаточно, чтобы значение каждого атрибута для всего множества генерируемых моделей задавалось с помощью конечного числа функций, представимых с помощью простейших операций над элементами, связями и значениями атрибутов исходных моделей.
Доказательство аналогично доказательству теоремы 2. Но вместо того, чтобы строить отдельное правило для каждой структурно однородной группы, эти группы следует сначала разбить на подгруппы так, чтобы значения атрибутов всех моделей в подгруппе выражались в виде одинаковых функций. Так как общее число функций, задающих атрибуты, конечно, то и число подгрупп будет конечно. Построив правило трансформации для каждой подгруппы так же, как и в доказательстве теоремы 1, и объединив все эти правила в единый блок трансформации, получим искомое описание трансформации.
Условия теоремы 2 можно смягчить ещё больше, но, к сожалению, невозможно совсем от них избавиться, придя к условиям теоремы 1 и сохранив гарантированную конечность описания трансформации. В частности, если значения атрибутов генерируемой модели не выражаются с помощью элементарных операций, то единственный способ задать такое отображение - перечисление. Если множество возможных значений атрибута бесконечно, то и количество правил трансформации, необходимых для задания такого перечисления, будет бесконечно большим. Однако описания трансформаций для большинства практических задач могут быть успешно заданы с помощью предложенного языка трансформации. Необходимо отметить, что используемый в доказательстве теорем метод построения описаний трансформации не рекомендуется для применения на практике, он крайне громоздок и использован только для формального доказательства полноты языка трансформации.
Практическая реализация инструмента трансформации
В настоящее время ведутся работы по практической реализации прототипа инструмента трансформации, поддерживающего описанный выше язык. В целях упрощения работы было принято решение сделать прототип, поддерживающий только одну метамодель (метамодель классов, показанную на ), однако при этом используются универсальные решения, которые можно легко перенести на любую другую модель и внедрить в инструмент поддержку любых метамоделей. На данный момент инструмент поддерживает работу только с парой моделей - исходной и генерируемой, но его функциональность будет расширена для поддержки одновременной трансформации нескольких моделей. Для внешнего представления UML на данный момент используется собственная текстовая нотация, но в будущем планируется включить в инструмент трансформации модуль, позволяющий импортировать и экспортировать модели в XMI-представлении. Это позволит интегрировать инструмент трансформации с различными средами UML-разработки, поддерживающими этот стандарт.
Отдельной и пока не решённой задачей является создание UML-редактора, который мог бы поддерживать соответствие между моделями при внесении в них изменений уже после трансформации. Необходимая для этого информация о трансформационных связях сохраняется, но пока не используется после окончания процесса трансформации.
Пример описания трансформации
Ранее был описан пример трансформации, предназначенной для преобразования платформо-независимой UML-модели классов в платформо-зависимую модель, ориентированную на технологию CORBA. Но этот пример трансформации был описан на естественном языке, а теперь попробуем задать его с помощью формального языка трансформации. В данной трансформации будут участвовать две модели с именами "source" и "target", первая из которых является исходной моделью, а вторая создаётся в процессе выполнения трансформации. Будет использоваться упрощённая метамодель классов UML, приведённая на .
Трансформация будет состоять из одного блока. Ниже показан заголовок этого блока и первое правило, соответствующее фразе "Для каждого класса из PIM следует создать класс реализации в PSM и связанный с ним класс-интерфейс" из неформального описания трансформации.
stage example_CORBA_transformation {
rule class_to_class { forall srcclass from source/classes make implclass in target/classes; implclass/name= srcclass /name+"_implementation"; implclass/stereotype="implementation" make interclass in target/classes; interclass/name=srcclass/name; interclass/stereotype="interface"; make d in target/associations; d/stereotype="realize"; make e in implclass/associations; e/base=d; e/cardinality=1; e/association_end_type="navigable"; include e in d/ends; make f in interclass/associations; f/base=d; f/cardinality=1; f/association_end_type="navigable"; include f in d/ends; e/otherend=f; f/otherend=e; }
Правило "class_to_class" для каждого класса исходной модели создаёт класс-интерфейс и класс-реализацию в генерируемой модели, а так же связь между ними. Далее напишем пару правил, соответствующих утверждениям "Все приватные атрибуты должны быть скопированы в соответствующие классы реализации" и "Публичные атрибуты следует также поместить в класс реализации, но уже как приватные; в интерфейс следует добавить методы для доступа и модификации этих атрибутов".
rule priv_attributes { forall srcclass from source/classes forall srcattrib from a/attributes where ((srcattrib /visibility="private") or (srcattrib /visibility="protected")) forall trgtclass from target/classes forall d from rules/class_to_class where ((d/srcclass=srcclass) and (d/implclass=trgtclass)) make trgtattrib in trgtclass/attributes; trgtattrib/name=srcattrib/name; trgtattrib/visibility=srcattrib/visibility; trgtattrib/type=srcattrib/type; }
rule pub_attributes { forall srcclass from source/classes forall srcattrib from a/attributes where srcattrib/visibility="public" forall implclass from target/classes forall interclass from target/classes forall d from rules/class_to_class where ((d/srcclass=srcclass) and (d/implclass=implclass) and (d/interclass=interclass)) make trgtattrib in implclass/attributes; trgtattrib/name=srcattrib/name; trgtattrib/visibility="private"; trgtattrib/type=srcattrib/type; make getoperation in interclass/operations; getoperation/name="get_"+srcattrib/name; getoperation/type=srcattrib/type; make setoperation in interclass/operations; setoperation/name="set_"+srcattrib/name; make h in setoperation/parameters; h/type=srcattrib/type; }
В этих правилах использована трансформационная связь, образованная применением правила "class_to_class". Благодаря этой связи возможно определить класс-интерфейс и реализацию, порождённые заданным классом исходной модели. Следующее правило из неформального описания - "Публичные операции класса копируются в интерфейс, приватные - в класс реализации", оно описывается с помощью нескольких формальных правил.
rule methods1 { forall srcclass from source/classes forall srcoper from a/operations where srcoper/visibility="public" forall trgtclass from target/classes forall d from rules/class_to_class where ((d/srcclass=srcclass) and (d/interclass=trgtclass)) make trgtoper in trgtclass/operations; trgtoper/name=srcoper/name; trgtoper/type=srcoper/type; trgtoper/visibility=srcoper/visibility; }
rule methods1a { forall a from rules/methods1 forall b from a/srcoper/parameters make c in a/trgtoper/parameters; c/name=b/name; c/type=b/type; }
rule methods2 { forall srcclass from source/classes forall srcoper from a/operations where srcoper/visibility=("private" or "protected") forall trgtclass from target/classes forall d from rules/class_to_class where ((d/srcclass=srcclass) and (d/implclass=trgtclass)) make trgtoper in trgtclass/operations; trgtoper/name=srcoper/name; trgtoper/type=srcoper/type; trgtoper/visibility=srcoper/visibility; }
rule methods2a { forall a from rules/methods2 forall b from a/srcoper/parameters make c in a/trgtoper/parameters; c/name=b/name; c/type=b/type; }
Правила с именами methods1 и methods2 отображают публичные и приватные операции соответственно, а вспомогательные правила methods1a и methods2a нужны для копирования параметров операций. Далее формально зададим утверждение "Ассоциации "один к одному" и "многие к одному" преобразуются в атрибут - объектную ссылку", а так же "Связи-обобщения преобразуются в аналогичные связи-обобщения между классами-интерфейсами".
rule associations_single { forall srcclass from source/classes forall assoc from srcclass/associations where assoc/base/association_type="navigation" where ((assoc/otherEnd/cardinality="1") or (assoc/otherEnd/cardinality="0..1")) where assoc/otherEnd/association_end_type="navigable" forall d from rules/class_to_class where d/srcclass=srcclass forall e from rules/class_to_class where e/srcclass=assoc/otherEnd/class make objptr in d/implclass/attributes; objptr/type=e/interclass/name+"_ptr"; objptr/name=assoc/otherEnd/name; objptr/visibility="private"; }
rule association_generalization { forall srcclass from source/classes forall srcassoc from a/associations where srcassoc/base/association_type="generalization" where srcassoc/otherEnd/association_end_type="navigable" forall c from rules/class_to_class where c/srcclass=srcclass forall d from rules/class_to_class where d/srcclass=srcassoc/otherEnd/class make trgtassoc in target/associations; trgtassoc/association_type="generalization"; trgtassoc/stereotype=srcassoc/base/stereotype; trgassoc/name=srcassoc/base/name; make f in c/interclass/associations; f/name=srcassoc/name; f/cardinality=srcassoc/cardinality; f/association_end_type=srcassoc/association_end_type; include f in trgtassoc/ends; make g in d/interclass/associations; g/name=srcassoc/otherEnd/name; g/cardinality=srcassoc/otherEnd/cardinality; g/association_end_type=srcassoc/otherend/association_end_type; include g in trgtassoc/ends; f/otherend=g; g/otherend=f; }
И, наконец, последнее правило соответствует утверждению "Интерфейсы исходной модели и их связи копируются в генерируемую модель без создания классов-реализаций".
rule interface_mapping { forall a from rules/class_to_class where a/srcclass/stereotype="interface" delete a/implclass; } }
На самом деле данное правило просто удаляет лишние классы реализации, созданные первым правилом. Последняя фигурная скобка обозначает окончание блока трансформации. Итак, полученное описание трансформации формально определяет те преобразования модели, которые необходимы при переходе к PSM, основанной на CORBA и которые были заданы на естественном языке в начале статьи. В результате выполнения этого описания трансформации на какой-либо модели классов будет получена платформо-зависимая модель "target" и совокупность связей между этой моделью и исходной.
Пример простейшей трансформации
Для того чтобы лучше понять требования к языку описания трансформаций, рассмотрим преобразования, необходимые для перехода от платформо-независимой модели к модели, основанной на технологической платформе CORBA []. Пока будем описывать их неформально, на естественном языке. При этом будем стараться задавать эти преобразования в общем виде, не ориентируясь на какую-либо конкретную UML-модель.
Для каждого класса из PIM следует создать одноимённый класс реализации в PSM и связанный с ним класс-интерфейс. Все приватные атрибуты должны быть скопированы в соответствующие классы реализации. Публичные атрибуты следует также поместить в класс реализации, но уже как приватные; в интерфейс следует добавить методы для доступа и модификации этих атрибутов. Публичные методы следует скопировать в интерфейс, приватные - в класс реализации. Ассоциации с множественностью "единица" преобразуются в атрибут-объектную ссылку. Связи-обобщения преобразуются в аналогичные связи между классами-интерфейсами генерируемой модели. Для интерфейсов исходной модели, в отличие от обычных классов, реализаций создавать не надо.
В результате таких преобразований из платформо-независимой UML модели произвольного вида мы получим модель, которая лучше соответствует объектной модели CORBA и более удобна для дальнейшей реализации, чем исходная модель. Разумеется, данное описание является только примером и не задаёт всех аспектов преобразования в CORBA-ориентированную модель, в частности не описано преобразование множественных связей и специальных видов ассоциаций. Описывать трансформацию удобно в виде правил -модификаций модели, которые следует выполнить для определённых элементов исходной модели или групп таких элементов. Формальный язык описания трансформации целесообразно наделить такой же структурой, чтобы облегчить его понимание человеком. Далее мы рассмотрим предлагаемый автором язык описания трансформации, основной структурной единицей которого является правило трансформации.
Принципиальная схема инструмента трансформации
Инструмент трансформации может быть самостоятельным программным продуктом или компонентом среды разработки. При разработке с использованием MDA он предназначен для частичной автоматизации генерации платформо-зависимой модели [].
Входными данными для него являются:
Одна или несколько исходных моделей
Метамодель для каждой модели, принимающей участие в трансформации. Описание трансформации на определённом языке трансформации. Описание трансформации существенно зависит от используемых метамоделей, но по возможности универсально относительно исходных моделей.
Результатом работы инструмента являются:
Набор исходных моделей с изменениями, внесёнными в процессе трансформации. Одна или несколько новых сгенерированных моделей, созданных в процессе трансформации. Наличие и количество таких моделей зависит от используемого описания трансформации. Каждая сгенерированная модель соответствует одной из метамоделей, заданных в качестве исходных данных. Информация о связях и отображениях между элементами модели, образованных в процессе трансформации. Такая информация необходима для того, чтобы далее можно было поддерживать соответствие между моделями при их модификации.
С точки зрения инструмента трансформации нет принципиальной разницы между исходными и генерируемыми моделями: и те и другие в процессе трансформации могут подвергаться изменениям и дополнениям. Поэтому в дальнейшем будем говорить о совокупности моделей, подвергаемых трансформации, понимая под этим как исходные, так и генерируемые модели.
Разные подходы к трансформации UML-моделей
Существует несколько способов описания и выполнения трансформаций UML-моделей []. Простейший способ - это явное императивное описание процесса трансформации с использованием любого алгоритмического языка. При этом подходе в среду разработки на этапе её создания встраивается набор трансформаций, которые позднее могут быть задействованы пользователем. У этого подхода имеются существенные недостатки, которые делают его малопригодным для использования в средах разработки, поддерживающих MDA. Прежде всего, у пользователя отсутствует возможность добавлять новые описания трансформаций или изменять существующие; он вынужден использовать то, что сделано разработчиками инструмента. Кроме того, из-за отсутствия единого стандарта описания трансформаций разные среды разработки неминуемо будут выполнять трансформации по-разному даже для одной и той же технологической платформы, что может привести к возникновению случаев несовместимости и затруднит смену сред разработки: вместо зависимости от технологической платформы программист окажется в зависимости от выбранной им среды разработки. И наконец, подобный подход означает, что для каждой среды разработки придётся писать полный набор описаний трансформаций для всех популярных технологий, вместо того чтобы использовать стандартные описания трансформаций, созданные независимыми разработчиками.
Другой подход - использование уже разработанных механизмов трансформаций и преобразований из других областей информатики. В частности, можно представить UML-модель в виде графа и использовать математический аппарат трансформации графов []. Главный недостаток такого подхода состоит в том, что в нем используется собственный понятийный аппарат, не имеющий отношения к UML-моделированию. Это значит, что от пользователей такой системы требуется знание не только UML-моделирования, но и теории графов и принципов их трансформации. Кроме того, поскольку UML-модель несёт семантическую нагрузку, отличную от формального графа, правила трансформации, сформулированные для графа, будут трудны для понимания с точки зрения UML-модели: для понимания трансформации придётся мысленно совершать переход от графа к породившей его UML-модели, а для внесения изменений в описание трансформации - от UML к графу.
Ещё один вариант заключается в использовании методик трансформации XML-документов и стандарта XMI []. XMI (XML Metadata Interchange) - это стандарт, позволяющий представить UML модель в виде XML документа. Он предназначен главным образом для хранения UML-данных, а так же любых других данных, метамодель которых задана с помощью MOF (Meta Object Facility) [] и обмена ими между различными инструментами и средами разработки. MOF - это стандарт описания метамоделей, с помощью которого в частности можно описать структуру и общий вид UML-модели. Для XML существует несколько хорошо развитых методик трансформации, в частности XSLT [] и XQuery []. Для трансформации UML-модели можно преобразовать её в XMI-представление, выполнить трансформацию средствами работы с XML, и затем преобразовать результат обратно в UML. Но XMI разрабатывался прежде всего как стандарт хранения и обмена UML-данными, он сложен для чтения и понимания пользователем. Также очень сложно понять функционирование трансформации, описывающей преобразование XML-документа, с точки зрения UML-модели, которой соответствует этот документ. Из-за того, что трансформация описывается в терминах XML, а не UML большая часть описания трансформации оказывается направленной на то, чтобы в результате получить XML-документ, соответствующий стандарту XMI, а не на собственно описание трансформации UML.
Язык моделирования UML считается универсальным, и, конечно же, он содержит средства описания трансформаций. В частности стандарт CWM (Common Warehouse Metamodel) позволяет описывать трансформации и преобразования []. Идея использовать UML для описания трансформаций UML-моделей подобно тому, как на UML описывается синтаксис UML, выглядит заманчиво, но трудно реализуема на практике. CWM даёт возможность только описывать сам факт того, что между определёнными элементами модели существует отображение, но не содержит развитых средств для задания трансформаций в общем виде (декларативно или императивно). Ещё один стандарт из семейства UML - QVT (Query, View, Transformation) - представляет значительно больший интерес с точки зрения его применения в MDA.
Но, к сожалению, на данный момент этот стандарт находится на ранних этапах разработки. Кроме того, вызывает опасение тот факт, что в рамках этого стандарта предполагается решить сразу несколько общих задач, и то, что QVT ориентирован прежде всего не на практическое применение, а на развитие концепции метаметамоделирования в рамках MOF (Meta Object Facility). Существует вероятность того, что из за подобной направленности на теорию и на решение задач в общем виде этот стандарт будет неудобен для использования на практике в задачах, специфичных для MDA, хотя ни в чём нельзя быть уверенным, пока стандарт ещё не принят хотя бы в ранней версии.
Представляет интерес разработка языка и средства трансформации моделей, предназначенного именно для применения в MDA. Возможно, такое средство трансформации окажется более удобным и эффективным в данной узкой области, чем адаптация более универсального стандарта. Ниже будет рассмотрен один из таких языков трансформации, предлагаемый автором.
Трансформация UML-моделей и ее применение в технологии MDA
Препринт Института Системного Программирования РАН
Трансформационная связь и её использование в описании трансформации
Каждый раз, когда выполняется то или иное правило, помимо выполнения действий, описанных в секции генерации, создаётся специальная структура данных, называемая трансформационной связью. Имя этой структуры совпадает c именем правила, а полями данных являются локальные переменные, объявленные в описании правила (в операторах выборки и операторах создания). Значения этих полей данных совпадают со значениями соответствующих переменных, определённых в процессе выполнения правил.
Трансформационные связи, образованные в процессе трансформации, объединяются в совокупность трансформационных связей. Она содержит информацию о ходе трансформации, применённых правилах и о том, как и почему был изменён или создан тот или иной элемент модели. Эту информацию после выполнения трансформации можно использовать для поддержания соответствия между моделями при их модификации.
Совокупность трансформационных связей может использоваться не только после завершения трансформации, но и в процессе ее выполнения. В операторах выборки, заданных в описании трансформации, вместо навигации по модели возможна навигация по трансформационным связям, порождённым ранее применёнными правилами. Для этого в операторе выборки используется навигационное выражение особой структуры. В отличие от обычного навигационного выражения, навигация по совокупности трансформационных связей начинается не с локальной переменной или имени модели, а с имени блока трансформации. После имени блока следует имя правила и имя локальной переменной из этого правила. Так как любое правило в процессе трансформации может быть применено несколько раз, и, соответственно, в совокупности связей может присутствовать несколько экземпляров соответствующей трансформационной связи, кардинальность подобного навигационного выражения всегда больше единицы. <special_nav_expression>::=<block_name>/<rule_name>/<variable_name>;
Вместо имени блока можно использовать ключевое слово "rules", которое эквивалентно имени текущего блока. Следует отметить, что, поскольку блоки трансформации исполняются последовательно, в каждом блоке возможно использование информации о трансформационных связях данного блока и блоков, стоящих в описании трансформации перед ним. Блоки, располагающиеся в описании трансформации после текущего, ещё не выполнены и не имеют трансформационных связей.
Использование трансформационных связей в описании трансформации позволяет создавать зависимости между применением правил и более точно определять, в каком случае должно быть применено то или иное правило. Это, в свою очередь, позволяет описывать нетривиальные преобразования моделей в компактной и простой для понимания форме.
и активно используются множество стандартов,
На данный момент разработаны и активно используются множество стандартов, middleware-технологий и платформ (CORBA, DCOM, Dot-Net, WebServices, JAVA-технологии и т.д.), и в будущем их количество будет расти. Попытки создать универсальную платформу, которая бы заменила все существующие, привели только к увеличению количества используемых технологий. Всё более важными становятся вопросы выбора технологии для конкретного проекта, осуществления взаимодействия и интеграции разнородных систем и переносе систем на новую технологическую платформу, когда используемая платформа устаревает и уже не может удовлетворить потребности заказчика. Решение может лежать в использовании новой, более совершенной методики разработки ПО.
Model Driven Architecture (MDA) - новый подход к разработке ПО, предложенный консорциумом OMG []. Архитектура MDA может предоставить ряд преимуществ по сравнению с существующими методиками: упрощение разработки многоплатформенных систем, простота смены технологической платформы, повышение скорости разработки и качества разрабатываемых программ и многое другое. Однако всё это станет возможным только тогда, когда среды разработки будут поддерживать новую технологию и полностью реализовывать её потенциал. К сожалению, на данный момент большинство коммерческих продуктов, для которых заявлена поддержка MDA, реально не предоставляют соответствующих инструментов; в связи с этим эффективное применение MDA для решения реальных задач затруднено.
В основе MDA лежат понятия платформо-независимой и платформо-зависимой моделей (platform-independent and platform-specific models, PIMs and PSMs) []. В процессе разработки системы сначала создаётся PIM - модель, содержащая бизнес-логику системы без конкретных деталей её реализации, относящихся к какой либо технологической платформе. Принципиальным является именно тот факт, что на этапе создания этой модели не принимается никаких решений по поводу её реализации, разрабатываемый программный продукт не привязывается к технологиям.
Это означает, что описание трансформации должно быть понятно не только создавшему его программисту, но и тому, кто планирует его использовать. Язык описания трансформации должен быть понятным для человека и иметь легко читаемую нотацию. Также желательно, чтобы язык допускал эффективное структурирование описания трансформации, то есть его разбиение на слабо зависимые части. Без подобного структурирования будет очень сложно изменять описание трансформации большого объёма, так как для оценки результата изменения придётся проверять всё описание трансформации, а не только его структурно независимую часть. Взаимосвязанная трансформация нескольких моделей. При разработке ПО с использованием MDA в рамках одного проекта может иметься несколько UML-моделей (соответствующих разным метамоделям или разным технологическим платформам). Поэтому язык трансформации должен предусматривать наличие более чем одной исходной и генерируемой модели. Если трансформация всех моделей происходит одновременно и по общему описанию, то процесс трансформации проще описывать (по сравнению со случаем, когда для каждой генерируемой модели существует отдельное описание трансформации), так как обычно трансформация моделей одного проекта имеет много общего. Кроме того, при одновременной трансформации проще выявлять соответствие между элементами моделей и генерировать разного рода вспомогательные модели (межплатформенные адаптеры, описания интерфейсов и т.д.).
Выполнение трансформации
Теперь, когда определён синтаксис языка трансформации, опишем процедуру выполнения трансформации. Инструмент трансформации, получив в качестве входных данных исходную модель (или несколько моделей) и описание трансформации, а также имея информацию об используемой метамодели, может выполнить заданную трансформацию. При этом, в зависимости от описания трансформации, возможно как изменение исходной модели, так и создание новой.
Выполнение трансформации заключается в последовательном применении блоков трансформации. Выполнение блока состоит в нахождении в этом блоке правила, которое может быть применено в данный момент, и применении этого правила.
Применимость правила определяется по его секции выборки.
Каждый оператор выборки объявляет новую переменную и с помощью навигационного выражения определяет множество возможных значений этой переменной на данной модели. Секция выборки может также содержать уточняющие условия; конъюнкцию всех таких условий назовём обобщённым уточняющим условием. Множество возможных выборок - это декартово произведение множеств значений переменных выборки, ограниченное уточняющим условием, то есть множество всевозможных наборов значений переменных, для которых обобщённое уточняющее условие истинно. Выборкой назовём произвольный элемент этого множества. Правило применимо, если для текущего состояния трансформируемой модели (совокупности моделей) существует такая выборка, для которой это правило не было применено ранее. Применение правила к выборке состоит в последовательном выполнении всех операторов секции генерации. При этом значениями переменных выборки являются соответствующие компоненты выборки, для которой применяется правило. Каждый раз, когда применяется правило, создаётся новый экземпляр трансформационной связи, порождённой этим правилом. (О том, что такое трансформационная связь, будет сказано позже.)
Если правило применимо более чем к одной выборке, то для выполнения случайным образом выбирается одна из них (вообще говоря случайным образом, в зависимости от реализации).
Далее, в зависимости от порядка применения правил в блоке, правило может быть применено к другим выборкам, или может начаться выполнение другого правила.
Порядок применения правил определяется заданной при создании описания трансформации последовательностью применения правил в блоке. Она задаётся с помощью параметра <sequence> в заголовке блока. Если значением параметра является "linear", то блок выполняется линейно сверху вниз, то есть поиск следующего применимого правила осуществляется в порядке объявления правил в описании трансформации, начиная с последнего выполненного правила. Когда процесс доходит до последнего правила в блоке, выполнение блока завершается. При значении параметра "loop" процесс выполнения также происходит сверху вниз по описанию трансформации, но после достижения последнего правила выполнение блока не заканчивается, а продолжается с первого правила в описании блока. Если значением параметра является"rollback", то после каждого применения правила поиск следующего применимого правила начинается с первого правила в описании блока, а не с последнего применённого правила, как в предыдущих вариантах. При значении параметра "rulebyrule" поиск применимого правила также начинается с первого правила в описании блока, но после нахождения применимого правила оно выполняется для всех возможных значений выборки, и только после того, как все возможности применения этого правила исчерпаны, происходит поиск другого применимого правила (начиная с первого правила в описании блока). Также возможно применение описанных выше параметров совместно с ключевым словом "reversed". В этом случае процесс поиска применимого правила происходит не в порядке объявления правил в описании блока, а в обратном порядке. Значение параметра <sequence> по умолчанию - "rulebyrule", так как такая последовательность выполнения правил приводит к наиболее быстрому завершению трансформации.
Если ни одно правило из блока трансформации больше не может быть применено, или если достигнут конец описания блока при линейном ("linear") порядке выполнения, то этот блок трансформации считается завершённым и начинает выполняться следующий.Трансформация считается завершенной, когда выполнен последний блок.
Следует отметить, что для произвольного описания трансформации не гарантируется завершение процесса трансформации для любой модели; при использовании правил с операторами создания элемента модели возможны бесконечные циклы. Это необходимо учитывать как при создании описания трансформации, так и при его использовании.
Технология MDA может оказаться новой
Технология MDA может оказаться новой ступенью эволюции средств и методик разработки программных систем. Но это станет возможно только в том случае, если появятся инструменты разработки, специально предназначенные для этой технологии и максимально использующие её потенциал. Существующие на данный момент инструменты являются в основном адаптациями и расширениями старых разработок, они только поддерживают подход MDA, но не предназначены для него. Таких инструментов недостаточно, чтобы реализовать среду разработки ПО нового поколения. Поэтому на данный момент ведётся множество разработок инструментария для MDA.
Одна из важнейших и самых сложных возникающих при этом задач состоит в автоматизации трансформации моделей. Ранее этой задаче не уделялось должного внимания, так как область применения возможных результатов была ограничена. Существующие методики и заимствования из других областей информатики оказываются малоэффективными и неудобными для решения практически задач, поставленных технологией MDA. Поэтому актуальна задача разработки методики описания и выполнения трансформации моделей с учётом особенностей её применения для MDA.
В данной работе предложен язык описания трансформации, предназначенный, прежде всего, для применения к моделям UML (впрочем, благодаря поддержке различных метамоделей, он может быть использован и для трансформации других моделей). При разработке языка учитывались особенности его применения в технологии MDA. Особое внимание было уделено понятности языка для человека и хорошей структурированности описаний трансформации на этом языке.