Основные определения
Концепт- не зависящее от конкретного языка понятие, соответствующее реальной или абстрактной сущности, свойству, действию, либо иному элементу, отражающему связь между другими понятиями.
Термин- слово или словосочетание на заданном языке, обозначающее в этом языке конкретный концепт.
Терминология- множество обозначающих один и тот же концепт терминов из различных языков.
Сегмент- непрерывный фрагмент текста, состоящего из терминов одного языка, обозначающих связанную по некоторому критерию группу концептов.
Вариант сегмента- сегмент, похожий на исходный по некоторому критерию.
Исходный язык- язык, с которого осуществляется перевод.
Целевой язык- язык, на который осуществляется перевод.
Языковая пара- упорядоченная пара сегментов, объявленных переводчиком эквивалентными по смыслу, первый из которых содержит термины на исходном языке, а второй- на целевом.
Предметом настоящего обзора является отладка систем реального времени.
Под системой реального времени (СРВ) мы понимаем систему, в которой корректность функционирования зависит от соблюдения временных ограничений.
Существующие СРВ являются многозадачными. Многозадачность реализуется через многопроцессность*) и многопоточность.
Под процессом понимается держатель ресурсов (например, память, данные, дескрипторы открытых файлов), которые не разделяются с другими процессами. В рамках одного процесса выполняются один или несколько потоков. Они совместно используют ресурсы процесса.
Многопроцессность в СРВ имеет существенные недостатки, поскольку требует поддержки времени выполнения для доступа к памяти, и, следовательно, при переключении контекстов системе нужно выполнить дополнительные действия.
Многопоточность - это наиболее распространенный подход при проектировании систем реального времени, при котором СРВ представляет собой один процесс, в рамках которого запущено несколько потоков.
Недостатком многопоточности является возможность модификации чужих данных какой-либо задачей (из-за отсутствия защиты). В связи с этим в СРВ представлены средства синхронизации, то есть средства, обеспечивающие задачам доступ к разделяемым ресурсам. К таким средствам относятся семафоры (бинарные и счетчики), мьютексы, очереди сообщений (см. [1],[3],[25]).
Структура СРВ приведена на рис.1, где прикладной код - это совокупность пользовательских потоков управления, ОСРВ - операционная система реального времени, обеспечивающая планирование, синхронизацию и взаимодействие пользовательских потоков управления.

Рис. 1. Структура системы реального времени
Будем называть распределенную систему распределенной системой реального времени (РСРВ), если корректность ее функционирования зависит также и от ограничений, накладываемых на время обмена между компонентами системы.
Основные подсистемы Rapid Developer
Работа в Rapid Developer ведется в итеративном режиме. Подход простой - сначала смоделировать некоторую функциональность системы, а затем дорабатывать ее. Моделирование, как и всегда, основано на различных представлениях информационной системы (представление классов, структуры сайта, баз данных и т.д.).

Рис. 1. Итеративный процесс разработки
Rapid Developer включает несколько подсистем моделирования, с помощью которых ведется процесс постепенной разработки информационной системы. Продукт состоит из следующих основных подсистем:
Архитектор приложения. Подсистема описания бизнес-процессов. Архитектор классов. Подсистема определения бизнес-правил. Архитектор сайта. Архитектор Web-страниц. Подсистема формирования тем и стилей. Архитектор баз данных. Архитектор распределения артефактов системы. Архитектор логики .
Кратко указанные подсистемы будут рассмотрены ниже.
Импорт существующих наработок и работа в различных подсистемах Rapid Developer выражается в наполнении единого репозитория проекта. В любой момент разработки легко развернуть проектируемую информационную систему на сервере приложений и проверить добавленную функциональность.

Рис. 2. Подсистемы Rapid Developer
Запуск конкретного архитектора осуществляется либо с помощью группы пунктов главного меню "Architects", либо с помощью кнопок следующей панели инструментов:

Рис. 3. Кнопки запуска архитекторов Rapid Developer
На рис. 3 отображены кнопки позволяющие осуществить запуск:
Архитектора приложения (кнопка "A"). Архитектора классов (кнопка "C"). Архитектора сайта (кнопка "S"). Архитектора Web-страниц (кнопка "P"). Подсистема формирования тем и стилей (кнопка "T"). Архитектора распределения артефактов системы (кнопка "D"). Архитектора логики (кнопка "L").
Подсистемы описания бизнес-процессов и определения тем и стилей запускаются из разных архитекторов при необходимости.
Основные преимущества, достигаемые при переходе в 3-звенную архитектуру.
Введение дополнительного звена в цепочку клиент-сервер должно быть вызвано ощутимыми преимуществами, получаемыми при реальной эксплуатации результирующей информационной системы. Собственно, так и происходит:
в системе с применением Baikonur Web App Server не накладываются жесткие ограничения на тип операционной системы и мощность клиентского рабочего места. В то время как в клиент-серверных системах минимальные требования к рабочему месту - 16Mb ОЗУ, а если используется другой тип операционной системы, разработчикам приходится дублировать разработку клиентской части для другой операционной системы. Применение Baikonur позволяет использовать стандартные Internet-браузеры для оснащения клиентского места, работающие при минимуме оперативной памяти на клиентском рабочем месте.
Клиентские рабочие места могут работать с сервером Baikonur удаленно, не подвергаясь существенной переделке, в то время как стандартный клиент-серверный подход не является настолько отработанным, чтобы клиентское рабочее место легко без изменения могло работать в удаленном режиме. В случае Baikonur различные практические вопросы при использовании удаленного рабочего места (типа "что произойдет, если случится обрыв линии, сохранится ли контекст задачи, существует ли возможность присоединиться к уже запущенным задачам с другого рабочего места", как решить проблему удаленного администрирования, вопросы помех на линии, вопросы доступа как через модемный пул, так и через Internet, вопросы безопасности данных, вопросы насыщенности сетевого траффика и т.д.) решаются без особых трудностей, поскольку исторически Internet-технологии в первую очередь решали именно эти задачи, и именно в этих вопросах накоплен наибольший опыт.
Система с использованием Baikonur легко масштабируется
от небольшой системы уровня рабочей группы до системы масштаба нескольких тысяч одновременно работающих рабочих мест. Все это может быть произведено без существенной переделки системы простым увеличением мощности аппаратуры сервера приложений или использованием нескольких серверов приложений.
Лицензионная политика для SQL-серверов и для Web-серверов, к которым относится в этом вопросе и Baikonur Web App Server, существенно отличается.
При покупке SQL- сервера предприятие обязано оплатить лицензии на каждое рабочее место, одновременно работающее с сервером. В случае Baikonur Web App Server оплачивается только лицензия на сервер. Различные версии Baikonur рассчитаны на различную суммарную нагрузку. В случае, если с базой данных одновременно работает 200 человек, реальное количество одновременных коннектов Baikonur сервера к SQL-серверу может быть в десятки раз меньше, поэтому возникает реальная возможность сэкономить средства
при реализации крупного корпоративного проекта.
В том случае, когда количество установленных рабочих мест в системе с архитектурой клиент-сервер переваливает за несколько десятков, у администратора системы начинаются серьезные проблемы с администрированием
такого количества рабочих мест. Как правило, корпоративная информационная система находится в постоянном развитии, и существует необходимость следить за тем, чтобы на все рабочие места была установлена свежая верия клиентского приложения, вовремя переинсталлировать ее и т.д. При увеличении рабочих мест свыше сотни становится физически невозможным вовремя обновлять клиентские приложения, а при наличии еще и удаленных рабочих мест администрирование системы превращается в вечную головную боль технического персонала предприятия. Следует также учитывать стоимость такого администрирования в масштабах предприятия, наличие нерабочего времени для каждого рабочего места (технический перерыв), возможную неработоспособность всей системы в случае работы несовместимых версий клиентского приложения и т.п.
В случае применения Baikonur все эти проблемы решаются много проще. Как уже говорилось, информационная система в трехзвенной архитектуре с использованием Baikonur не слишком критична к версии и типу Internet-браузера и будет корректно работать даже в случае разных версий браузеров и разных операционных систем. Новая версия приложений переустанавливается только на серверах приложений, что требует в сотни раз меньше усилий, чем в случае переустановки их на клиентских рабочих местах.
Функциональная расширяемость системы на основе Baikonur сервера.
В Baikonur Web App Server реализована технология динамической смены протоколов. Одним из наиболее употребимых протоколов Baikonur является интернетовский протокол http 1.1. Однако, технология динамической смены протоколов позволяет управлять информационными потоками, предназначенными не только для пересылки гипертекстовых страничек по Internet. Это могут быть потоки информации, предназначенные для передачи голосовой информации, почтовых сообщений, просто файлов, видеоинформации, мониторинговой информации, результатов измерений и т.д. Можно использовать уже принятый соответствующий стандарт или придумать и реализовать собственный. Такая беспрецедентная возможность расширения функциональности системы абсолютно нехарактерна для клиент-серверных продуктов прежнего поколения.
Секретность и безопасность. В клиент-серверных системах прежнего поколения принято, что клиентское приложение имеет доступ к метаданным системы. Практика показывает, что при такой схеме работы весьма сложно обеспечить стопроцентную безопасность всей информационной системы. Кроме того, только немногие клиент-серверные продукты обеспечивают шифрование данных на лету при передаче их по сети.
В Baikonur Enterprise Web Application Server реализован стандарт SSL (Secure Socket Layer) - вся передаваемая по сети информация шифруется одним из распространенных алгоритмов шифрования. В самой старшей версии существует возможность замены алгоритма шифрования, что иногда (в реализации закрытых внутренних проектов) бывает необходимо.
Вопросы секретности и безопасности данных при практической реализации корпоративной информационной системы заключаются не только в том требовании, чтобы вся информация, передаваемая по модемной линии или по сетевому кабелю, надежно шифровалась. В Baikonur-системе можно легко обеспечить ведение записей о каждом произошедшем факте доступа в систему, причем при необходимости можно протоколировать любую попытку взлома системы. Существует также возможность написания модуля (запускаемого приложения), предпринимающего немедленные адекватные действия в экстремальной для системы ситуации.
Каждый клиент при помощи своего браузера видит динамически формируемую страничку.Эта страничка формируется заново каждый раз при новом коннекте. Пользователь в стандартном случае не имеет никакого доступа к метаданным или другой системной информации. Более того, для каждого пользователя в соответствии с его уровнем доступа или в соответствии с какими-либо другими соображениями можно формировать свою версию того, что он увидит на экране своего монитора.
Интегрирование самых различных систем в единую систему. Существует очевидная тенденция для всех основных производителей программного обеспечения выпускать Internet/Intranet версию своего программного обеспечения. С учетом этой тенденции появляется возможность объединять программные пакеты от большинства производителей в единую систему, дописывая недостающие части в виде exe-модулей, запускаемых под управлением Baikonur-сервера.
Основные принципы работы
Память переводов представляет собой базу данных, хранящую языковые пары, и определенный механизм поиска. Несмотря на то, что различные профессиональные среды перевода, такие как "Translator'sWorkbench" фирмы Trados, "Transit" фирмы Star, "DejaVu" фирмы Atril, имеют, по-видимому, различную реализацию этого механизма ("по-видимому", поскольку алгоритмы не придаются огласке), общая идея становится ясной после изучения примеров. Поэтому с примеров и начнем.
Пусть в исходном тексте встречаются следующие фразы:
"Температура регулируется поворотом ручки."
"Температура регулируется поворотом ручки по часовой стрелке."
"Напор воды регулируется поворотом ручки по часовой стрелке."
Если сегментация выполняется по предложениям, то каждая из приведенных фраз попадет в отдельный сегмент. Пусть первый сегмент был переведен человеком следующим образом:
"The temperature can be adjusted by turning the knob."
Языковая пара, состоящая из исходного и переведенного сегментов, заносится в память переводов. Когда переводчик доходит до второй фразы примера, система определяет сходство и выводит на экран следующую информацию: таблица 2.
Таблица 2
| Текущий сегмент | Температура регулируется поворотом ручки по часовой стрелке |
| Найденный сегмент | Температура регулируется поворотом ручки |
| Перевод | The temperature can be adjusted by turning the knob |
| Степень сходства | ~70% |
Теперь переводчик имеет возможность частично воспользоваться уже сделанным переводом, учтя различия:
"The temperature can be adjusted by turning the knob clockwise."
После того, как сегмент, соответствующий второй фразе примера помечается как переведенный, в памяти переводов появляется еще одна языковая пара. Тем самым, когда дело доходит по третьей фразы, система уже имеет возможность показать переводчику два похожих варианта: таблица 3.
Таблица 3
| Текущий сегмент | Напор воды регулируется поворотом ручки по часовой стрелке |
| Найденная языковая пара 1 | Температура регулируется поворотом ручки по часовой стрелке |
| The temperature can be adjusted by turning the knob clockwise | |
| Степень сходства | ~65% |
| Текущий сегмент | Напор воды регулируется поворотом ручки по часовой стрелке |
| Найденная языковая пара 2 | Температура регулируется поворотом ручки |
| The temperature can be adjusted by turning the knob | |
| Степень сходства | ~40% |
Воспользовавшись, к примеру, первым из предложенных вариантов, переводчик быстро расправляется с оставшейся частью фразы:
"The water head can be adjusted by turning the knob clockwise."
Эффективность работы памяти переводов во многом определяется тем, насколько удачно решены следующие задачи: сегментация; обработка специальных символов и форматирующей информации.
Очевидно, что с увеличением размера сегментов будет уменьшаться число полных совпадений (и увеличиваться число частичных), что сильно повысит ресурсоемкость процедур поиска и потребует от переводчика значительных усилий в изучение предоставленных ему в качестве вариантов перевода языковых пар.
С другой стороны, уменьшение размера сегментов сделает их малопригодными для повторного использования, поскольку сильно возрастет влияние контекста на перевод. Оптимальной единицей сегментации чаще всего оказывается фрагмент предложения, ограниченный знаками препинания. Во избежание ошибочной сегментации по точкам внутри аббревиатур и других подобных случаев используют регулярные выражения и списки исключений. Вторая проблема обусловлена тем, что в тексте кроме букв зачастую присутствуют иные символы, как то: маркеры внедренных в документ объектов, закладки, перекрестные ссылки, переключатели свойств шрифта. Все эти инородные элементы в ряде случаев могут повлиять на перевод. Например, выделенное курсивом слово может при переводе быть взято в кавычки и попасть в результирующий текст в неизменном виде. Для управления поведением анализатора в таких ситуациях во многих программных продуктах предусмотрены специальные настройки, в том числе, основанные на применении регулярных выражений.
Основы разработки DLL
Разработка динамических библиотек не представляет собой некий сверхсложный процесс, доступный лишь избранным. Если вы достаточно хорошо знакомы с разработкой приложений на Object Pascal, то вам не составит особого труда научиться работать с механизмом DLL. Итак, рассмотрим те особенности создания DLL, которые вам необходимо знать, а в завершении статьи разработаем свою собственную библиотеку.
Как и любой другой модуль, модуль динамической библиотеки имеет фиксированный формат. Взгляните на листинг, представленный ниже. library MyFirstDLL; uses SysUtils, Classes, Forms, Windows; procedure HelloWorld(AForm : TForm); begin MessageBox(AForm.Handle, Hello world!', DLL Message Box', MB_OK or MB_ICONEXCLAMATION); end; exports HelloWorld; begin end.
Первое, на что следует обратить внимание, это ключевое слово library, находящееся вверху страницы. Library определяет этот модуль как модуль библиотеки DLL. Далее идет название библиотеки. В нашем примере мы имеем дело с динамической библиотекой, содержащей единственную процедуру: HelloWorld. Причем обратите внимание, что данная процедура по структуре ничем не отличается от тех, которые вы помещаете в модули своих приложений. Ключевое слово exports сигнализирует компилятору о том, что перечисленные ниже функции и/или процедуры должны быть доступны из вызывающих приложений (т.е. они как бы "экспортируются" из библиотеки). Подробнее о механизме экспорта мы поговорим чуть позже.
И, наконец, в конце модуля можно увидеть ключевые слова begin и end. Внутри данного блока вы можете поместить код, который должен выполняться в процессе загрузки библиотеки. Достаточно часто этот блок остается пустым.
Как уже говорилось выше, все процедуры и функции, помещаемые в DLL, могут быть разделены на две группы: экспортируемые (вызываемые из других приложений) и локальные. Естественно, внутри библиотеки также могут быть описаны классы, которые в свою очередь содержат методы, но в рамках данной статьи я не буду на этом останавливаться.
Описание и реализация процедур и функций, вызываемых в пределах текущей DLL, ничем не отличаются от их аналогов в обычных проектах-приложениях. Их специфика заключается лишь в том, что вызывающая программа не будет иметь к ним доступа. Она просто не будет ничего знать об их существования, так же, как одни классы ничего не знают о тех методах, которые описаны в секции private других классов.
В дополнение к процедурам и функциям, DLL может содержать глобальные данные, доступ к которым разрешен для всех процедур и функций в библиотеке. Для 16-битных приложений эти данные существовали в единственном экземпляре независимо от количества загруженных в оперативную память программ, которые используют текущую библиотеку. Другими словами, если одна программа изменяет значение глобальной переменной a на 100, то для всех остальных приложений a будет значение 100. Для 32-битных приложений это не так. Теперь для каждого приложения создается отдельная копия глобальной области данных.
Особенности архитектуры
Если раньше система реального времени рассматривалась нами как один процесс (с точки зрения ресурсов), то распределенные СРВ представляют уже набор взаимодействующих процессов.
Специфика заключается в том, что отлаживаемое приложение может быть распределено на нескольких платформах с разными процессорами, поэтому эффективность отладчика зависит от: наличия на каждом компоненте системы агента отладки; способности менеджера работать со всеми процессорами системы; возможности агентов отладки осуществлять связь между собой и с менеджером.
Кроме того, если система состоит из большого числа компонент, использование двухуровневой архитектуры "менеджер-агент" становится неэффективным, поскольку менеджер не сможет обработать в надлежащее время информацию от агентов. В этом случае целесообразно использовать многоуровневую структуру, в которой компоненты, объединенные по своим функциональным возможностям, представляют некоторые подсистемы, которыми управляют соответствующие менеджеры, являющиеся агентами на следующем уровне предложенной иерархии.
При включении в систему новой платформы необходимо, чтобы менеджер имел возможность осуществлять связь с агентом. Для этого к набору исходных текстов менеджера добавляется файл, содержащий функции взаимодействия с агентом. Здесь возможны следующие варианты: Файл описания платформы требует компиляции и сборки вместе с остальными исходными текстами.
Существенный недостаток такого подхода в том, что менеджер или какую-либо его часть придется пересобирать. Файл описания интерпретируется внутренними средствами менеджера.
В [17] описан отладчик Panorama, платформо-зависимые черты, которого вынесены в отдельные файлы: файл описания платформы (агента) и tcl-скрипт, в котором описаны необходимые функции. Таким образом, имея встроенный tcl-интерпретатор, Panorama способен работать с новой платформой без пересборки менеджера. Архитектура этого отладчика приведена на рис.7.

Рис. 7. Отладчик Panorama
В случае, если один агент обслуживает несколько менеджеров, целесообразно организовать промежуточное звено, в которое вынести все платформо-зависимые черты менеджеров. Такой подход реализован в среде разработки ПО реального времени TORNADO (система VxWorks). Он заключается в том, что на целевой стороне имеется универсальный агент (target agent), осуществляющий связь со средствами разработки ПО посредством целевого сервера (target server). В этом случае, во-первых, все клиенты работают с одним сервером (и, соответственно, с одним агентом) и, во-вторых, они имеют возможность обмениваться данными между собой, используя целевой сервер.
Особенности отладки в системах реального времени
Отладка в СРВ направлена на обнаружение и исправление ошибок в прикладном коде. Она является одним из этапов кросс-разработки, схему которой можно представить следующим образом. Разработка приложения ведется как минимум на двух машинах: инструментальной и целевой. На инструментальной платформе происходит написание исходного текста, компиляция и сборка. На целевой - загрузка приложения, его тестирование и отладка.
Ввиду того, что целевая платформа, как правило, обладает более ограниченными ресурсами, чем инструментальная, отладка распределенных систем реального времени может быть двух видов.
Первый из них - имитация архитектуры целевой платформы, то есть возможность отладки целевых программных средств без использования самой платформы. Подобная имитация, как правило, не дает возможности провести подробное и полное тестирование ПО. Поэтому, такой тип отладки применяется только в случае отсутствия целевой платформы.
Второй способ - удаленная отладка (кросс-отладка). Кросс-отладка позволяет использовать ресурсы инструментальной системы при изучении поведения некоторого процесса в целевой системе.
Эффективность удаленной отладки зависит от типа связи инструментальной и целевой машин, а также от поддержки средств отладки со стороны целевой архитектуры.
Ключевым требованием к средствам отладки является возможность наблюдать и анализировать весь процесс выполнения отлаживаемых задач, а также системы в целом. В данной работе рассматриваются два метода отладки: активная отладка и мониторинг.
Суть активной отладки состоит в том, что отладчик имеет право останавливать выполнение задачи или всей системы, начинать или продолжать выполнение с некоторого адреса, отличного от точки останова, изменять значения переменных и регистров, и.т.д. Недостаток этого метода заключается в том, что отладчик может вносить серьезные сбои в нормальную работу системы в связи с устанавливаемыми временными ограничениями. Этого можно избежать, остановив некоторую группу задач или всю систему целиком, о чем будет подробнее сказано ниже. Преимущество метода состоит в возможности корректировать поведение задачи в процессе ее выполнения.
Под мониторингом понимается сбор данных о задаче (значения регистров, переменных, и.т.д) или о системе в целом (стадии выполнения задач, происходящие события, и.т.д).
Осуществлять сбор данных помогает псевдо-агент (набор инструкций, встроенных в код задачи). Обычно его добавляют на этапе проектирования. Простой пример псевдо-агента - вызов assert, позволяющий вести диагностику работы задачи.
В процессе мониторинга отладчик практически не вмешивается в работу системы, обеспечивая нормальное ее функцирование, но вместе с тем не имеет возможности влиять на ход выполнения отлаживаемого приложения.
От языковых пар к языковым звездам
Нередкой является ситуация, когда перевод приходится осуществлять не только с языка A на язык B, но и, наоборот, с языка B на язык A. Одна и та же память переводов будет одинаково полезна в обоих случаях, поскольку содержит максимально синхронизированные графы сегментов на языке A и на языке B. Однако стоит нам усложнить задачу и предположить необходимость перевода между несколькими языками, как полезность единой памяти переводов заметно падает. Действительно, если перевод осуществлялся с языка A на языки B и C, то в памяти не будет храниться соответствия между сегментами на языках B и C. Как же обеспечить подобную возможность?
Разумным решением могло бы явиться использование некоторого промежуточного языка X, на который осуществлялся бы перевод, а затем, вторым этапом, выполнялся бы перевод с языка X на целевой язык. В подобном случае все языковые пары в памяти переводов состояли бы из сегмента языка X и сегмента одного из целевых (либо исходных) языков. Тут имеются, однако, подводные камни. Во-первых, как мы уже убедились, пересечение языковых пар не всегда бывает изоморфным, следовательно, не все языковые пары в памяти переводов будут содержать перевод на язык X. Очевидно, такие пары будут бесполезны. Во-вторых, при переводе всегда имеется опасность потери смысла: двойной перевод значительно увеличивает эту опасность.
Каким же должен быть этот гипотетический промежуточный язык X, чтобы им было целесообразно воспользоваться? Его свойства вытекают из двух названных проблем. Во-первых, этот язык должен обеспечивать изоморфное пересечение для любого другого языка. Нарушение изоморфизма (по крайней мере, в родственных языках) обусловлено в значительной степени различием синтаксических правил, приводящим к разному порядку членов предложения, а также к различию форм одного и того же слова. Отсюда следует, что язык X должен быть инвариантен к порядку слов и как-то учитывать их формы в исходном языке. Во-вторых, он должен быть в состоянии передать смысл фразы на любом языке, следовательно- включать в себя специфические понятия всех существующих человеческих языков.
Если такой универсальный язык будет найден, то память переводов можно будет организовать не на основе языковых пар, а на основе языковых звезд, где в центре находится сегмент на языке X, на лучах- варианты переводов его на другие языки. При значительном объеме перевода между большим количеством языков дополнительные затраты на удвоенную работу переводчика с лихвой окупятся гибким механизмом памяти переводов, значительно упрощающим многоязычный перевод.
Осталось только найти язык X. И такой язык существует! Это универсальный сетевой язык UNL (UniversalNetworkingLanguage), предложенный Институтом Развития Обучения (InstituteofAdvancedStudies- IAS) при Университете Объединенных Наций (UnitedNationsUniversity- UNU). Им мы и воспользуемся для дальнейшего развития модели памяти переводов.
От маленьких проектов к средним проектам – было два программиста, а стало восемь.
По моим наблюдениям, основная масса проектов, которые делают Российские оффшорные фирмы, обычно длятся не более двух месяцев с участием одного или двух программистов. Многие фирмы даже умышленно не берут заказы среднего размера, рассчитанные на полгода или год с участием 6 или 10 программистов. Некоторые фирмы решаются на такие проекты, но им приходится проводить реструктуризацию организации для того, что бы было возможно выполнять такие заказы.
Общеизвестно, что понятие “проект” подразумевает под собой процесс, имеющий точные временные ограничения, т.е. дату начала и дату окончания. Ключевую роль в любом проекте играет так называемый Руководитель Проекта (Project Manager). Естественно, что Руководитель Программного Проекта (Software Project Manager) имеет специфические особенности, связанные с отраслью создания программного обеспечения. В этой статье я постараюсь рассказать о функциях руководителя средних проектов, а также о стадиях, через которые должен пройти проект под его руководством. В статье я делаю ставку на объектно-ориентированные проекты и упускаю из виду такие вещи как тестирование и управление рисками.
На мой взгляд, руководитель проекта должен обладать знанием технологий, на которых будет реализован проект. Представим, что во главе проекта стоит руководитель, который имеет только общее представление о работе своих подчиненных - программистов. В лучшем случае вы получите надзирателя, который всегда полагается на честность программистов, а в худшем - нахлебника, которому будут «пудрить мозги» «ушлые» программисты и проект будет, мягко говоря, отставать от графика, а, скорее всего, вообще не придет к стадии завершения. По какой причине я выставил такие требования к руководителю проекта, будет видно из последующего материала. Дело в том, что один квалифицированный программист с большим опытом работает в десять раз эффективнее начинающего, так утверждает Брукс или Йордан, но, как правило, фирмы не торопятся нанимать высокооплачиваемых программистов. В сложившейся ситуации намного эффективнее из такого специалиста сделать руководителя проекта и дать ему в подчинение не таких дорогостоящих программистов. Но ни в коем случае не нужно делать наоборот, так как забивать гвозди микроскопом это очень дорогое и не эффективное занятие. Другими словами, руководитель проекта должен иметь очень высокую квалификацию, а не мешать своими неразумными указаниями слишком умному исполнителю.
Существует масса книг зарубежных авторов на тему Software Project Management, которые ориентированы на большие проекты и, естественно, управление такими проектами отличаются от управления средними проектами. В этой статье я постарался выделить конструктивные моменты деятельности и обязанностей руководителя именно среднего проекта.
Открытая архитектура
Архитектура Flora/C+ полностью прозрачна и открыта для разработчика. Ему доступны все системные элементы, необходимые для разработки приложений. Основной элемент архитектуры. дерево взаимодействующих объектов (Object Tree) содержит не только прикладные объекты разрабатываемой пользователем программной системы, но также. все системные объекты: устройства ввода/вывода, стартовую панель, буфер обмена данными, системные переменные, функции и библиотеки, содержащие системные и прикладные объекты Flora/C+, с помощью которых строятся приложения и т.. Более того, дерево объектов содержит также и все инструментальные приложения самой системы программирования Flora/C+, в том числе: Дизайнер, Отладчик, Редактор графических объектов и другие, также разработанные в технологии Flora/C+ на базе одних и тех же системных и прикладных библиотечных объектов. Разработчик может также использовать встроенный язык программирования F++, который синтаксически подобен C++ и Java и включает стандартный набор объектных расширений языка, конструкции структурного программирования (как if, switch, for, while), все операторы языка C++ и т.д.
Отладочные действия
Существует набор базовых действий, позволяющих пользователю осуществлять контроль за выполнением отлаживаемой задачи. Эти действия можно классифицировать следующим образом: предварительные действия отладчика; прерывание выполнения задачи; получение информации; продолжение/изменение выполнения задачи.
1) Предварительные действия отладчика загрузка модуля на целевой стороне; запуск нужной задачи; если задача была запущена средствами системы, то присоединение к ней (в этом случае выполнение задачи останавливается и становится возможным производить отладочные действия); переключение между задачами.
Отладчик также выполняет и обратные действия, то есть отсоединение от задачи, прекращение ее выполнения и выгрузка соответствующего модуля.
2) Прерывание выполнения задачи
Как правило, выполнение задачи может быть прервано в результате того, что произошло одно из следующих событий: Достигнута точка прерывания.
Точки прерывания бывают двух видов: программные и аппаратные. Установка программной точки прерывания состоит в том, что запоминается инструкция, расположенная по тому адресу, где будет находиться точка прерывания, затем по этому адресу прописывается так называемая "break"-инструкция, после обработки которой процессором генерируется некоторое исключение (trap exception). Обработчик этого исключения сохраняет регистры задачи, меняет инструкцию точки прерывания на настоящий код и передает управление менеджеру. Недостаток программных точек прерывания в том, что соответствующий адрес должен находиться в той области памяти, куда разрешена запись.
Аппаратная точка прерывания не требует модификации памяти, так как ее адрес хранится в специальном регистре (debug register, DR), который просматривается процессором при выполнении очередной инструкции. Если происходят действия, заложенные в контрольный регистр (например, выполнение по заданному адресу или чтение/запись в область, адресуемую значением DR), то процессор генерирует соответствующее прерывание, обработав которое, отладчик получает необходимую информацию.
Отладчик предоставляет пользователю возможность установки точки прерывания на начало некоторой строки исходного текста, на точку входа определенной функции или на конкретный адрес.
Помимо этого, отладчик отличает точки прерывания, поставленные им, а также (в многозадачных системах) имеет возможность устанавливать и обрабатывать точки прерывания, специфичные для данного множества задач. Это означает, что если задача не входит в такое отлаживаемое множество, то точка прерывания игнорируется. Помимо работы с точками прерывания, устанавливаемыми на конкретный адрес, отладчик работает с так называемыми прерываниями доступа (access breakpoints), используемыми для определения момента доступа к некоторой области памяти, и прерываниями наступления событий (event detection), которые срабатывают, когда происходит соответствующее событие. Используется режим пошаговой отладки. Существует много вариантов степени детализации выполнения. В частности, остановка после выполнения строки исходного текста или остановка после выполнения каждой ассемблерной инструкции (с заходом в вызываемые функции или с их пропуском). Отладчик может использовать этот режим в служебных целях, например, при установленном прерывании выполнения при изменении данных (watchpoint). В этом случае после исполнения очередной инструкции надо проверять значение того выражения, на котором стоит точка прерывания. Перехвачена исключительная ситуация. Если в процессе выполнения отлаживаемой задачи возникла исключительная ситуация (например, деление на 0), то отладчик должен корректно ее обработать и сообщить пользователю. Получен сигнал прерывания от пользователя. Отладчик предоставляет пользователю возможность в любой момент остановить выполнение программы (например, введя соответствующий символ). При получении сигнала останова отладчик может остановить текущую отлаживаемую задачу, остановить выполнение некоторой группы задач и остановить всю систему. Такой механизм дает возможность применять средства активной отладки без опасения вызвать новые ошибки, связанные со спецификой СРВ, поскольку система или набор задач, которые могут повлиять на отлаживаемую, будут остановлены, и временные соотношения их выполнения нарушены не будут.
Подобный подход реализован в отладчике X-ray (Microtec Division, целевая система VRTX).
3) Получение информации Когда задача остановилась, становится возможным осуществлять сбор различных данных, которые могут помочь при локализации логических ошибок в программе.
Просмотр содержимого стека. Эта команда дает возможность увидеть, как задача попала в текущее положение. Каждый кадр стека содержит данные, связанные с вызовом некоторой функции, включая ее аргументы, локальные переменные и адрес точки вызова. Просмотр таблицы символов. Используя отладчик, можно получать доступ к информации о символах (имена переменных, функций и типов), определенных в задаче. Эта информация состоит из имени, типа и адреса соответствующей переменной или функции. Просмотр исходных файлов. Пользователь может выборочно смотреть исходный текст программы, задавая номера строк, имена функций или некоторый адрес. Просмотр данных. Отладчик способен получать и пересылать пользователю значение любой переменной или функции, доступной отлаживаемой задаче, а также содержимое регистров, памяти и дизассемблированный код. Кроме того, у пользователя может возникнуть необходимость осуществить в процессе сеанса отладки вызов некоторой функции. Для поддержки этого существуют различные способы, например, можно передать соответствующий запрос агенту отладки, и тот запустит требуемую функцию либо в контексте отлаживаемой в данный момент задачи, либо в некотором специальном контексте. В GDB (GNU debugger, Free Software Foundation) реализован другой механизм, суть которого заключается в том, что все предварительные действия (установка точки выполнения, и.т.д.) производятся на инструментальной стороне, а агенту передается запрос на выполнение с текущего адреса.
4) Продолжение/изменение выполнения Особенностью активной отладки является возможность изменения выполнения задачи.
Изменение данных. Отладчик имеет возможность изменять значения переменных, содержимое регистров и памяти. Это позволяет корректировать выполнение задачи, проверяя предположения об ошибках в ее коде. Продолжение выполнения задачи с любого адреса. Пользователь может потребовать продолжить выполнение задачи с другого адреса (например, обходя критический участок кода). Продолжение выполнения задачи до некоторого адреса. В этом случае ставится временная точка прерывания на нужный адрес, и задача выполняется, пока этот адрес не будет достигнут.
Как и в случае с обычной точкой прерывания, отладчик обеспечивает установку временной точки прерывания на начало строки исходного текста, на конкретный адрес или на точку входа некоторой функции. Однако, помимо этого отладчик может ставить временную точку прерывания на адрес возврата текущей функции, реализуя выполнение задачи вплоть до завершения этой функции. Механизм установки временной точки прерывания используется и в режиме пошаговой отладки. Тогда точка прерывания ставится на следующую исполняемую инструкцию или (в случае отладки без захода в вызываемые функции) на инструкцию, следующую за вызовом функции. Возврат из функции. Может возникнуть ситуация, когда пользователю понадобится завершить выполнение функции с определенным возвращаемым значением. В этом случае отладчик выполняет следующие действия:
Приведение заданного пользователем значения к типу возвращаемого значения этой функции. Восстановление сохраненных регистров. Установка возвращаемого значения в требуемую область памяти/регистр. Установка указателя стека на предыдущий кадр. Установка точки выполнения программы на адрес возврата заданной функции. Уничтожение текущего кадра стека.
Описывая отладочные действия, стоит упомянуть об инструментальной системе ЭСКОРТ ([27]), созданной в Научно-исследовательском институте системных исследований РАН как средство повышения производительности труда профессиональных программистов. Основу ЭСКОРТа составляет интегрированная система редактирования - компиляции - выполнения. Программы в ЭСКОРТе имеют нетекстовое представление. Более точно, все программные объекты представлены как объекты базы данных. Средствами БД ЭСКОРТа реализовано хранение предыдущих состояний объектов (и, в частности, значений переменных), откатка, "откатка откатки" и т.п., что позволяет дать в руки программисту мощные средства контролируемого выполнения (пошаговое, с контролем значений переменных, обратное и т.д.). Правда, на сегодняшний день, для современных систем реального времени, средства, предлагаемые в рамках ЭСКОРТа, представляются слишком тяжеловесными (хотя и весьма перспективными).
Отображение графических и мемо-полейв отчетах
QuickReport позволяет создавать отчеты с использованием любых типовданных. Если вместо определения DataSource создать обработчик события OnNeedData,можно с помощью QuickReport напечатать любые данные, меняя свойства компонентовTQRLabel, что во многих случаях используется для печати произвольной информации(иногда не имеющей отношения к базам данных).
QuickReport не имеет собственного компонента для отображения графическихполей. Вместо этого можно использовать стандартные компоненты Timage илиTDBImage (рис. 7).

Рис. 7. Использование TDBImage для отображения графических полей
Следует отметить, что графические поля баз данных может печатать далеконе всякий профессиональный генератор отчетов. Например, ReportSmith, входившийв комплект поставки ряда продуктов Borland, может печатать графическиеизображения, не имеющие непосредственного отношения к данным (например,взятые из файлов формата *.bmp), но отнюдь не графические поля таблиц.
Для отображения мемо-полей можно использовать компонент TQRDBText. Еслисодержимое мемо-поля, отображаемого с помощью этого компонента, не умещаетсяв одну строку, высота этого компонента (и высота содержащего его компонентаTQRBand) в режиме предварительного просмотра и при печати отчета увеличиваетсятаким образом, чтобы внутри компонента TQRDBText уместилось все содержимоеmemo-поля. Чтобы избежать наложения получившегося текста на другие элементыотчета при его печати, можно просто размещать компоненты TQRDBText, отображающиеmemo-поля, в нижней части TQRBand (рис 7).

Рис. 7. В левой нижней части данного отчета компонент TQRDBTextотображает memo-поле

Рис. 8. А вот так выглядят memo-поля в отчете
Если таких memo-полей несколько и они должны быть размещены друг поддругом, можно использовать несколько компонентов TQRBand одного типа дляодной записи. В этом случае печататься они будут в порядке их создания.
Отслеживание изменений
Теперь вы, возможно, захотите узнать, какие именно изменения внес другой разработчик в файл `httpc.c'. Чтобы увидеть журнальные записи для данного файла, можно использовать команду cvs log: $ cvs log httpc.c RCS file: /usr/src/master/httpc/httpc.c,v Working file: httpc.c head: 1.8 branch: locks: strict access list: symbolic names: keyword substitution: kv total revisions: 8; selected revisions: 8 description: The one and only source file for trivial HTTP client ---------------------------- revision 1.8 date: 1996/10/31 20:11:14; author: jimb; state: Exp; lines: +1 -1 (tcp_connection): Cast address stucture when calling connect. ---------------------------- revision 1.7 date: 1996/10/31 19:18:45; author: fred; state: Exp; lines: +6 -2 (match_header): Make this test case-insensitive. ---------------------------- revision 1.6 date: 1996/10/31 19:15:23; author: jimb; state: Exp; lines: +2 -6 ... $
Большую часть текста здесь вы можете игнорировать; следует только обратить внимание на серию журнальных записей после первой строки черточек. Журнальные записи выводятся на экран в обратном хронологическом порядке, исходя из предположения, что недавние изменения обычно более интересны. Каждая запись описывает одно изменение в файле, и может быть разобрано на составные части так: `revision 1.8'
Каждая версия файла имеет уникальный "номер редакции". Номера ревизии выглядят как `1.1', `1.2', `1.3.2.2' или даже `1.3.2.2.4.5'. По умолчанию номер 1.1 -- это первая редакция файла. Каждое следующее редактирование увеличивает последнюю цифру на единицу. `date: 1996/10/31 20:11:14; author: jimb; ...'
В этой строке находится дата изменения и имя пользователя, зафиксировавшего это изменение; остаток строки не очень интересен. `(tcp_connection: Cast...'
Это, очевидно, описание изменения.
Команда cvs log может выбирать журнальные записи по дате или по номеру редакции; за описанием деталей обращайтесь к руководству.
Если вы хотите взглянуть на соответствующее изменение, то можете использовать команду cvs diff.
Например, если вы хотите увидеть, какие изменения Фред зафиксировал в качестве редакции 1.7, используйте такую команду: $ cvs diff -c -r 1.6 -r 1.7 httpc.c
Перед рассмотрением того, что нам выдала эта команда, опишем, что означает каждая ее часть.
| -c | Задает использование удобочитаемого формата выдачи изменений. (Интересно, почему это не так по умолчанию). |
| -r 1.6 -r 1.7 | Указывает CVS, что необходимо выдать изменения, необходимые, чтобы превратить редакцию 1.6 в редакцию 1.7. Вы можете запросить более широкий диапазон изменений; например, -r 1.6 -r 1.8 отобразит изменение, сделанные Фредом, и изменения, сделанные вами чуть позже. (Вы также можете заказать выдачу изменений в обратном порядке -- как будто бы они были отменены -- указав номера редакций в обратном порядке: -r 1.7 -r 1.6. Это звучит странно, но иногда полезно.) |
| httpc.c | Имя файла для обработки. Если вы не укажете его, CVS выдаст отчет обо всем каталоге. |
Остальное состоит из двух "ломтей" (hunk), каждый из которых начинается со строки из звездочек. Вот первый "ломоть": *************** *** 62,68 **** } ! /* Return non-zero iff HEADER is a prefix of TEXT. HEADER should be null-terminated; LEN is the length of TEXT. */ static int match_header (char *header, char *text, size_t len) --- 62,69 ---- } ! /* Return non-zero iff HEADER is a prefix of TEXT, ignoring ! differences in case. HEADER should be lower-case, and null-terminated; LEN is the length of TEXT. */ static int match_header (char *header, char *text, size_t len) Текст из более старой редакции находится после строки *** 62,68 ***; текст новой редакции находится после строки --- 62,69 ---. Пара цифр означает показанный промежуток строк. CVS показывает контекст вокруг изменений и отмечает измененные строки символами `!'. Таким образом вы видите, что одна строка из верхней половины была заменена на две строки из нижней. Вот второй "ломоть": *************** *** 76,81 **** --- 77,84 ---- for (i = 0; i < header_len; i++) { char t = text[i]; + if ('A' <= t && t <= 'Z') + t += 'a' - 'A'; if (header[i] != t) return 0; } Здесь описывается добавление двух строк, что обозначается символами `+'. CVS не выводит старый текст -- это было бы избыточно. Для описания удаленных строк используется подобный формат. Как и выход команды diff, выход команды cvs diff обычно называется "заплатой" (patch), потому что разработчики традиционно использовали этот формат для распространения исправлений и небольших новый возможностей. Достаточно читабельна, заплата содержит достаточно информации, чтобы применить изменения, которые она содержит, к текстовому файлу. В действительности, команда patch в среде UNIX делает с заплатами именно это.
Пакет доступа к фактам
Пакет server.factdao на рис. 2.6 отвечает за работу с фактами для разных типов источников данных. За основу берется интерфейс FactDAOInteface, задающий принципы работы с фактами. Его необходимо реализовать для всех типов источников данных, которые будут подключены к системе. При реализации данного интерфейса в случае, когда некоторые источники данных имеют общие черты, следует использовать Template Method для увеличения степени повторного использования кода.

Рис. 2.6 Доступ к фактам
Пакет источников данных
Пакет server.datasource на рис. 2.5 обеспечивает связку между источниками данных и фактами. Другими словами, здесь описывается, в каком источнике данных находится какой факт. Вводится понятие картриджа (класс FactCarttridge), представляющего источник данных, в котором хранятся факты. Для работы с конкретным типом источником данных картридж использует интерфейс FactDAOInterface. Данный подход позволяет серверу приложений, с одной стороны, хранить свои факты в разных источниках данных, а с другой, не заботиться клиентскому приложению о том, как они хранятся и как расположены физически, что облегчает клиентскую часть системы.
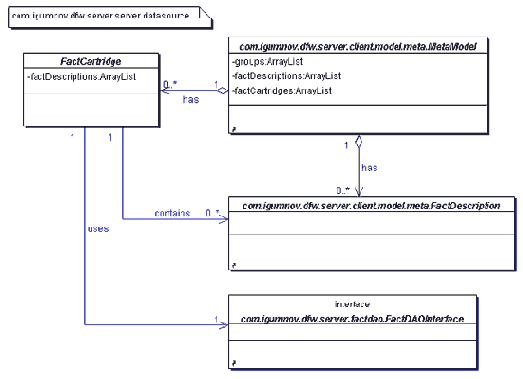
Рис. 2.5 Источник данных
Пакет ядра
Пакет server.kernel на рис. 2.7 представляет собой набор заводов FactDAOFactory, MetaFactory и SecurityFactory, управляющих моделями пакетов model.fact, model.meta и model.security, которые были описаны выше. Классы AbstractMetaSource и AbstractFactSource в своей работе используют безопасность, т.е. пользуются услугами SecurityFactory. Основная функциональная нагрузка ядра ложится на классы AbstractFactSource, AbstractMetaSource и AbstractSecuritySource, но процесс управления объектами моделей model.fact, model.meta и model.security делегируется классам FactDAOFactory, MetaFactory и SecurityFactory с использованием шаблона Adapter.
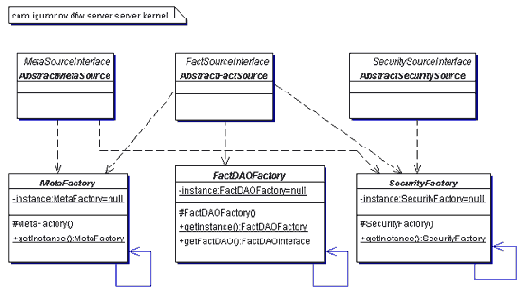
Рис. 2.7 Ядро системы
Пакет контроллер
Пакет client.controller на рис. 3.5 содержит интерфейс Command, который описывает стандартный способ инициирования команд, наследуемых от этого интерфейса. В этом пакете содержится классы, содержащие бизнес-логику, которая манипулирует моделью.
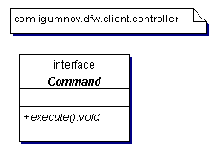
Рис. 3.5 пакет контроллер
Пакет модель
Пакет client.model на рис. 3.3 содержит классы Модели, которые отображаются классами Вида из пакета client.view. В случае, когда есть уже готовый инструментарий для построения приложения, приходится адаптировать имеющиеся Модели из пакетов client.model.fact, client.model.meta и client.model.security с помощью шаблона Adapter к имеющимся моделям.
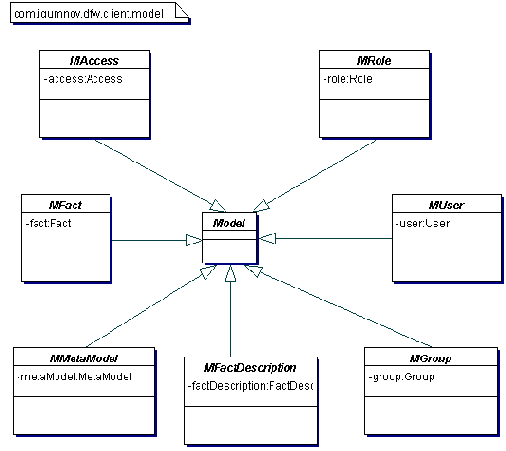
Рис. 3.3 Пакет модель
Пакет посредник
Пакет client.mediator на рис. 3.4 содержит класс Mediator, в роли которого может выступать главный класс приложения с методом main(). Обычно в сложных клиентских приложениях присутствует несколько расширяющих его классов.
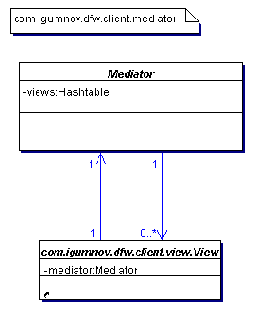
Рис. 3.4 Пакет посредник
Пакет вид
Пакет client.view на рис. 3.2 представляет собой набор классов со ссылками на объекты из пакета client.model. Другими словами, Вид строится на основании Модели. Для того, чтобы ослабить их сцепленность (coupling), взаимосвязь между связанными Видами, используется ссылка на посредник класс Mediator, которому делегируются события, приходящие из внешнего мира от пользователя. В случае, когда есть уже готовый инструментарий для построения приложения, следует применять шаблон Adapter при адаптации имеющихся компонентов Видов. В случае, когда приходится самостоятельно реализовывать обвязку API, следует обратить внимание на шаблоны Composite, Decorator. Chain of Responsibility и Observer.
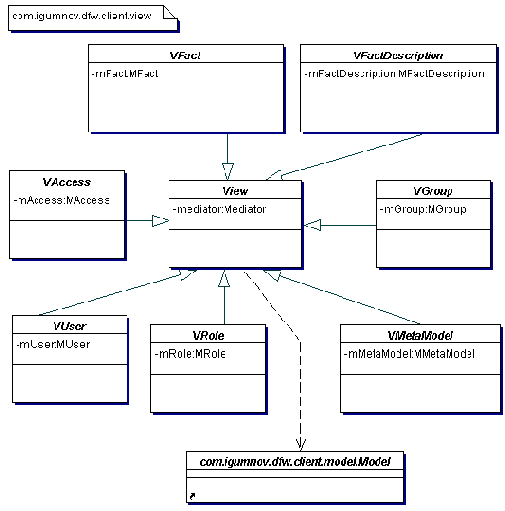
Рис. 3.2 Пакет вид
Пакеты источников метамодели, фактов и безопасности
Пакет source.meta на рис. 2.8 представляет собой интерфейс MetaSourceInterface с поддерживающим его заводом по шаблону Factory Method, который предоставляет клиентскому приложению Proxy-объект этого интерфейса по шаблону Proxy. Как уже говорилось выше, на стороне клиентского приложения реализуют этот интерфейс в виде стаба (stub), а на стороне сервера приложения - в виде скелетона (skeleton).
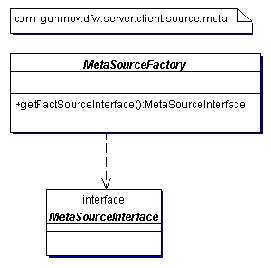
Рис. 2.8 Источник метамодели
Пакет source.fact на рис. 2.9 построен по таким же принципам, как пакет source.meta.
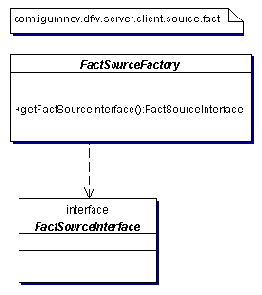
Рис. 2.9 Источник фактов
Пакет source.security на рис. 2.10 построен по таким же принципам, как пакет source.meta.
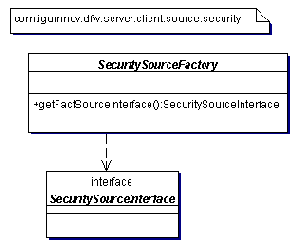
Рис. 2.10 Источник безопасности
Пакеты модели метамодели, фактов и безопасности
Пакет model.meta на рис. 2.2 содержит классы, описывающие метамодель предметной области, с которой работает система. Мной было выделено всего три основных класса для этой цели. Безусловно, ее необходимо расширять для каждой специфической предметной области. Класс MetaModel предназначен для того, чтобы держать в одной системе несколько метамоделей. Класс FactDescription описывает факты. Класс Group выступает в роли тематического классификатора фактов, который всегда присутствует в информационных системах и может быть также расширен.
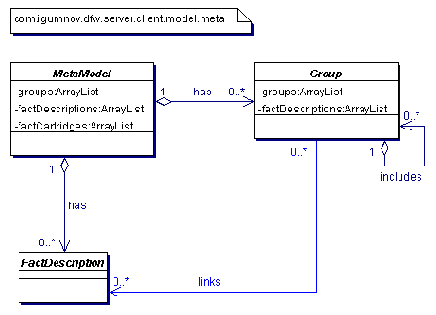
Рис 2.2 Модель метамодели
Пакет model.fact на рис. 2.3 имеет всего один класс Fact, объекты которого будут фактами. Этот класс следует, безусловно, расширить, так как встреченные мной факты из разных предметных областей имеют общее только то, что они являются фактами.
Рис. 2.3 Модель фактов
Пакет model.security на рис. 2.4 описывает права доступа к системе, к фактам и метамодели. За основу взято классическое решение безопасности. Есть пользователи (класс User), которые сопоставлены с ролями (класс Role), имеющими права доступа (класс Access) на метамодель, которая также описывает факты. Соответственно, отсутствие прав доступа на описание факта отсекает доступ на сам факт. В процессе аутентификации участвует класс User, а в процессе авторизации - классы Role и Access соответственно.
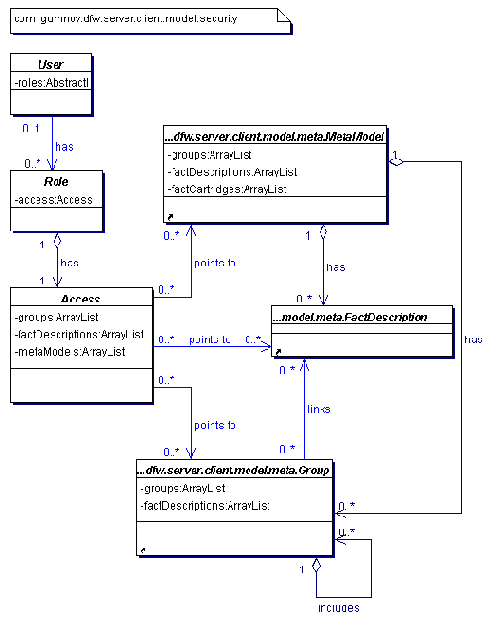
Рис. 2.4 Модель безопасности
Парадигмы программирования в Qt и Swing
Несмотря на то, что оценка API в определенной степени является делом личных предпочтений программиста, среди API-интерфейсов можно выделить такие, которые сделают ваш код более простым, кратким, элегантным и читаемым, чем другие. Ниже мы приводим два примера кода: первый с использованием Java/Swing, а второй с использованием C++/Qt, в которых реализуется вставка нескольких элементов в иерархическое дерево. Swing-код: ... DefaultMutableTreeNode root = new DefaultMutableTreeNode( "Root" ); DefaultMutableTreeNode child1 = new DefaultMutableTreeNode( "Child 1" ); DefaultMutableTreeNode child2 = new DefaultMutableTreeNode( "Child 2" ); DefaultTreeModel model = new DefaultTreeModel( root ); JTree tree = new JTree( model ); model.insertNodeInto( child1, root, 0 ); model.insertNodeInto( child2, root, 1 ); ...
Этот же код с использованием Qt: ... QListView* tree = new QListView; QListViewItem* root = new QListViewItem( tree, "Root" ); QListViewItem* child1 = new QListViewItem( root, "Child 1" ); QListViewItem* child2 = new QListViewItem( root, "Child 2" ); ...
Как видите, Swing использует архитектуру Model-View-Controller (MVC), в то время как Qt ее поддерживает, но не навязывает использовать. Поэтому Qt-код более интуитивен. К такому же результату приводит сравнение кода для создания заполненной таблицы или других сложных компонентов GUI.
Вторым интересным моментом является то, как различные инструментарии связывают воздействие пользователя (например, выбор элемента в выше созданном дереве) с определенной функциональностью (вызовом функции или метода). Синтаксически в Java/Swing и C++/Qt это выглядит по-разному, но основной принцип общий. Трудно сказать, какой код является более ясным и элегантным, Swing-код: ... tree.addTreeSelectionListener( handler ); ...
или Qt-код: ... connect( tree, SIGNAL( itemSelected( QListViewItem* ) ), handler, SLOT( handlerMethod( QListViewItem* ) ) ); ...
С одной стороны, Swing-код выглядит проще, а с другой - Qt-код более гибок. Qt позволяет программисту использовать для управляющей функции любое имя, в то время, как Swing обязывает использовать в качестве имени valueChanged() (вот почему в приведенном выше Swing-примере оно не было указано явно). Также Qt позволяет связывать событие (сигнал в терминологии Qt) с любым числом управляющих функций (слотов).
Таким образом, и Java/AWT/Swing, и C++/Qt одинаково хорошо подходят для разработки сложного пользовательского интерфейса. Главным недостатком Swing-интерфейса является низкая производительность Java.
Перед началом работы с Rapid Developer
Для начала требуется установить сам продукт Rapid Developer*, а также дополнительное программное обеспечение, которое требуется для создания и отладки приложений J2EE. В частности, необходимо установить сервер приложений и Java SDK. Так, простейший сервер приложений Tomcat 4.0 можно скачать с сайта Apache Software Foundation, посвященного , а Java SDK можно получить на одном из сайтов компании .
Описывать процесс инсталляции указанных продуктов - не тема данной статьи. Все это достаточно хорошо изложено в их документации. Наша задача - получить общее представление о Rapid Developer и некоторую пищу для размышлений, насколько данный продукт может быть полезен при ведении проектов по разработке J2EE приложений.
Передача сообщений в распределенной системе
Пользовательские приложения не обязаны "знать" внутреннюю структуру системы менеджеров MQSeries: адрес физического размещения очереди, типы коммуникаций между менеджерами очередей и т.п. Приложение, обращаясь к менеджеру очередей, всегда получает доступ только к локальным очередям сообщений. Когда приложение посылает сообщение в очередь, расположенную на удаленной системе, то сообщение для надежности записывается в специальную транспортную очередь (transmission queue), а уже затем переправляется по каналу передачи другому менеджеру на удаленную систему.
На рис. 1 показаны основные элементы, участвующие в передаче сообщения - от приложения к менеджеру очередей A и затем в удаленную очередь на менеджере очередей B.

Рис. 1. Порядок передачи сообщений
Переход в трехзвенную архитектуру при помощи Baikonur Web App Server.
В случае применения Baikonur Web App Server между клиентом и сервером появляется дополнительное звено - сервер приложений. Теперь приложения, изготовленные при помощи средства скоростной разработки (например, Delphi), работают не на клиентской стороне, а под управлением сервера приложений Baikonur. В зависимости от необходимого количества одновременно работающих клиентов, таких серверов может быть несколько. SQL сервер может работать либо на той же машине, где находится сервер приложений, либо быть выделенным в отдельный физический сервер. В случае SQL сервера от компании Borland это может быть даже сервер с другой операционной системой, например, какой-нибудь из наиболее удачных UNIX (Solaris, AIX, HP/UX, Digital UNIX, IRIX).
Собственно клиентское место представляет из себя теперь компьютер с достаточно произвольно выбираемой конфигурацией и операционной системой. Это может быть и Win 3.11, и Macintosh, и UNIX, и OS/2, и Win NT др... Клиентское место может находиться в сети (стек TCP/IP) или связываться с сервером Baikonur через прямое модемное соединение, через провайдера Internet или по специализированной выделенной линии.
На каждом клиентском рабочем месте устанавливается либо Internet-браузер общего назначения, либо специализированный браузер. При помощи таких браузеров пользователь устанавливает соединение с Web-сервером, запускает одно или несколько приложений на сервере (визуально спроектированных в Delphi), может переключаться между ними, не теряя контекста, может получать оперативную информацию и т.д.

Рисунок 2. Трехзвенная архитектура Internet/Intranet.
Перекуем мячи на пули
Теперь превратим мячик в пулю, придав ему новый алгоритм поведения. Для этого введем в конструктор мячика параметр - адрес таблицы переходов. Отметьте, кстати, что мы меняем алгоритм работы объекта, не меняя его методов, - прием, почти невозможный в обычном программировании.
Кроме того, как объекту некоторого контейнера библиотеки STL, классу необходимо добавить перегруженные операторы ==, !=, > и <.
Для связи со стрелком введены ссылка и метод, позволяющий ее установить. Анализ внутреннего состояния стрелка, к которому "прикреплена" пуля, при наступлении состояния "Выстрел" выполняет предикат x1. Предикат x2 определяет условие достижения пулей границы окна. Действие y4 введено для установки пули в исходную позицию в окне отображения. Метод SetCenter помещает бывший мячик (ныне - пулю) в заданную точку, а метод SetMove задает шаг перемещения по координатным осям (см. листинг 3).
В начальном состоянии st пуля ожидает события "Выстрел". Когда оно происходит, пуля вылетает и переходит в состояние b1. В этом состоянии она пребывает до тех пор, пока не достигнет границы окна, а затем возвращается в состояние st и ждет следующего выстрела (эдакая пуля-бумеранг).
Перемещение, копирование и удаление файлов
FSO имеет два метода для перемещения, копирования и удаления файлов:
| Задача | Метод |
| Переместить файл | File.Move или FileSystemObject.MoveFile |
| Скопировать файл | File.Copy или FileSystemObject.CopyFile |
| Удалить файл | File.Delete или FileSystemObject.DeleteFile |
Следующий пример создает текстовый файл в корневой директории дисковода с:, пишет в него некоторую информацию, перемещает его в каталог, называемый \tmp, затем копирует его в каталог, называемый \temp и, наконец, удаляет копии из обоих каталогов. Чтобы этот пример корректно сработал, удостоверьтесь, что на диске c: в корневой папке существуют каталоги \tmp и \temp. (Для упрощения примера в него не встроена проверка этого условия. В реальной программе, конечно, необходимо сначала убедиться в существовании целевой папки и при ее отсутствии создать.) Sub Manip_Files() Dim fso As New FileSystemObject, txtfile, fil1, fil2 Set txtfile = fso.CreateTextFile("c:\testfile.txt", True) MsgBox "Writing file" txtfile.Write ("This is a test.") txtfile.Close MsgBox "Moving file to c:\tmp" ' Код обработки файла в корне C:\ Set fil1 = fso.GetFile("c:\testfile.txt") ' Перемещаем файл в директорию \tmp fil1.Move ("c:\tmp\testfile.txt") MsgBox " Копируем файл в c:\temp" ' Копируем файл в \temp fil1.Copy ("c:\temp\testfile.txt") MsgBox "Удаляем файлы" ' Код получения текущих дерикторий файлов Set fil1 = fso.GetFile("c:\tmp\testfile.txt") Set fil2 = fso.GetFile("c:\temp\testfile.txt") ' Удаляем дайлы fil1.Delete fil2.Delete MsgBox "Все!" End Sub
© Copyright 2000, .
я рассказал обо всех программных
Итак, я рассказал обо всех программных средствах, предоставляемых Win64. Пора разобраться, как применить эти знания. В общем виде алгоритм перевода кода Win32 на 64-разрядную платформу выглядит так: замена "старых" типов новыми в тех случаях, когда это необходимо; замена всех 32-разрядных указателей на 64-разрядные; замена всех API-функций Win32 их 64-разрядными эквивалентами. Для создания кросс-платформенных приложений (это предпочтительней первого варианта) необходимо: воспользоваться макросами, определяющими платформу; заменить все 32-разрядные типы данных их интегральными эквивалентами; <>li>заменить все указатели на 64-разрядные; заменить API-функции Win32 их интегральными эквивалентами. К сожалению, пока не существует программ, которые могли бы помочь это сделать. Поэтому все изменения нужно делать самим. Единственным помощником в данном случае является 64-разрядный компилятор: в частности, его режим предупреждений (warnings), касающийся 64-разрядного кода. Для того чтобы включить эти предупреждения, нужно воспользоваться параметром компилятора-Wp64-W3. Он сделает активными следующие предупреждения: C4305 - предупреждение о преобразовании типов. Например, "return": truncation from "unsigned int64" to "long"; C4311 - предупреждение о преобразовании типов. Например, "type cast": pointer truncation from "int*_ptr64" to "int"; C4312 - преобразование до большего размера (bigger-size). Например, "type cast": conversion from "int" to "int*_ptr64" of greater size; C4318 - использование нулевой длины (Passing zero length). Например, passing constant zero as the length to the memset function; C4319 - нет оператора (Not operator). Например, "~": zero extending "unsigned long" to "unsigned _int64" of greater size; C4313 - вызов функций, входящих в printf-семейство, с конфликтным преобразованием типов в спецификаторах и аргументах. Например, "printf": "%p" in format string conflicts with argument 2 of type "_int64." Или, например, вызов функции printf("%x", pointer_value) потребует преобразования верхних 32 разрядов. Правильный вызов: printf("%p", pointer_value); C4244 - то же, что и C4242. Например, "return": conversion from "_int64" to "unsigned int," possible loss of data. Для преобразования кода в 64-разрядный нужно исправить все строки кода, на которые укажет компилятор. Некоторые советы приведены в таблице ниже.
Первые вздохи ядра (head.S)
Ядро к сожалению опять начнется с ассемблерного кода. Но теперь его будет совсем немного.
Мы собственно зададим правильные значения сегментов для данных (ES, DS, FS, GS). Записав туда значение соответствующего дескриптора данных. cld cli movl $(__KERNEL_DS),%eax movl %ax,%ds movl %ax,%es movl %ax,%fs movl %ax,%gs
Проверим, нормально ли включилась адресная линия A20 простым тестом записи. Обнулим для чистоты эксперимента регистр флагов. xorl %eax,%eax 1: incl %eax movl %eax,0x000000 cmpl %eax,0x100000 je 1b pushl $0 popfl
Вызовем долгожданную функцию, уже написанную на С. call SYMBOL_NAME(start_my_kernel)
И больше нам тут делать нечего.
inf: jmp inf
Platform Builder
Подготовка программ для Windows CE - только одна сторона работы с этой операционной системой. Известно, что версии Windows для настольных машин можно переносить на другие совместимые ПК, однако права на поставку комплектов инструментов, необходимых для этих целей, принадлежат компании Microsoft и ее уполномоченным OEM-партнерам. Напротив, аналогичный набор Platform Builder для Windows CE, несмотря на его дороговизну, распространяется через розничные каналы. Таким образом, разработчики программ для Windows CE могут не только составлять программы, но и подготавливать различные версии самой операционной системы.
В состав Platform Builder входят тексты образцов программ для слоя абстракции OEM (OEM abstraction layer, OAL), который представляет собой слой программ, разработанных производителем оборудования для адаптации Windows CE к конкретной аппаратуре. OAL содержит ПО слоя аппаратной абстракции (Hardware Abstraction Layer, HAL), предназначенное для обслуживания ядра Windows CE, а также драйверы для встроенных аппаратных компонентов, например клавиатуры, сенсорного экрана и дисплея. Кроме того, имеются тексты программ для образцов драйверов аудиоустройств и последовательного порта, а также драйвера контроллера PCMCIA.
Комплект Platform Builder предусматривает и средства низкоуровневой отладки. Эти инструменты предназначены прежде всего для содействия в переносе Windows CE на новые аппаратные платформы, но они вполне пригодны и для диагностирования трудноустранимых проблем прикладного ПО. В новейших версиях Windows CE есть специальные программные процедуры для работы со встроенным профилировщиком Монте-Карло - весьма удобным средством оптимизации производительности программ. Наконец, Platform Builder сопровождает обширная, с точки зрения производителя оборудования, документация по эксплуатации Windows CE.
Программирование в среде Windows CE - занятие довольно интересное. Интерфейс API Win32 придает этому процессу сходство с программированием для Windows 98 или NT, однако при разработке программ приходится учитывать аппаратные ограничения. Менее быстродействующие ЦП и ограниченный объем памяти большинства Windows CE-устройств заставляют тщательно продумывать подходы к программированию, чтобы повысить эффективность своих творений. На самом деле довольно забавно в наше время, т. е. в эпоху многомегабайтных программ для ПК, увидеть программистов, всерьез озабоченных быстродействием ЦП и объемами программ.
Подавление "горячих" клавиш.
Q:Как подавить доступ по "горячим" клавишам, имеется ввиду предопределенные в Excel клавиши типа Ctrl-O и т.д.?
A:Вот малюсенький исходник на Excel VB, который решает такую проблему. :-)
Public Sub Auto_Open()
' Overrride standard accelerators
With Application
.OnKey "^o", "Dummy"
.OnKey "^s", "NewAction"
.OnKey "^р", "" ' Kill hotkey !
End With
End Sub
' -----
Public Sub Dummy()
MsgBox "This hotkey redefined!"
End Sub
' -----
Public Sub NewAction()
SendKeys "^n" ' Press <CTRL>+<s> for create new file
' instead of <CTRL>+<n> !
End Sub
Hint: Отлажено в MS Excel '97 !
Поддержка многоязыковых приложений
Объект Flora/C+ класса < константа > может иметь несколько значений. На основе этого свойства возможна разработка приложений с несколькими языковыми интерфейсами. Flora/C+ сама является таким многоязыковым приложением, поддерживающим в настоящее время два европейских языка : английский и русский и открыта для расширений.
Поддержка операционных систем, предлагаемые службы и масштабируемость
Помимо механизмов интеграции объектов, СОМ и CORBA предоставляют набор предопределенных объектных служб общего значения, без реализации которых, как правило, не обходится ни одна прикладная среда. Перечень и назначение одноименных служб в двух объектных архитектурах не идентичны. В СОМ предусмотрены такие общие службы, как защита (security), управление жизненным циклом (lifecycle managemеnt), информация о типах (type information), именование (naming), доступ к базам данных (database access), передача данных (data transfer), регистрация (registry) и асинхронное взаимодействие. В CORBA информация о типах и регистрация входят в число базовых функций брокера объектных запросов ORB. Служба именования в CORBA - это каталог, в котором заданы соответствия между объектами и их именами. В СОМ под именованием подразумевается схема преобразования имен в указатели на объект с помощью механизма moniker.
В СОМ службы защиты, регистрации, именования и информации о типах непосредственно включены в объектную модель. Ряд объектных служб реализованы в MTS, который создает на базе архитектуры СОМ многофункциональную среду времени выполнения для реализации компонентных прикладных систем, предоставляя разработчикам возможность декларировать требования к объектам, а не заниматься непосредственным программированием. MTS реализует такие службы, как гарантированное выполнение транзакций, контроль за разделяемым доступом к ресурсам, управление жизненным циклом экземпляров объектов, управление сеансами баз данных и защита. СОМ+ полностью интегрирует MTS.
Механизм вызова удаленной процедуры обеспечивает синхронное взаимодействие клиента и сервера, но для многих распределенных приложений могут потребоваться и неблокирующие, асинхронные взаимодействия между компонентами. Эту задачу решает сервер очередей сообщений Microsoft Message Queuing (MSMQ), который обеспечивает гарантированную, асинхронную доставку сообщений при помощи механизма очередей. MSMQ доступен как в рамках СОМ, так и независимо, при помощи API-интерфейсов.
Службы СОМ и серверы MTS и MSMQ реализованы на платформах Windows 95 и Windows NT и тесно интегрированы со службами самих этих операционных систем.
Подобная интеграция нацелена на создание на базе Windows гибкой и надежной среды разработки и исполнения объектно-ориентированных систем. Microsoft стремится сделать свою платформу максимально привлекательной для разработчиков приложений, но проявляет и определенную заботу об интеграции с унаследованными системами. Для этих целей существуют, например, средства OLE DB for AS/400, СОМ Transaction Integrator для CICS и IMS, предоставляющий доступ к системам оперативной обработки транзакций IBM, сервер Microsoft SNA. Следуя общим принципам архитектуры CORBA, интерфейсы ее объектных служб (спецификация CORBAservices) написаны на IDL. Определено 15 общих служб CORBA: именования (naming); событий (events); жизненного цикла (life cycle); долговременного хранения объектов (persistent); транзакций (transactions); контроля за доступом к разделяемым ресурсам (concurrency control); отношений (relationsips); импорта/экспорта (externalization); запросов (query); лицензирования (licensing); свойств (property); времени (time); защиты (security); переговоров между объектами (object trader); сбора объектов (object collections). Объектные службы CORBA следуют строгой согласованной модели. Наиболее значимые из них присутствуют по крайней мере в одной из многочисленных реализаций архитектуры. К самым распространенным относятся службы именования, управления жизненным циклом и событиями, которые были первыми из принятых OMG. Более поздние предложения OMG, например, служба транзакций, пока имеют более ограниченный спектр реализаций. Наименее успешными оказались реализации службы долговременного хранения, и ее спецификация будет заменена в CORBA 3.0 на новую - Persistent State Service (PSS). В этой версии появятся также новая служба именования Interoperable Naming Service для прозрачного поиска и вызова объектов, не зависящего от конкретной реализации ORB, и служба асинхронного обмена сообщениями Asynchronous Messaging. До 1998 года реализации СОМ ограничивались NT и Windows 95. Сейчас Microsoft, как кажется, начинает поворачиваться лицом и к другим операционным системам.
Правда, поначалу политика корпорации состояла в том, чтобы привлекать третьи фирмы к реализации СОМ на других платформах. Так, версия СОМ для Sun Solaris была разработана компанией Software AG. О своих намерениях перенести СОМ на платформу OpenVMS объявила Compaq. Однако, судя по последним заявлениям, Microsoft намерена в дальнейшем собственными силами решать проблемы переноса СОМ. Мы уже упоминали об ограничениях языковой поддержки в СОМ. Новый вариант объектной модели, СОМ+, помимо реализации множественного наследования интерфейсов и новых возможностей времени выполнения, обещает предоставить языковые расширения, призванные упростить разработку компонентов СОМ на языках Java, Visual Basic и Visual C++. Правда, в отличие от CORBA, где трансляция описаний на IDL в конкретный язык осуществляется наиболее естественным для этого языка способом и не требует никаких его модификаций, в СОМ+ будут включены средства настройки языка для поддержки компонентов СОМ. Если Visual Basic тесно привязан к операционным системам Microsоft, то Java по сути своей - многоплатформенный язык. В виртуальную Java-машину от Microsоft были добавлены средства поддержки СОМ. Благодаря этому объекты на Java без проблем отображаются в СОМ - но только при использовании Microsоft JVM. Чтобы преодолеть это ограничение, Microsоft надо либо реализовать виртуальные Java-машины для других платформ, либо обеспечить поддержку СОМ в Java, минуя JVM. В CORBA изначально была заложена многоплатформенность и поддержка множества популярных языков программирования без необходимости каких-либо изменений в них. Поэтому реализации CORBA могут использоваться с произвольными компилятором, средствами разработки и операционной системой. По существу, объектный брокер запросов реализуется на большем числе платформ Microsoft, чем сама СОМ, включая Windows 3.1, Windows 95, Windows NT 3.5, Windows 4.0 и DOS. Cтандартно поддерживается значительный диапазон языков. Отображения объектов CORBA в другие языки, например, в тот же Visual Basic, пока не являются стандартными возможностями данной архитектуры, но наличествуют в некоторых реализациях. Отображения CORBA-интерфейсов в Java не требуют никаких изменений от виртуальной Java-машины.
Реализации компаний Iona, Sun и Visigenic предлагают службы CORBA времени выполнения, написанные на Java. Это означает, что в браузер можно загрузить апплет Java, который сможет обращаться к серверу CORBA без предварительной установки средств поддержки CORBA. Зрелость и разнообразие объектных служб общего назначения, которые позволяют создать реально работающую объектную систему, и спектр поддерживаемых платформ - ключевые факторы при оценке масштабируемости объектной архитектуры. А масштабируемость - ключевая характеристика корпоративной системы. Обе модели предлагают широкий спектр общих служб, однако, СОМ, как и все детища Microsoft, не может похвастаться реальной многоплатформенностью. Это серьезный изъян для системы, которая претендует на роль фундамента для распределенных приложений в крупных организациях. Корпоративная система может охватывать тысячи пользователей, хранить терабайты данных и выполнять десятки тысяч транзакций в день. Для этого понадобятся и клиентские настольные системы, и серверы данных, и серверы приложений, и интеграция с унаследованными приложениями на мэйнфреймах. Поэтому в борьбе за крупных заказчиков не ограниченная в выборе операционных систем архитектура CORBA имеет определенные преимущества перед СОМ.
Подготовка загрузочного образа (floppy.img)
Итак, подготовим загрузочный образ нашей системки.
Для начала соберем загрузочный сектор. as86 -0 -a -o boot.o boot.S ld86 -0 -s -o boot.img boot.o
Обрежем 32 битный заголовок и получим таким образом чистый двоичный код. dd if=boot.img of=boot.bin bs=32 skip=1
Соберем ядро gcc -traditional -c head.S -o head.o gcc -O2 -DSTDC_HEADERS -c start.c
При компоновке НЕ ЗАБУДБЬТЕ параметр "-T" он указывает относительно которого смещения вести расчеты, в нашем случае поскольку ядро грузится по адресy 0x1000, то и смещение соотетствующее ld -m elf_i386 -Ttext 0x1000 -e startup_32 head.o start.o -o head.img
Очистим зерна от плевел, то есть чистый двоичный код от всеческих служебных заголовков и комментариев objcopy -O binary -R .note -R .comment -S head.img head.bin
И соединяем воедино загрузочный сектор и ядро cat boot.bin head.bin >floppy.img
Образ готов. Записываем на дискетку (заготовьте несколько для экспериментов, я прикончил три штуки) перезагружаем компьютер и наслаждаемся.
cat floppy.img >/dev/fd0
Подсчет комментариев на рабочем листе
Q: Как узнать есть ли хоть один Notes (комментарий) в рабочем листе, кроме как перебором по всем ячейкам? . Без этого не работает:
A: В Excel'97 эта проблема может быть решена вот как:
' Function IsCommentsPresent
' Возвращает TRUE, если на активном рабочем листе имеется хотя бы
' одна ячейка с комментарием, иначе возвращает FALSE
'
Public Function IsCommentsPresent() As Boolean
IsCommentsPresent = ( ActiveSheet.Comments.Count <> 0 )
End Function
Подсистема формирования тем и стилей
Данная подсистема позволяет работать с библиотекой тем и стилей. Можно использовать существующие темы и стили, а можно создавать собственные. Не существует никаких ограничений на количество создаваемых тем и стилей.
Архитектор тем позволяет динамически создавать или изменять темы для страниц. Тема в Rapid Developer определяет наборы цветов, шрифтов и вспомогательных картинок, которые применяются к целым страницам или наборам страниц сайта. Применение темы к разрабатываемому сайту в динамическом режиме позволяет быстро и наглядно определить наиболее подходящее представление для него.
Репозиторий стилей дает возможность разработчику определить наборы шаблонов стилей, которые могут быть применены к различным графическим элементам интерфейса. Результат - значительное ускорение разработки эргономичных Web-страниц.
Главный принцип - создал один раз, используй много раз!
Подсистема определения бизнес-правил
Rapid Developer позволяет определить различные бизнес-правила для разрабатываемой информационной системы. Эти правила выявляются бизнес-аналитиками. Наиболее общими примерами бизнес-правил являются:
Определение начальных значений для атрибутов классов. Определение наследуемых значений атрибутов, на которые влияют одно или сразу несколько значений других атрибутов. Определение валидности значений атрибутов классов (минимумы, максимумы, диапазоны значений и т.д.).
Бизнес-правила определяются либо в окне свойств класса для конкретного атрибута (вкладка "Attribute" и далее - "Business Rules"), либо в Архитекторе логики (вкладка "Classes" дерева объектов в левом фрейме).
Подсказки к Toolbar
Q: Как сделать к «само нарисованным» кнопочкам на Toolbar’е подсказки? (Ну, те, что после 2-х секунд молчания мышки появляются)
A: Сделать можно вот как: (Пример реализации на Excel’97 VBA )
' Cоздаем тулбар
Рublic Sub InitToolBar()
Dim cmdbarSM As CommandBar
Dim ctlNewBtn As CommandBarButton
Set cmdbarSM = CommandBars.Add(Name:="MyToolBar",
Position:=msoBarFloating, _
temporary:=True)
With cmdbarSM
' 1) Добавляем кнопку
Set ctlNewBtn = .Controls.Add(Type:=msoControlButton)
With ctlNewBtn
. FaceId = 26
.OnAction = "OnButton1_Click"
.TooltipText = "My tooltip message!"
End With
' 2) Добавляем ещё кнопку
Set ctlNewBtn = .Controls.Add(Type:=msoControlButton)
With ctlNewBtn
.FaceId = 44
.OnAction = "OnButton2_Click"
.TooltipText = "Another tooltip message!"
End With
.Visible = True
End With
End Sub
Hint: На VBA для Excel'95 это делается несколько иначе!
Подсказки к Toolbar (Excel'95)
Q: Как сделать свой собственный Toolbar с tooltip’ами на кнопках в Excel’95?
A: Вот фрагмент кода для Excel'95, который создаёт toolbar с одной кнопкой с пользовательским tooltiр'ом. Нажатие кнопки приводит к выполнению макроса NothingToDo() .
'
' This example creates a new toolbar, adds the Camera button
' (button index number 228) to it, and then displays the new toolbar.
'
Public Sub CreateMyToolBar()
Dim myNewToolbar As Toolbar
On Error GoTo errHandle:
Set myNewToolbar = Toolbars.Add(Name:="My New Toolbar")
With myNewToolbar
.ToolbarButtons.Add Button:=228, StatusBar:="Statusbar help string"
.Visible = True
With .ToolbarButtons(1)
.OnAction = "NothingToDo"
.Name = "My custom tooltiр text!"
End With
End With
Exit Sub
errНandle:
MsgBox "Error number " & Err & ": " & Error(Err)
End Sub
'
' Toolbar button on action code
'
Рublic Sub NothingToDo()
MsgBox "Nothing to do!", vbInformation, "Macro running"
End Sub
Нint: В Excel'97 этот код тоже работает!
Подведение итогов
Приложения с поддержкой сценариев обеспечивают гибкость и выгоду для отделов поддержки и конечных пользователей, а также освобождают разработчиков от многочисленных функциональных вариаций. QSA предоставляет в распоряжение программистов сценариев все возможности Qt.
Библиотека QSA представляет собой готовое решение для включения его разработчиками в свои приложения. Она содержит интерпретатор языка сценариев и QSA Designer, мощную интегрированную среду разработки, предназначенную для создания, редактирования, выполнения и отладки сценариев конечными пользователями. QSA позволяет легко добавить в приложения поддержку сценариев. Если вы хотите узнать больше о QSA, пишите .
Поговорим на языке высокого уровня (start.c)
Вот теперь мы вернулись к тому с чего начинали рассказ. Почти вернулись, потому что printf() теперь надо делать вручную. поскольку готовых прерываний уже нет, то будем использовать прямую запись в видеопамять. Для любопытных - почти весь код этой части , с незначительными изменениями, повзаимствован из части ядра Linux, осуществляющей распаковку (/arch/i386/boot/compressed/*). Для сборки вам потребуется дополнительно определить такие макросы как inb(), outb(), inb_p(), outb_p(). Готовые определения проще всего одолжить из любой версии Linux.
Теперь, дабы не путаться со встроенными в glibc функциями, отменим их определение #undef memcpy
Зададим несколько своих static void puts(const char *); static char *vidmem = (char *)0xb8000; /*адрес видеопамати*/ static int vidport; /*видеопорт*/ static int lines, cols; /*количество линий и строк на экран*/ static int curr_x,curr_y; /*текущее положение курсора */
И начнем, наконец, писать код на языке высокого уровня... правда с небольшими ассемблерными вставками.
/*функция перевода курсора в положение (x,y). Работа ведется через ввод/вывод в видеопорт*/ void gotoxy(int x, int y) { int pos; pos = (x + cols * y) * 2; outb_p(14, vidport); outb_p(0xff & (pos >> 9), vidport+1); outb_p(15, vidport); outb_p(0xff & (pos >> 1), vidport+1); }
/*функция прокручивания экрана. Работает, используя прямую запись в видеопамять*/ static void scroll() { int i; memcpy ( vidmem, vidmem + cols * 2, ( lines - 1 ) * cols * 2 ); for ( i = ( lines - 1 ) * cols * 2; i < lines * cols * 2; i += 2 ) vidmem[i] = ' '; }
/*функция вывода строки на экран*/ static void puts(const char *s) { int x,y; char c; x = curr_x; y = curr_y; while ( ( c = *s++ ) != '\0' ) { if ( c == '\n' ) { x = 0; if ( ++y >= lines ) { scroll(); y--; } } else { vidmem [ ( x + cols * y ) * 2 ] = c; if ( ++x >= cols ) { x = 0; if ( ++y >= lines ) { scroll(); y--; } } } } gotoxy(x,y); }
/*функция копирования из одной области памяти в другую. Заместитель стандартной функции glibc */ void* memcpy(void* __dest, __const void* __src, unsigned int __n) { int i; char *d = (char *)__dest, *s = (char *)__src; for (i=0;i<__n;i++) d[i] = s[i]; }
/*функция издающая долгий и протяжных звук.
Поиск и добавление
До тех пор, пока память переводов была линейной, сегменты неделимыми, а сравнение строгим, решение задачи поиска сводилось к введению отношения строгого лексикографического порядка над множеством сегментов на исходном языке. Иными словами, определялся оператор "меньше", на основе которого можно было осуществить обыкновенный двоичный поиск, и проверку на равенство. С введением оператора "нечеткого совпадения", который позволял оценить степень сходства для любых двух сегментов, решение проблемы поиска резко усложнилось и, без дополнительных ухищрений с различного рода индексацией, стало эквивалентно задаче полного перебора. Предложенная многоуровневая модель памяти переводов, собственно, и предоставляет некоторый механизм неявной индексации: каждое входящее в сегмент слово, по сути, идентифицирует некоторое подмножество ориентированного графа памяти переводов, состоящее из узлов, которые можно достичь, начав обход от узла, соответствующего выбранному слову.
Используя особенности выбранной структуры памяти переводов, задачу поиска сегментов, похожих на заданный, можно решить путем выполнения следующих действий (рис. 4): разбить заданный сегмент на слова; найти в памяти переводов все узлы, соответствующие этим словам; спускаясь по графу отношений наследования, помещать в список найденных сегментов все встречаемые узлы.
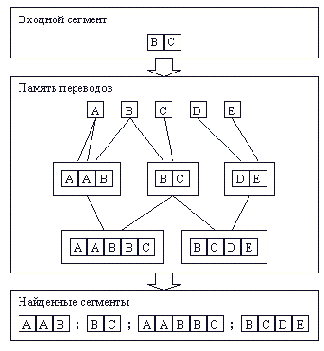
Рис. 4
Резонным представляется вопрос о том, в каком порядке следует предоставлять найденные сегменты переводчику: ведь приведенная процедура поиска выберет из памяти все сегменты, пересекающиеся с заданным по крайней мере по одному слову. Каковы правила фильтрации и сортировки найденных сегментов?
Ответ на этот вопрос лежит за пределами выбранного формализма, однако в этом нет ничего страшного. Дело в том, что результат поиска представляет собой классический вариант одноуровневой памяти переводов, анализ которого может быть произведена методами, формализованными в рамках существующих сред перевода. Для обеспечения эффективности поиска целесообразно осуществлять оценку "пригодности" сегментов по мере их нахождения.
Например, если некоторый сегмент полностью совпадает с эталоном, то все его потомки в графе могут быть автоматически исключены из поиска. Теперь поговорим о задаче добавления нового сегмента в память переводов. Очевидным условием корректности процедуры добавления является обеспечение успешного поиска. Стало быть, добавляемый сегмент должен иметь в числе своих предков (не обязательно прямых) все составляющие его слова. Следуя целям оптимальности, можно заключить, что среди предков должны присутствовать также узлы графа, содержащие фрагменты данного сегмента. Иными словами, если в памяти переводов присутствуют сегменты "AB" и "CD", то сегмент "ABCD" должен стать наследником этих двух сегментов. Аналогично, если в памяти присутствует сегмент "ABCD", то добавляемый сегмент "AB" должен стать его предком. В общем случае при добавлении сегмента в граф памяти переводов могут существовать альтернативные варианты наследования. В такой ситуации схема добавления заметно усложнится. В любом случае, проблема построения оптимальной иерархии классов решается в рамках объектно-ориентированного подхода, поэтому мы не будем заострять здесь на ней внимание.
Поиск языковых пар в памяти переводов
Автоматическая память переводов, или просто память переводов (TranslationMemory), подразумевает, в первую очередь, просмотр ранее переведенных текстов. Она сравнивает переводимый в текущий момент текст с тем, что хранится в базе, "вспоминает" сегменты, которые изменились незначительно, и предлагает использовать их перевод повторно. Разумеется, критерии сходства сегментов могут быть различны, и они играют очень важную роль в расширении возможностей памяти переводов.
Пользовательский интерфейс
Помимо получения необходимой информации отладчик должен предоставить ее в удобном для пользователя виде. Для этого служат интерфейсные команды и функции.
Интерфейс отладчика состоит из: графического интерфейса; режима комадной строки; команд представления данных.
1) Графический интерфейс
Основное требование, предъявляемое к графическому интерфейсу активного отладчика - одновременная визуализация информации об отлаживаемой задаче (например, окно исходного текста, диалоговое окно, окно отображения данных и сообщений). При отладке группы задач, необходимо отображать полную информацию о каждой из них, как это реализовано в X-ray.
2) Режим командной строки
В режиме командной строки отладчик должен предоставлять пользователю возможность редактировать вводимые команды, а также поддерживать хранение ранее введенных команд в некотором буфере с целью их последующего вызова и модификации.
3) Команды представления данных
Приведем некоторые способы представления и хранения данных, реализация которых в значительной степени упрощает работу пользователя: История значений.
Хранение ранее отображенных значений позволяет следить за изменением инспектируемого выражения. Значения могут храниться в некотором буфере или файле. Внутренний язык отладчика.
Внутренний язык - средство, дающее возможность пользователю определять собственные функции. Кроме этого отладчик может обладать встроенным интерпретатором какого-нибудь известного языка сценариев. Например, VxGDB обладает встроенным TCL-интерпретатором, позволяющим не только определять новые функции обработки данных, но и (при поддержке с целевой стороны) эмулировать ряд функций VxWorks. Поддержка разных форматов представления данных.
Уже упоминавшиеся средства отладки (VxGDB, X-Ray) предоставляют возможность вывода интересующего значения в любом числовом или символьном формате. Кроме того, в них имеется поддержка сложных элементов языка, таких как массивы или структуры. Поддержка нескольких языков.
Если программа собрана из модулей, написанных на разных языках программирования, то для ее полноценной отладки необходима поддержка всех этих языков. Кроме того, VxGDB поддерживает синтаксис основных языков программирования (C, fortran) для своего внутреннего языка, обеспечивая автоматическую его смену при выполнении функции, реализованной на языке, отличном от текущего. Регулярное отображение данных.
При отладке может потребоваться просмотр некоторых данных (или выполнение команд) при каждой остановке задачи.
GDB в данном случае предоставляет следующие возможности:
Команда display. После остановки выполнения задачи (но не в случае, когда она завершилась) производится отображение данных, заданных в качестве аргументов этой команды. Команда commands привязывает к точке прерывания, номер которой задан в качестве аргумента, набор действий, которые нужно реализовать отладчику при достижении этой точки прерывания.
При анализе данных или профилировании важную роль играет представление полученной информации. Как и в случае активной отладки пользовательский интерфейс делится на три составляющих: графический интерфейс, режим командной строки и команды представления данных.
Графическое представление данных - наиболее важная часть пользовательского интерфейса при мониторинге. Поскольку, как правило, анализируется взаимодействие задач в системе, то нужна визуализация всех событий и задач системы. В WindView для этого служит специальное окно View Graph. По горизонтали откладывается время (единичный интервал времени может меняться), по вертикали приведен список всех задач в системе и уровни прерываний. В такой системе координат легко увидеть, какая задача в какой момент времени в каком состоянии находилась. Особыми значками отмечаются происходящие события, подробности о которых (также как и о задачах) можно увидеть в другом окне.
При мониторинге текущего состояния системы удобно пользоваться графическим интерфейсом, но при анализе сохраненных ранее данных, а также при "посмертной" отладке, можно использовать режим командной строки. Требования к нему предъявляются аналогичные тем, что были у средств активной отладки.
Помимо описанных в предыдущей главе команд представления данных у активных отладчиков средства мониторинга могут располагать также такими командами:
исполнение некоторой последовательности действий при произошедшем событии, поступившем сигнале или наступлении определенного момента времени; определение пользователем собственных событий (eventpoints в WindView) и сигналов (комбинации известных сигналов "derived signals" в StethoScope).
Понятие ловушки.
Ловушка (hook) - это механизм, который позволяет производить мониторинг сообщений системы и обрабатывать их до того как они достигнут целевой оконной процедуры.
Для обработки сообщений пишется специальная функция (Hook Procedure). Для начала срабатывания ловушки эту функцию следует специальным образом "подключить" к системе.
Если надо отслеживать сообщения всех потоков, а не только текущего, то ловушка должна быть глобальной. В этом случае функция ловушки должна находиться в DLL.
Таким образом, задача разбивается на две части:
Написание DLL c функциями ловушки (их будет две: одна для клавиатуры, другая для мыши). Написание приложения, которое установит ловушку.
Портируем 32-разрядный код
При портировании 32-разрядного кода на 64-разрядную платформу следует учитывать следующие моменты: следите за разрядностью указателей и адресуемых ими данных. Если разрядности не совпадут, то либо приложение потеряет в производительности (операционная система сама будет расширять указатели), либо будет утрачена часть данных (они могут быть просто затерты); используйте интегральные типы данных и функции Win64. Это позволит избежать множества конфликтных ситуаций; делайте приложения кросс-платформенными. Это залог стабильности и высокой производительности приложения (гарантия корректной работы); старайтесь исправлять код так, чтобы он не вызывал ни одного предупреждения 64-разрядного компилятора. Это позволит оптимизировать код и устранить риск, связанный со скрытыми в нем ошибками.
Таблица 1.
Типы данных для 64-разрядного программирования.

ПОСТРОЕНИЕ АРХИТЕКТУРЫ ПРИЛОЖЕНИЯ
Любое классическое приложение, ориентированное на использование в среде Интернет, имеет несколько уровней обработки и представления данных, среди которых можно выделить: уровень хранения данных или просто хранилище данных, где на данные накладываются ограничения связанные с особенностями хранения данных в выбранной СУБД уровень бизнес логики, где применяются, так называемые внешние логические ограничения, накладываемые особенностями предметной области уровень пользовательского представления данных, где информация обрабатывается непосредственно перед выводом пользователю и оформляется в зависимости от его требований и предпочтений
Проектирование системы требует обязательного рассмотрения вопросов обработки и представления данных на всех уровнях. Последовательность действий при этом обычно следующая: изучение предметной области, разработка инфологической модели представления данных, разработка датологической модели представления данных с учётом выбранной СУБД, внешняя (имеется ввиду в коде программы) реализация правил вносимых особенностями предметной области, разработка интерфейса пользователя и системы управления отображаемыми данными.
При применении CS проектирование системы значительно упрощается. Разработка любого проекта начинается с развёртывания прототипа сайта с необходимыми ресурсами и приложениями. Прототип содержит все возможные готовые подсистемы и шаблоны некоторых ASP страниц.
Любая готовая подсистема, входящая в состав Commerce Server, имеет свою спроектированную подсхему данных, состоящую из нескольких заранее связных между собой таблиц. Работа с каждой подсхемой данных осуществляется с использованием хранимых процедур и триггеров. В таких заранее спланированных схемах, данные обычно хранятся во второй нормальной форме или вообще не нормализованными, что однако позволяет добиваться максимального быстродействия при решении стандартных задач.
Заранее спроектированные схемы данных каждой из подсистем позволяют учитывать также часть основных правил бизнес логики, обычно действующих при реализации этих подсистем.
Так, например, в продуктовом каталоге обязательным атрибутом продукта является цена, которая не может быть отрицательным значением. Разработчик может создавать новые операции преобразования данных и определять последовательность их выполнения с помощью, так называемых, Pipeline. Commerce Server содержит также богатый набор средств для построения уровня пользовательского представления данных, для которого используются Active Server Pages. Все страницы сайта обычно выполняются с использованием нескольких шаблонов, поставляемых в комплекте с Commerce Server, однако разработчик Web-приложения может легко сам разработать собственный шаблон и сами страницы, ограничиваясь только своей фантазией. В каждую страницу сайта встраиваются готовые объекты, от конфигурации которых зависит функциональность конечного решения. Объекты выполнены в соответствии с Component Object Model (COM). COM-объекты имеют собственные интерфейсы прикладного программирования (API) для языков Visual Basic Script Edition и Visual C++. Использование Commerce Server в создании систем электронной коммерции позволяет значительно упростить этапы разработки, поскольку разработчику остаётся только настроить уже существующую модель. Это становиться возможным также за счёт некоторого однообразия задач, для решения которых применяется Commerce Server, и благодаря тесной интеграции с Microsoft SQL Server и MS IIS. Как результат - существенная экономия ресурсов и сокращение сроков реализации и внедрения проекта за счёт использования готовой инфраструктуры при построении своей системы электронной коммерции.
Предварительный просмотр отчетов
В некоторых случаях требуется предварительный просмотр отчетов на этапевыполнения. Для этой цели используется метод Preview() компонента TQuickReport.При его выполнении на экране появится стандартная форма просмотра, изображеннаяна рис. 8.
Если внешний вид стандартной формы просмотра по какой-либо причине васне устраивает, можно создать свою форму предварительного просмотра с помощьюкомпонента QRPreview. Этот компонент обладает свойствами PageNumber и Zoom,которые можно использовать для просмотра произвольной страницы отчета впроизвольном масштабе.
Для создания собственного окна предварительного просмотра следует навновь созданной форме разместить компонент QRPreview и набор элементовуправления (например, кнопок) для перемещения между страницами, изменениямасштаба, печати и др. Далее следует написать код, аналогичный приведенному ниже примеру: void __fastcall TForm1::ShowPreview() { Form2->ShowModal(); } void __fastcall TForm1::Button1Click(TObject *Sender) { QRPrinter->OnPreview=ShowPreview; Form4->QuickReport1->Preview(); Form2->ShowModal(); }
Кроме того, нужно внести прототип функции ShowPreview() в соответствующийh-файл: __published: // IDE-managed Components TButton *Button1; void __fastcall Button1Click(TObject *Sender); void __fastcall ShowPreview(void);
Приведенный пример кода показывает, как связать созданную форму с компонентомQuickReport. Эта связь достигается написанием обработчика события QRPrinter->OnPreview.Это событие не имеет прямого отношения к компоненту QuickReport, иначенужно было бы связывать все созданные отчеты с окном просмотра. Использованиесобытия объекта QRPrinter обычно означает написание общего для всех отчетовобработчика события, после чего окно просмотра можно использовать для всехимеющихся в приложении отчетов.
Более подробно о компонентах, используемых для создания отчетов, можнопрочесть в книге "Введение в Borland C++ Builder" Н.Елмановойи С.Кошеля, вышедшей в июле этого года в издательстве "Диалог-МИФИ".
Файлы, необходимые для первого примера
Файл констант ресурсов resource.inc IDD_DIALOG = 65 ; 101 IDR_NAME = 3E8 ; 1000 IDC_STATIC = -1
Файл заголовков resource.h #define IDD_DIALOG 101 #define IDR_NAME 1000 #define IDC_STATIC
Файл определений dlg.def NAME TEST DESCRIPTION 'Demo dialog' EXETYPE WINDOWS EXPORTS DlgProc @1
Файл компиляции makefile
# Make file for Demo dialog # make -B
NAME = dlg OBJS = $(NAME).obj DEF = $(NAME).def RES = $(NAME).res
TASMOPT=/m3 /mx /z /q /DWINVER=0400 /D_WIN32_WINNT=0400
!if $d(DEBUG) TASMDEBUG=/zi LINKDEBUG=/v !else TASMDEBUG=/l LINKDEBUG= !endif
!if $d(MAKEDIR) IMPORT=$(MAKEDIR)\..\lib\import32 !else IMPORT=import32 !endif
$(NAME).EXE: $(OBJS) $(DEF) $(RES) tlink32 /Tpe /aa /c $(LINKDEBUG) $(OBJS),$(NAME),, $(IMPORT), $(DEF), $(RES)
.asm.obj: tasm32 $(TASMDEBUG) $(TASMOPT) $&.asm
$(RES): $(NAME).RC BRCC32 -32 $(NAME).RC
Файлы, необходимые для второго примера
Файл описания mylib.def LIBRARY MYLIB DESCRIPTION 'DLL EXAMPLE, 1997' EXPORTS Hex2Str @1
Файл компиляции makefile # Make file for Demo DLL# make -B# make -B -DDEBUG for debug information
NAME = mylib OBJS = $(NAME).obj DEF = $(NAME).def RES = $(NAME).res
TASMOPT=/m3 /mx /z /q /DWINVER=0400 /D_WIN32_WINNT=0400
!if $d(DEBUG) TASMDEBUG=/zi LINKDEBUG=/v !else TASMDEBUG=/l LINKDEBUG= !endif
!if $d(MAKEDIR) IMPORT=$(MAKEDIR)\..\lib\import32 !else IMPORT=import32 !endif
$(NAME).EXE: $(OBJS) $(DEF) tlink32 /Tpd /aa /c $(LINKDEBUG) $(OBJS),$(NAME),, $(IMPORT), $(DEF)
.asm.obj: tasm32 $(TASMDEBUG) $(TASMOPT) $&.asm
$(RES): $(NAME).RC BRCC32 -32 $(NAME).RC
Файлы, необходимые для третьего примера
Файл описания dmenu.def NAME TEST DESCRIPTION 'Demo menu' EXETYPE WINDOWS EXPORTS WndProc @1
Файл ресурсов dmenu.rc #include "resource.h "MyMenu MENU DISCARDABLE BEGIN POPUP "Files" BEGIN MENUITEM "Open", ID_OPEN MENUITEM "Save", ID_SAVE MENUITEM SEPARATOR MENUITEM "Exit", ID_EXIT END MENUITEM "Other", 65535 END
Файл заголовков resource.h #define MyMenu 101 #define ID_OPEN 40001 #define ID_SAVE 40002 #define ID_EXIT 40003
Файл компиляции makefile # Make file for Turbo Assembler Demo menu # make -B # make -B -DDEBUG -DVERN for debug information and version NAME = dmenu OBJS = $(NAME).obj DEF = $(NAME).def RES = $(NAME).res !if $d(DEBUG) TASMDEBUG=/zi LINKDEBUG=/v !else TASMDEBUG=/l LINKDEBUG= !endif !if $d(VER2) TASMVER=/dVER2 !elseif $d(VER3) TASMVER=/dVER3 !else TASMVER=/dVER1 !endif !if $d(MAKEDIR) IMPORT=$(MAKEDIR)\..\lib\import32 !else IMPORT=import32 !endif $(NAME).EXE: $(OBJS) $(DEF) $(RES) tlink32 /Tpe /aa /c $(LINKDEBUG) $(OBJS),$(NAME),, $(IMPORT), $(DEF), $(RES) .asm.obj: tasm32 $(TASMDEBUG) $(TASMVER) /m /mx /z /zd $&.asm $(RES): $(NAME).RC BRCC32 -32 $(NAME).RC
Применение MQSeries
Возможности архитектуры очередей сообщений позволяют применять MQSeries как в процессе интеграции готовых приложений, так и для разработки совершенно новых систем, управляемых сообщениями. Можно перечислить следующие типичные задачи: интеграция приложений в распределенной гетерогенной среде; организация взаимодействия приложений, работа которых разделена во времени; сложные распределенные и/или распараллеленные процессы обработки; задачи гарантированной доставки данных; поддержка мобильных клиентов.
Многие финансовые организации и учреждения используют сегодня MQSeries в качестве базового транспорта для передачи данных внутри банковских приложений и между ними. К числу пользователей IBM MQSeries принадлежат Центральный Банк РФ и Национальный Банк Республики Беларусь.
Вероятно, крупнейшей в стране распределенной информационной инфраструктурой располагают российские железнодорожники. Сегодня разработки на базе MQSeries ведутся в различных организациях МПС, а из готовых продуктов можно упомянуть систему предупреждений, разработанную фирмой DigitalDesign для Октябрьской железной дороги. В основе этой системы лежит построенная на базе MQSeries сеть передачи данных, которая обеспечивает гарантированную передачу предупреждений между службами железной дороги с контролем передачи, доставки и прочтения сообщений.
В качестве типичных примеров использования MQSeries в России можно также указать ряд применений MQSeries вместе с прикладными системами, функционирующими на базе системы групповой работы и электронной почты Lotus Notes.
Рыбки.
Те, кто уже имел дело с инструментальными средствами компании Borland, прекрасно знают этот пример, который Borland предоставляет для всех своих визуальных инструментов. Рыбки (Fish Facts) - это база данных с информацией об аквариумных рыбках с их внешним видом (картинка), описанием (memo-поле), и несколькими характеризующими записями.
Borland включает пример с этой базой данных во все свои инструменты. Такой пример шел в составе Paradox, Visual dBase, Delphi и C++. Компания Epsylon Technologies включает аналогичный пример в поставку библиотеки визуальных HTML-компонент для Delphi.
Итак, нашей ближайшей целью будет попытка создания Web-сервера, публикующего информацию из базы данных о рыбках в своих HTML-страницах. Мы хотели бы создать такой Web-сайт при помощи минимума усилий, и, несмотря на то, что Borland Delphi - это инструмент программирования, при минимуме программирования. То есть мы хотели бы иметь возможность создать такую систему, чтобы нашу базу данных мог увидеть на своем Internet-браузере удаленный клиент, например, лондонец или сахалинец.
Для начала поместим стандартные невизуальные объекты TDataSource и Ttable на форму. Эти невизуальные элементы позволяют осуществить коннект с источником данных уже на этапе проектирования. TDataSource и TTable входят в стандартную поставку Delphi, так что мы не делаем пока что ничего необычного для стандартного цикла дельфийской разработки.
Настроим эти элементы. Свойство TableName невизуального объекта Table1 установим в Biogif.db. Это имя нашей базы данных в парадоксовском формате. В качестве источника данных
можно установить и любой SQL-сервер, например Oracle или MS SQL, но пока что мы не будем этого делать - сделаем пример как можно проще. Теперь сделаем активным соединение, для чего установим свойство Active в True. Элемент DataSource1 настроим на Table1, установив свойство DataSet в Table1.
Теперь можно подключать визуальные компоненты. Если бы нашей целью было создать обычное приложение, мы бы воспользовались стандартными элементами, находящимися на странице DataControls в палитре компонент.
Однако, мы хотим создать Internet/ Intranet приложение, поэтому надо выбирать страницу DB HTML.



Смысл этих элементов вот в чем: Приложение, изготовленное в Delphi, в момент своего использования управляется сервером Baikonur. Для того, чтобы сервер мог получать и передавать информация от браузера приложению и наоборот, необходим обеспечивающий такую связь элемент. Таким элементом и является THTMLControl. Вторым очень важным элементом является THTMLPage. В его функции входит раздача и передача информации, полученной от клиентского браузера или передаваемой клиентскому браузеру, но касающейся конкретных элементов на HTML странице. В принципе, мы можем не делать никаких дополнительных настроек этих элементов и удовольствоваться тем, что установлено по умолчанию.
А вот теперь пора транслировать! После трансляуции мы получаем модуль .exe, который надо поместить в соответствующую рабочую директорию Baikonur.

Контекст вашей сессии сохранился, и вы увидите ту рыбку, на которую переместились последним вашим нажатием на кнопку HTMLNavigator. Полезнейшее свойство, особенно, если вы имеете дело с ненадежным модемным соединением! Если бы мы успели изготовить еще пару программ за это время, мы могли бы переключаться между ними, указывая разные URL, и не теряя контекста для каждой из них. А где же HTML? - скажете вы. Можно заметить, что мы изготовили приложение, динамически генерирующее HTML-страницы, абсолютно не зная HTML. Однако, если хочется создавать изысканно выглядящие Internet-приложения, HTML придется освоить. Вы можете создавать свои собственные HTML-компоненты, или подправлять внешний вид страниц, генерируемый вашим приложением, расставляя вручную в шаблоне соответствующие теги HyperText Markup Language. Библиотека Delphi HTML Controls может не содержать какого-либо элемента, который поддерживает какой-нибудь из браузеров. Например, в библиотеке отсутствует элемент <marquee>, поддерживаемый Microsoft Internet Explorer'ом. Для того, чтобы поместить такой тег на форму нужно воспользоваться компонентом HTMLLabel. Необходимо произвести следующую последовательность действий: поместите HTMLLabel в нужное место на форме, установить свойство Preformat в False, в свойстве Caption указать '<marquee> Это текст бегущей строки </marquee>' В Microsoft Internet Explorer этот элемент отобразится в виде бегущей строки. Нам осталось проверить последнее - действительно ли нашу базу данных с информацией о рыбках можно рассматривать при помощи браузеров от различных производителей? На рынке в основном конкурируют два браузера - Netscape Navigator и Microsoft Internet Explorer. В старшие версии сервера Baikonur компания Epsylon Technologies включает браузер Ariadna компании AMSD. Давайте проверим, что у нас получилось.

Рассылка оперативной информации.
Этот пример иллюстрирует очень полезный режим, который, к сожалению, поддерживает на сегодня только Netscape Navigator. Поэтому, когда вы будете запускать пример приложения с названием multi.exe, воспользуйтесь браузером от компании Netscape.

Обычно, когда вы работаете с каким-либо браузером, ваш сеанс работы представляет собой последовательность соединений и разъединений (connect и disconnect), как показано на рис.11.
Если вы будете запускать изготовленный нами пример с рыбками, и еще несколько ваших коллег также попробуют одновременно с вами убедиться в том, что ваш пример работает, обращаясь к серверу с запросом "http://myserveraddress/multi.exe", то для каждого клиентского запроса будет создано отдельное приложение (см. Рис 12)

Рисунок 12. Запуск однопользовательского приложения
Приложение multi.exe работает в несколько ином режиме. Как только ваш Netscape Navigator соединился с сервером, запросив "http://myserveraddress/multi.exe", сервер запускает приложение multi.exe и не разрывает соединение, как происходит обычно. Приложение multi.exe периодически (раз в секунду) рассылает сформированный им информационный экран всем пользователям, подключившимся к программе. В отличие от примера с рыбками, приложение multi.exe является многопользовательским. Это означает, что если оно уже было запущено под управлением сервера Baikonur, то каждый следующий клиент, набирая "http://myserveraddress/multi.exe", не вызывает нового запуска приложения, а подключается к уже существующему. Приложение Multi.exe фактически является многопользовательским, или, говоря другими словами, многопользовательским прикладным сервером.

Рисунок 13. Многопользовательское приложение
Разберемся с тем, что все-таки делает multi.exe. Multi.exe, будучи один раз запущенным, занимается тем, что генерирует синусоиду, накладывая на уровень сигнала еще и кое-какой шум. Одновременно с генерацией программа строит график значений синусоиды и рассылает полученную HTML-страничку всем клиентам, кто к ней подключился. Очевидно, что прикладной пользы от сервера multi.exe нет никакой. Однако, если вам понадобится строить систему, в которой клиентам необходимо оперативно получать постоянно меняющуюся информацию, программу multi можно будет взять за основу.

Рисунок 14. В многопользовательском приложении динамически формируемая страничка рассылается каждому подключенному пользователю.
Заметьте, тем не менее, что в программе multi.exe пользователи не взаимодействовали между собой. А можно ли организовать такое взаимодействие?
CHAT-сервер.
Да, конечно же, можно. В набор примеров в коробке с Baikonur Web App Server for Delphi входит и такой пример. Это пример построения многопользовательского специализированного сервера для организации многоканальных разговоров в Internet. В данном случае все клиенты так же, как и в предыдущем примере, будут находиться в постоянном соединении с сервером, но сервер попутно еще и принимает строки, вводимые каждым клиентом, а затем рассылает их всем, находящимся в соединении. Таким образом, все видят ход беседы, находясь в самых разных местах земного шара.