Базы данных ДП АСУТП и задачи управления информационными потоками
Большинство СУБД ДП АСУТП используют модели набора сущностей или иерархическую, а не распространенную в остальных классах систем хранения данных реляционную [1]. Это связано с более высоким быстродействием выборки данных, простотой программной реализации, возможностью отразить в иерархии групп данных структуру автоматизируемого производства, наличием методов относительной адресации. При использовании модели набора сущностей область хранения данных организована линейно, но производится упорядочивание объектов с использованием методов наименования, а логические взаимосвязи между ними с необходимостью приводят к построению некоторого графа. Исходя из этого, в данной работе рассматривается класс так называемых объектно-иерархических СУБД, предоставляющих механизмы упорядочивания хранимых объектов и программный интерфейс манипулирования ими.
База данных ДП АСУТП является как приемником, запрашивающим данные от внешних систем, так и их пассивным источником и таким образом выполняет роль маршрутизатора информационных потоков от систем автоматики и телемеханики к графическим приложениям, системам коммерческого учета и планирования производства, экспертным системам. При этом возникают общие для систем хранения и обработки данных задачи: выполнение функциональных операций; поддержание целостности и эквивалентности реплик данных; а также специализированные – взаимодействие с подсистемой информационного обмена и т.п.
Обзор методов моделирования аспектов
Как отмечают авторы [16], в то время как существует поддерживающий АО- концепции язык программирования AspectJ [5], отсутствует реализованный язык моделирования, поддерживающий проектирование AspectJ-программ. Предложениям по разработке подобного языка посвящено большое количество работ, представленных на различных конференциях в 1998-2002 гг.
Подавляющее большинство исследователей предлагают основываться на существующем стандарте UML [2] и применить существующие в нем механизмы расширения графической нотации сущностей и отношений (стереотипы, ограничения, помеченные значения) для описания дополнительных концепций AO-проектирования.
Так, в работе [15] предлагается ввести три новых концепции: группы (для целей классификации гетерогенных и распределенных сущностей), пересекающие отношения (позволяющие программисту определить “точки пересечения” аспекта с функциональной программой), аспектные классы (реализующие расширения программы в точках пересечения). Графически это предполагает использование имеющихся в UML элементов: классов и ассоциаций с добавлением стереотипов “group”, “pointcut”, “aspect”. Для методов аспектного класса вводятся стереотипы “before”, “after”, “around”, описывающие момент их вызова по отношению к вызову “пересекаемых” функций, а также предлагается набор правил определения и интерпретации семантики ролей и кратностей для пересекающих отношений.
В [12] рассматривается выделение аспектов в программной системе. Примеры диаграмм в этой работе похожи на приводимые в [15]: аспект рассматривается как диспетчер взаимодействия двух взаимозависимых классов и других, предоставляющих некоторую функциональность. Но, в отличие от [15], в модель явно вводится понятие “точки пересечения”, которую предлагается моделировать как вариант класса, а не как вариант ассоциации, более подробно рассмотрены “точки соединения” – места взаимодействия с аспектом, прерывания/возобновления выполнения основной программы. “Точки соединения могут быть объединены для построения интерфейса аспекта, также как множество интерфейсов в UML могут быть объединены в форму интерфейса класса”.
Вводится понятие парных (conjugated) точек соединения, в которых происходит вызов методов с одинаковыми сигнатурами, но направления потока управления противоположны (в которых управление передается аспекту и возвращается им).
С. Кларк и Р. Уолкер предлагают свой вариант нотации [8] для описания аспектов средствами UML. Они предлагают использовать параметризируемые пакеты (что само по себе является непредусмотренным расширением UML) со стереотипом “subject”, поскольку в принципе рассматривают аспекты как элементы субъектно-ориентированного проекта. Внутри пакета могут быть размещены диаграммы классов и взаимодействия, что позволяет графически показать поведение программы после связывания. Такой пакет является в терминологии авторов “композиционным шаблоном”. При этом, “параметризируя проектный субъект и обеспечивая механизм для привязки этих параметров к элементам модели в других проектных субъектах, мы можем определить композицию пересекающего поведения с основным проектом способом, допускающим повторное использование”. Предлагаемая семантика (отношение композиции, расширяемое строкой bind) оперирует классами и методами связываемых субъектов.
В [16] авторы рассматривают моделирование “пересекающих эффектов” отдельно в структуре типов и в поведении некоторой системы. Оригинальность их подхода заключается в предложении использовать параметризируемые, помеченные стереотипом “introduction” кооперации для определении свойств (атрибутов, операций) и отношений каждого из “пересечений” аспектных и обычных классов. Параметр кооперации используется для определения правил связывания (фактически – инстанцирования кооперации и ее встраивания в существующую систему классов). Помимо этих коопераций, в аспектных классах вводятся, независимо от методов, элементы со стереотипами “pointcut” и “advice”: “точки пересечения” и “извещения”, определяющие пересечение логики аспекта и программной системы, и вводящие механизм перехвата управления. Предложенная нотация базируется на концепциях языка AspectJ, но является излишне усложненной.
Разработчики UML указывают, что “ На практике для именования класса используют одно или несколько коротких существительных, взятых из словаря моделируемой системы” [2]. Аналогично, в большинстве рассмотренных работ имя аспектного класса является наречием и показывает выполняемую операцию.
Помимо рассмотренных выше четырех работ, предлагающих проработанные, готовые к практическому применению графические нотации, доступно большое количество статей теоретической направленности. Так, в [4] делается попытка формализовать использование средств расширений UML для специфицирования понятий АО-методологии. Для этого используется понятие “профиля” UML – механизма, позволяющего описать правила использования средств расширения языка в некоторой предметной области. Расширяя метамодель UML, авторы определяют набор стереотипов и их приложение к таким элементам метамодели, как класс и ассоциация. Авторы [17] также предлагают расширить метамодель UML для описания аспектных классов и отношений, но основной акцент сделан на предложении основанного на правилах XML языка разметки для описания проектных моделей, в частности, содержащих аспекты. Выгоды его введения обосновываются необходимостью наличия “нейтрального по отношению к приложениям формата” для коммуникации между разработчиками, облегчением повторного использования описаний аспектов, а также их разделением между различными средствами проектирования, связывания, кодогенерации. Комплексным подходом отличается статья известных разработчиков из IBM У. Харрисона, П. Терра и Г. Оссхера [9], в которой они рассматривают способы, какими информация об аспектах может быть отражена на различных диаграммах UML. Здесь же следует упомянуть работы С. Кларк [6,7], в которых она “представляет подход к разработке систем, базирующийся на объектно-ориентированной модели, но расширяющий ее добавлением новых возможностей декомпозиции”. В докладе [10] представлен прототип автоматизированного средства для преобразования высокоуровневых моделей UML, поддерживающих абстракции АОП, к низкоуровневым детализированным моделям, по которым может быть сгенерирован программный код, т.е.предложено проводить связывание на уровне моделей.
Целью следующей части настоящей статьи является дать представление о применимости АО-методов в обработке информационных потоков в объектно-ориентированной среде, вариантом реализации которой является объектная (объектно-иерархическая) база данных программного комплекса диспетчерского пункта (ДП) АСУТП. При составлении диаграмм мы будем придерживаться нотации, предложенной в [15].
Реализация функциональных операций
Простейший случай использования аспекта – реализация некоторого функционального требования, необходимого разным (не имеющим общего базового) классам. В этом случае аспект становится похож на статический класс-утилиту (utility class), с более четко формализованным в проекте правилом его использования.
Для примера рассмотрим класс, хранящий некоторое значение и его метку времени, имеющий два полиморфных метода записи нового значения: один с передаваемой меткой времени, другой – без нее. Тогда в случае, когда метка времени не передана, необходимо определить текущее время системы и записать его. Для этих целей введем аспектный класс TimeStamping. Его можно показать на диаграмме классов (рис. 1а), при этом мы показываем связанность аспекта не с одним, а с группой классов, объединяет которые в данном случае только необходимость получения значения текущего времени. То, что в принятой нотации группа моделируется как вариант класса, а не пакета UML, позволяет указать для нее методы, подразумевая, что они присутствуют во всех классах, составляющих группу. (Здесь и далее мы задаем имя группы Signal, подчеркивая, что оперируем с множеством классов, хранящих значение некоторого аналогового, дискретного, логического измерения; единицу справочной информации или производную от этих значений величину). Диаграмма взаимодействия (рис. 1б) показывает последовательность выполняемых операций после выполнения связывания (генерации программного кода). При вызове метода SetValue(value) происходит “пересечение”; мы показываем это тем, что на “линии жизни” объекта класса Signal не отмечен фокус управления, который сначала переходит экземпляру аспектного класса, и только потом возвращается им.

Рис. 1. Реализация функциональных операций аспектным классом.
Другой пример связывания некоторого аспекта с каждым из некоторого набора объектов в индивидуальности – необходимость отслеживать факт изменения хранимого значения. Перехват вызова метода записи нового значения позволяет установить флаг наличия изменения. Программе-серверу, обрабатывающему запросы внешних систем на получение измененных данных, достаточно будет анализировать состояние данного флага, а не выполнять сравнения хранимых копий предыдущих переданных значений с текущими.
Синхронизация расчетов и изменений
В базах данных ДП АСУТП часто выполняемой операцией является расчет агрегированных значений; например, определение максимального значения из множества или расчет мгновенного расхода жидкости или газа, используя оперативные данные о давлении, его перепаде на диафрагме и температуре, а также ряд заданных нормативных поправочных коэффициентов. В модели мы можем отобразить это, установив ассоциацию один-ко-многим (часто соответствующей отношению контейнер-элемент) и использовав класс-ассоциацию Multiplexer (в который заложена логика преобразования нескольких исходных значений в одно производное). Объекты-элементы являются источниками данных для своего контейнера, в свою очередь, некоторая подсистема опроса систем автоматики является источником оперативных данных для них самих. Эти взаимосвязи можно показать, используя диаграмму классов UML (см. рис. 2).

Рис. 2. Типовые отношения классов БД ДП АСУТП.
В системе, управляемой событиями, при изменении хотя бы одного из значений, участвующих в расчете результата и хранящихся в объектах-элементах, должен происходить пересчет формулы и запись нового расчетного значения в объект-контейнер. Рассмотрим для примера расчет некоторого состояния по двум исходным логическим сигналам “открыт”, “закрыт” (см. рис. 3).

Рис. 3. Вариант алгоритма перерасчета агрегированного значения.
В рассмотренном алгоритме есть упущение – перерасчет результата происходит при поступлении первого же из изменений. В случае, когда произошло изменение обоих значений, выполнение промежуточного расчета формулы агрегирования с использованием одного нового и одного устаревшего значения избыточно, и, скорее всего, ошибочно. При этом мы не можем заранее утверждать, что всегда при поступлении нового значения одного из сигналов поступает и новое значение другого. Т.о., мы приходим к требованию отслеживать режим поступления обновлений. Для решения этой задачи можно предложить блокировать источником данных передачу сообщений об изменении значений в объектах-элементах на период записи всего множества поступивших обновленных значений.
Тогда события об изменении поступят в класс-контейнер после записи обеих новых значений и расчет будет выполнен два раза, но с актуальными данными. (Будучи уверенным, что при поступлении первого же из извещений актуальны оба значения, можно сократить количество перерасчетов до одного).
Однако проблема остается, если источник данных – не один объект, а множество, и на диаграмме мы рассматриваем связь “многие-ко-многим”. (Задача часто возникает при реализации субъектно-ориентированного подхода к проектированию базы данных ДП АСУТП, при котором вводится множество классов, содержащих наборы нормативно-справочных данных, описывающие один и тот же производственный объект при различных точках зрения (принципах декомпозиции предметной области), но которым требуется разделять оперативные данные о его состоянии). Передача (копирование) данных из источников получателям приводит к необходимости поддержания целостности.
Здесь мы приходим к классической ситуации введения аспекта – реализация в отдельном классе-источнике или получателе данных алгоритма отслеживания взаимодействия других пар объектов и синхронизации с ними исключительно затруднена. Цель – обеспечить синхронизацию обновления данных; желаемое поведение аспекта – реализовать “конвейерную передачу” обновлений по уровням иерархии и между поддеревьями БД.

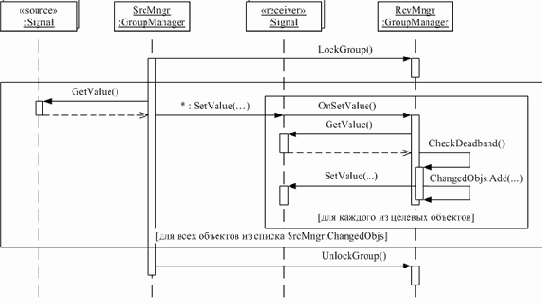
Сначала определим “точку пересечения”. Она одна – аспект перехватывает управление при попытке выполнения каким-либо из объектов-источников записи одного или нескольких новых значений; блокирует обработку новых значений в объектах-получателях, дает завершиться перехваченным методам SetValue(…), после чего ожидает в течение заданного интервала времени выполнения аналогичных действий другими объектами-источниками (см. рис. 4). По истечении времени ожидания происходит разблокирование всех объектов-получателей, в которые были записаны новые значения. Данная логика показана на рис. 5; отношение “многие-ко-многим” классов-источников и получателей данных рассматривается как множество отношений “один-ко-многим” их экземпляров. (Мы рассматриваем множества объектов – экземпляров некоторых классов, объединенные в две группы по их роли в частном информационном взаимодействии: источников и получателей данных; стереотипы “source” и “receiver” являются производными от базового “group”.
Имена групп ( при отличии стереотипа) совпадают, что подчеркивает единообразие входящих в них классов).

Отметим, что не требуется вводить точку пересечения с классом-получателем данных, поскольку нет необходимости перехватывать все выполняемые вызовы изменения данных в нем, а также использование стереотипа “around” для метода OnSetValue() аспектного класса: часть служебных операций выполняется до исполнения вызова SetValue(…), часть – после. Предложенное решение все еще содержит ряд недостатков: объект-источник зависим от реализации объекта-получателя; введение периодов ожидания плохо согласуется с событийной моделью; объект-получатель должен проверять попадание разности нового и предыдущего значений в “зону нечувствительности”; его структура усложняется средствами поддержки блокировок. Можно предложить вариант, свободный и от данных недостатков.
Для этого определим, что у каждой группы есть менеджер – экземпляр аспектного класса, выполняющий контракты каждого из классов группы, в т.ч. и вызов метода SetValue(…) для записи измененного значения в класс-получатель. Это позволяет также выполнять операции блокирования/разблокирования только по отношению к этому аспектному классу. На него же может быть переложено выполнение проверки “существенности” отличия нового значения от текущего в объекте. Тогда желаемое поведение, реализующее транзакционный подход к передаче массива данных, можно отобразить в виде :диаграммы (см. рис. 6). (На диаграмме показано взаимодействие только двух групп, хотя, разумеется, объекты и даже единственный объект группы-источника может являться записывать данные в несколько объектов, в т.ч. принадлежащих различным группам.) Поскольку, как отмечалось выше, каждая из групп может играть роль как источника, так и получателя данных, то на диаграмме классов достаточно показать связь аспекта и одной группы (см. рис. 7а).
Диаграмма, показывающая внутреннюю логику аспекта при разблокировании, приведена на рис. 7б.Отметим, что возможно одновременная блокировка группы несколькими менеджерами групп-источников: запись различных данных в один и тот же объект в любом случае не имеет смысла, а одновременная запись значений в различные объекты заблокированной группы несколькими источниками не приводит ни к каким отрицательным последствиям.

Сущность аспектно-ориентированного программирования
Методы объектно-ориентированного анализа и проектирования позволяют создать модель (архитектуру) информационной системы; провести анализ и создать на его основе модель предметной области. Типизации проектных решений служит широко распространенная концепция шаблонов, эффективные методы анализа и проектирования могут быть оформлены как стратегии.
Однако при разработке программной системы требуется также обеспечить выполнение различных требований к ней. Это могут быть требования к безопасности (необходимость авторизации при проведении транзакций клиент-сервер), качеству обслуживания, синхронизации операций чтения/записи и обеспечению целостности данных и др.
Ранее для специфицирования необходимости обеспечения некоторым классом определенных требований было введено понятие контракта [14]. Однако поддержка любого требования, не относящегося к сущности, описываемой классом, усложняет его структуру, более того, существует ряд требований, общих для многих различных классов или не являющихся функциональными, реализация которых в отдельных классах исключительно затруднена (такие требования называют “пересекающими” (crosscutting)). Требуется введение некоторого дополнительного программного “слоя”, на который было бы возложено выполнение “контрактных обязательств” классов, абстрагирующих сущности предметной области.
Для этого в 1997 г. группой разработчиков из Xerox PARC во главе с Г. Кикзалесом была предложена концепция аспектно-ориентированного программирования (АОП) [13]. Ими было явно введено понятие аспекта, которым является то свойство системы, которое не может быть явно реализовано в виде процедуры. “Аспекты имеют тенденцию не быть элементами функциональной декомпозиции системы, но скорее быть свойствами, которые системно воздействуют на производительность или семантику компонентов”. В этом аспекты противоположны компонентам, “имеющим тенденцию быть единицами функциональной декомпозиции системы”. Цель АОП – “поддержать программиста в четком разделении компонентов и аспектов друг от друга, обеспечивая механизмы, которые сделают возможным абстрагировать их и объединять для получения системы в целом”. (На русском языке концепции и преимущества АОП описаны в [3]).
В работе [11] рассматривается переход от контрактного проектирования к использованию аспектов. Имея в виду под словом “контракт” “спецификацию ограничений, которые должны быть соблюдены некоторой сущностью, запрашивающей услугу от другой сущности”, авторы указывают, что “обычно части проекта, которые реализуют определенный контракт, “рассеяны” (scattered) по всему проекту”. На те же проблемы “рассеивания”, а также на “запутывание” (tangling) структуры классов вследствие необходимости реализации в них механизмов поддержки требований, не связанных с описываемыми ими абстракциями, указывали С. Кларк и Р. Уолкер [8], подчеркивая, что “рассеивание и запутывание имеют негативное влияние на жизненный цикл разработки, с точек зрения возможностей понимания, отладки, развития, повторного использования” (классов и архитектуры системы в целом).
Неотъемлемой частью среды разработки, поддерживающей АО-парадигму, также является инструмент “связывания” (weaving), выполняющий генерацию результирующего программного кода (на этапе компиляции или даже во время выполнения) из двух, в общем случае независимых, проектов: реализующих функциональные требования и вынесенную в аспекты логику.
Для успешного применения любой техники программирования требуется не только ее поддержка языком программирования, но и возможность формализации принятых решений на этапе проектирования. Из этого следует необходимость наличия как минимум графической нотации для записи моделей, как максимум – методологии, формализующей процесс проектирования, и поддержки новой технологии в CASE-средствах разработки.
Взаимодействие с подсистемой информационного обмена
Взаимодействие “объект БД – модуль информационного обмена с внешними системами (далее – сканирования)” в ряде баз данных ДП АСУТП настраивается с использованием “списка сигналов”: в табличной форме объединяются индивидуальные параметры опроса каждого сигнала (тип данных, адрес в контроллере, периоды периодических опросов значений и изменений и т.п.). В других системах данная параметрическая информация сохраняется в самом объекте БД. Оба этих подхода обладают тем недостатком, что не используют естественно напрашивающую предположение об одинаковости параметров (коммуникационных, преобразования “сырых” данных) для однотипных объектов БД, т.е. экземпляров одного класса. Поэтому в данном случае аспектный класс используется как расширитель структуры класса БД (это отмечено отношением зависимости со стереотипом “extend”): он содержит таблицы соответствий класса и параметров сканирования, класса и правил преобразования полученных данных, а также список соответствий индивидуальных объектов и адресов во внешней системе (или правила получения адресов по имени объектов).
С другой стороны, от различных модулей сканирования требуется обеспечивать однотипное поведение при определенных событиях; например, качество значений всех объектов БД, получающих данные от внешней системы, с которой потеряна связь, должно быть установлено в “недостоверное”. Аспектный класс “пересекает” операции модуля сканирования, результаты которых влияют на прочие объекты БД, и реализует единообразную логику для различных приложений информационного обмена.
Иерархия классов отражает уровни абстракции
Иерархия классов отражает уровни абстракции сущностей предметной области, иерархия объектов (в БД ДП АСУТП) является информационной моделью автоматизируемого производства, технологического процесса. Для отражения различных точек зрения возможно разделение классов и построение нескольких подмоделей, используя различные принципы декомпозиции. Применение методов аспектно-ориентированного программирования позволяет отделить средства реализации контрактов каждого из классов (механизмов поддержки в них различных ограничений и требований к информационной системе в целом) от описываемых ими абстракций сущностей, за счет чего повысить степень надежности БД, производительность обработки и передачи данных, возможность повторного использования проектных решений.

Литература
Богданов Н.К. Тиражируемые программные комплексы для создания АСУТП. // Промышленные АСУ и контроллеры. 2000. №12. – С. 35-39
Буч Г., Рамбо Д., Джекобсон А. Язык UML. Руководство пользователя. М.: ДМК Пресс, 2000. – 432 с.
Шукла Д., Селлз С.Ф.К. АОП: Более эффективная инкапсуляция и повторное использование кода. // MSDN Magazine/Русская редакция. 2002. Спецвыпуск №1.
Aldawud, O., Elrad, T., Bader, A. A UML Profile for Aspect-Oriented Modeling. In proc. of Aspect-Oriented Programming Workshop at OOPSLA, 2001.
AspectJ Home Page.
Clarke, S. Composing Design Models: An Extension to the UML. In proc. of International Conference on the UML, 2000, pp. 338-352.
Clarke, S. Extending Standard UML with Model Composition Semantics. // Science of Computer Programming. Vol. 44, Issue 1 (July 2002), pp. 71-100
Clarke, S., Walker, R. Composition Patterns: An Approach to Designing Reusable Aspects. In proc. of ICSE 2001.
Harrison, W., Tarr, P., Ossher, H. A Position On Considerations in UML Design of Aspects. In proc. of Workshop on Aspect-Oriented Modeling with UML at AOSD, 2002.
Ho, W., Pennaneac'h, F., Jezequel, J., Plouzeau, N.
Aspect- Oriented Design with the UML. In proc. of Multi-Dimensional Separation of Concerns Workshop at ICSE, 2000, pp. 60-64
Jezequel, J., Plouzeau, N., Weis, T., Geihs, K. From Contracts to Aspects in UML Designs. In proc. of Workshop on Aspect-Oriented Modeling with UML at AOSD, 2002.
Kande, M.M., Kienzle, J., Strohmeier, A. From AOP to UML - A Bottom-Up Approach. In proc. of Workshop on Aspect-Oriented Modeling with UML at AOSD, 2002.
Kiczales, G., Lamping, J., Mendhekar, A., Maeda, C., Lopes, C., Loingtier, J., Irwin, J. Aspect-Oriented Programming. In proc. of ECOOP, 1997, LNCS 1241, pp. 220-242
Meyer, B. Object-Oriented Software Construction. New-York, NY: Prentice Hall, 1988.
Pawlak, R., Duchien, L., Florin, G., Legond-Aubry, F., Seinturier, L., Martelli, L. A UML Notation for Aspect-Oriented Software Design. In proc. of Workshop on Aspect-Oriented Modeling with UML at AOSD, 2002.
Stein, D., Hanenberg, S., Unland, R. Designing Aspect-Oriented Crosscutting in UML. In proc. of Workshop on Aspect-Oriented Modeling with UML at AOSD, 2002.
Suzuki, J., Yamamoto, Y. Extending UML with Aspects: Aspect Support in the Design Phase. In proc. of Aspect-Oriented Programming Workshop at ECOOP, 1999.
Интернет
Workshop on Aspect-Oriented Modeling with UML at AOSD’02.
Workshop on Multi-Dimensional Separation of Concerns (ICSE 2000) Aspect-Oriented Software Development Aspect-Oriented Programming
во многих ИСР под визуализацией
Например, во многих ИСР под визуализацией разработки подразумевается возможность разработчика поместить на экране кнопки или другие объекты, но ни одна из существующих сред не позволяет наблюдать иерархию классов приложения в виде графа, со связями, отображающими наследование. Изобилие же инструментальных средств в профессиональных средах тоже лишь отвлекает внимание, занимая пространство на экране. А это, по мнению разработчиков BlueJ, еще хуже, так как заставляет программиста мыслить не категориями ООП, а последовательностью строк кода, которая свойственна традиционному процедурному программированию, и щелчками мышкой для достижения нужного результата. К сожалению, проблемы не ограничиваются оболочками. В самом языке тоже есть несколько «узких мест», трудных для понимания новичка, например сигнатура метода
main:
public static void main (String[] argv);
В этой сигнатуре заложены сразу несколько понятий: статический метод, возвращаемый тип void, массив. Все это приводит к тому, что в самом начале обучения, когда студент еще ничего не знает о классах, методах, переменных, циклах и т. п. для наглядной демонстрации простейшего присвоения значения переменной необходимо создать хотя бы каркас c методом main. Преподавателю не остается ничего лучшего, как предложить аудитории поверить ему на слово, что этот метод должен быть объявлен так, а не иначе, так как при использовании стандартных ИСР нет возможности выполнить часть кода, не создав всего скелета класса.
Итак, существующие решения оказываются не вполне удовлетворительными: у J2SDK нет интерактивной оболочки, а большинству ИСР не хватает конструктивных решений.
В BlueJ все эти проблемы решены, и вот как это сделано.
Окно менеджера проекта состоит из вертикальной панели инструментов, расположенной слева, графа классов в центре и панели объектов внизу.
Приятно отметить, что окно менеджера проекта упрощено до предела и содержит только необходимые элементы. На мой взгляд, авторам удалось очень оригинально и остроумно продемонстрировать графически работу виртуальной машины (ВМ), отобразив ее в правом нижнем углу окна в виде спирали, напоминающей винт Архимеда (во время работы ВМ она движется и меняет цвет).
У этого «винта» есть и другое назначение: если дважды щелкнуть на нем при запущенном потоке, поток (и винт) остановится, и запустится отладчик. Это очень удобно при отладке «долгоиграющих» процессов и особенно при попадании в бесконечный цикл.
Классы проекта отображаются в виде прямоугольников и связей между ними. Цвет и штриховка прямоугольника указывают на состояние, в котором находится класс - модифицирован, откомпилирован или находится в стадии компиляции,- а вид стрелок -- на тип связи. Например, штриховка класса Student означает, что класс был модифицирован, а более темный фон класса Person - что в данный момент идет компиляция этого класса. Такой подход позволяет постоянно контролировать все, что происходит в BlueJ.
Для того чтобы приступить к редактированию класса, нужно дважды щелкнуть на соответствующем ему прямоугольнике, а по щелчку правой кнопкой мыши открывается контекстное меню, позволяющее создать экземпляр класса или выполнить один из его статических методов. Все это можно проделать независимо от того, готов ли весь класс полностью или только этот метод.
Если же создать экземпляр класса и поместить его на панель объектов, появляется возможность выполнять все нестатические методы объекта. Для этого необходимо вызвать один из конструкторов, например new Staff(). Таким образом, мы получаем возможность, создав метод и откомпилировав класс, сразу же проверить работоспособность этого участка кода.
В BlueJ есть набор шаблонов, позволяющих быстро создать «скелет» интерфейса, класса или аплета, а графические инструменты менеджера проекта позволяют добавить наследование простым «перетаскиванием» стрелок от одного класса к другому.
Окно отладчика содержит традиционный набор средств и, как отмечают авторы BlueJ, требует для ознакомления не более 15 минут, даже если пользователь совершенно незнаком с программированием.
Интересную возможность контролировать состояние объекта предоставляет команда Inspect из контекстного меню объекта. Она позволяет просматривать состояние полей объекта так же, как это делается в отладчике.
В состав BlueJ входят менеджер проекта, текстовый редактор и отладчик. Компилятор, виртуальная машина и некоторые другие средства «позаимствованы» у J2SDK. Кроме того, не забывайте: BlueJ - бесплатная, платформо-независимая среда. Проект постоянно совершенствуется. На момент написания этой статьи была доступна версия 1.1.3 (http://www.bluej.org/download/download.html).
Несмотря на то, что BlueJ использует многие инструменты из набора J2SDK, это среда с графическим интерфейсом. Так, например, интерактивный вызов директивы Tools ? Project Documentation приводит к созданию пакета документации в стиле Sun. Естественно, в любой момент можно открыть окно терминала или сеанса MS-DOS, в зависимости от платформы, и выполнить то же самое из командной строки.
Но и это еще не все. В настоящий момент разработчики сделали доступными исходные коды текстового редактора, а на сайте www.bluej.org ведется обсуждение нововведений. Так что у каждого есть возможность не только ознакомиться с исходными текстами, но и внести свою лепту в развитие BlueJ. А если вы серьезно заинтересовались разработкой, можете подписаться на рассылку новостей.
Конечно, у BlueJ есть свои проблемы. И целый список обнаруженных ошибок (а где их нет!). Так, например, в последней версии возникли проблемы с отладкой метода main.
Однако, учитывая масштабность проекта, его свободное распространение, а также доступность J2SDK (http://www.java.sun.com) и возможность установки среды на различные операционные системы, включая Linux, BlueJ вполне может составить конкуренцию многим ИСР. При этом, на мой взгляд, она подходит не только для начинающего, но и для профессионала, благодаря своей интеграции с J2SDK и полному набору инструментальных средств.
В заключение хочется добавить, что в настоящий момент на сайте BlueJ появилась русская версия руководства пользователя, а в ближайшее время появится полностью русифицированный интерфейс оболочки. Кроме того, хочется обратить внимание преподавателей наших ВУЗов на то, что в сочетании с Linux BlueJ позволяет создать полностью легальную среду разработки межплатформенных приложений.А это реальная возможность, во-первых, уйти от пиратских копий Turbo Pascal, на которых построено обучение в большинстве институтов, а во-вторых, использовать самые современные технологии для разработки веб-приложений в учебном процессе.
Чтение
Чтение данных из хранилища производится так же, как и чтение из стандартного потока Delphi. Все, что для этого требуется, это создать объект TOleStream с использованием возвращаемого функцией IStorage.OpenStorage значения stm:
procedure TForm1.Button2Click (Sender: TObject); var Stg:IStorage; Strm:IStream; OS:TOleStream; S:String; begin OleCheck (StgOpenStorage ('Testing.stg',nil,STGM_READWRITE or STGM_SHARE_EXCLUSIVE, nil,0,Stg)); OleCheck (Stg.OpenStream ('Testing',0,STGM_READWRITE or STGM_SHARE_EXCLUSIVE,0,Strm)); OS:=TOleStream.Create (Strm); try SetLength (S,OS.Size); OS.ReadBuffer (Pointer (S)^,OS.Size); Edit1.Text:=S; finally OS.free; Strm:=nil; Stg:=nil; end; end;После выполнения этого кода мы увидим в Edit1ранее записанное нами: "This is the test".
Исследование хранилищ
Хорошо… мы создали хранилище, записали в него данные и прочитали их. Но мы сделали это, ЗНАЯ имя потока, в котором записаны наши данные. Но как быть, если мы не знаем структуры хранилища? Для этого в интерфейсе IStorage предусмотрен механизм перечисления элементов хранилища - он содержится в интерфейсе IEnumStatStg (указатель на который возвращается функцией IStorage.EnumElements):
function EnumElements (reserved1: Longint; reserved2: Pointer; reserved3: Longint;out enm: IEnumStatStg): HResult; stdcall;
Употребление этой функции происходит так:
OleCheck (Stg.EnumElements (0,nil,0,Enum));После этого используем только методы интерфейса IenumStatStg (Next, Skip, Reset, Close). Самым важным из этих методов на данный момент является для нас метод Next:
Next (celt:Longint; out elt; pceltFetched: PLongint): HResult; stdcall;
Он может принимать следующие параметры:
Celt - количество элементов структуры, которое будет извлечено при его вызове; Elt - массив-приемник элементов типа TstatStg; PceltFetched - указатель на переменную, в которую будет записано действительное количество извлеченных элементов.Для примера воспользуемся любым doc-файлом и перечислим его элементы:
procedure TForm1.Button2Click (Sender: TObject); var Stg:IStorage; Enum:IEnumStatStg; Data:TStatStg; begin OleCheck (StgOpenStorage ('D:.doc',nil,STGM_READWRITE or STGM_SHARE_EXCLUSIVE,nil,0,Stg)); OleCheck (Stg.EnumElements (0,nil,0,Enum)); try While Enum.Next (1,Data,nil)=S_Ok do ListBox1.Items.Add (Format ('%s (%d)',[Data.pwcsName,Data.cbSize])); finally Stg:=nil; Enum:=nil; end; end;Структура TStatStg содержит, помимо pwcsName и cbSize, следующие поля:
| pwcsName: POleStr; | название потока или хранилища |
| dwType: Longint; | тип элемента (флаги типа STGTY_*) |
| cbSize: Largeint; | размер конкретного элемента |
| mtime,ctime,atime: TFileTime; | дата модификации, создания, последнего доступа |
| grfMode: Longint; | флаг доступа |
| grfLocksSupported: Longint; | не используется в хранилищах |
| clsid: TCLSID; | идентификатор класса хранилища |
| grfStateBits: Longint; | статусные биты |
| reserved: Longint; | зарезервирован |
Описанные интерфейсы и методы помогут вам не только использовать уже существующие COM-хранилища (такие как документы MS Office), но и создавать собственные,- благодаря чему ваши данные будут храниться в компактном и согласованном виде.
Когда хранилище открыто…
Рассмотрим более подробно методы интерфейса IStorage.
Создание потока - IStorage.CreateStream.
function CreateStream (pwcsName: POleStr; grfMode: Longint; reserved1: Longint;reserved2: Longint; out stm: IStream): HResult; stdcall;
Открытие потока - IStorage.OpenStream:
function OpenStream (pwcsName: POleStr; reserved1: Pointer; grfMode: Longint;reserved2: Longint; out stm: IStream): HResult; stdcall;
параметры:
pwcsName - название потока; grfMode - флаги доступа; reserved1, reserved2 - соответственно; stm - указатель на созданный поток.Можем приступать к чтению (записи) данных из (в) потоков посредством интерфейсов IStream. Тут можно заметить до боли знакомые методы работы с потоками: Read, Write, Seek… - а если так, то почему бы не перевести эти методы в более простую и понятную объектную форму? Для этого воспользуемся наработками Borland, собранными в модуле AxCtrls.pas (точнее - классом TOleStream, который интерпретирует вызовы методов интерфейса IStream в соответствующие методы класса Tstream).
А чтоб не быть голословным - приведу небольшой пример:
Implementation Uses ActiveX,AxCtrls,ComObj; procedure TForm1.Button1Click (Sender: TObject); var Stg:IStorage; Strm:IStream; OS:TOleStream; S:String; begin OleCheck (StgCreateDocfile ('Testing.stg',STGM_READWRITE or STGM_SHARE_EXCLUSIVE,0,Stg)); OleCheck (Stg.CreateStream ('Testing',STGM_READWRITE or STGM_SHARE_EXCLUSIVE,0,0,Strm)); OS:=TOleStream.Create (Strm); try S:='This is the test'; OS.WriteBuffer (Pointer (S)^,Length (S)); finally OS.free; Strm:=nil; Stg:=nil; end; end; end.В этом фрагменте мы создаем новое хранилище с одним потоком, в который записываем строку S. Естественно, ничто не мешает нам написать например:
Image1.Picture.Bitmap.SaveToStream (OS)- и тем самым записать в поток Testing изображение (вот она - "универсальная мусоросвалка"). Теперь ненадолго отвлечемся от Delphi и посмотрим на наш файл с точки зрения, скажем, Far (или VC)… Посмотрели? Если там же открыть любой документ Word (Excel), убедимся, что структура будет такой же, что и в нашем файле. Проверка принадлежности файла к формату хранилищ проводится с использованием функции StgIsStorageFile из ActiveX.pas:
function StgIsStorageFile (pwcsName: POleStr): HResult; stdcall;
Результат:
S_OK (0) - файл является хранилищем данных; S_FALSE (1) - файл не является хранилищем.Кроме того, эта функция может принимать значения STG_E_INVALIDFILENAME (если имя задано неправильно) и STG_E_FILENOTFOUND (если файла с таким именем не существует).
Определения

Структурированные хранилища данных - это файлы особой "самодокументированной" структуры, в которых могут мирно уживаться разнородные данные (от простого текста до фильмов, архивов и… программ). Поскольку эта технология является неотъемлемой частью Windows, доступ к ней возможен из любого поддерживающего технологию COM средства программирования. Одним из таких инструментов является Delphi, на основе которого будет описана технология доступа к структурированным хранилищам данных.
COM-хранилища напоминают иерархическую файловую систему. Так, в них есть корневое хранилище (Root Entry), в котором могут содержаться как отдельные потоки ("файлы"), так и хранилища второго уровня ("каталоги"). В них, в свою очередь,- хранилища третьего уровня ит.д. Управление каждым хранилищем и потоком осуществляется посредством отдельного экземпляра интерфейса: IStorage - для хранилищ и IStream - для потоков. Рассмотрим конкретнее некоторые операции, реализуемые этими интерфейсами.
Создание и открытие хранилищ
Создание хранилищ осуществляется с использованием функции StgCreateDocFile из модуля ActiveX.pas:
function StgCreateDocfile (pwcsName: POleStr; grfMode: Longint;
reserved: Longint; out stgOpen: IStorage): HResult; stdcall;
где:
pwcsName - название хранилища (т. е. название файла); grfMode - флаги доступа (комбинация значений STGM_*); reserved - он и в Африке RESERVED; StgOpen - ссылка на интерфейс IStorage нашего главного хранилища.Результат функции как всегда транслируем в исключения Delphi посредством OleCheck.
Для открытия хранилища используется функция StgOpenStorage:
function StgOpenStorage (pwcsName: POleStr; stgPriority: IStorage;
grfMode: Longint; snbExclude: TSNB; reserved: Longint;
out stgOpen: IStorage): HResult; stdcall;
параметр stgPriority указывает на ранее открытый экземпляр главного хранилища (почти всегда nil).
Альтернативы
На рынке свободно распространяемых программ CVS практически нет конкурентов. Однако из-за почтенного возраста (первые версии CVS появились в 1986 г.) появилась небольшая, но ясно видная ниша для конкурирующих продуктов. Дело в том, что CVS не поддерживает несколько удобных (некоторые даже считают их критичными) возможностей, например, версионность каталогов - отслеживание истории файлов с учетом их переименования, а также поддержку "наборов изменений" (changesets). Кроме того, разработка CVS в последнее время несколько приостановилась, в нем давно не появляется новых крупных возможностей (впрочем, это не означает, что существующих возможностей не хватает). Есть несколько коммерческих продуктов, поддерживающих примерно тот же набор возможностей, что и CVS. Два, на мой взгляд, самых известных - это Perforce () и Rational ClearCase (). В конце статьи приведена ссылка на каталог, содержащий ссылки на большое количество систем управления версиями.
В настоящий момент активно ведется разработка того, что когда-нибудь придет на смену CVS: . Этот проект, Subversion, разрабатывается с учетом положительных сторон CVS, у него новое, не страдающее от "старческих болезней", дерево исходников, некоторые из его разработчиков в прошлом участвовали в разработке CVS. Конечно же, Subversion будет распространяться с исходными текстами и по свободной лицензии. Я очень надеюсь, что этому проекту будет сопутствовать успех! Но в любом случае CVS будет использоваться еще очень и очень долго.
Несколько разработчиков
CVS изначально разрабатывалась с учетом возможности работы над проектом нескольких разработчиков. Дело в том, что вы можете извлечь из одного репозитория несколько рабочих копий -- по одной на каждого программиста. Очевидно, что в большинстве случаев разные программисты будут работать над разными частями проекта. Каждый из них будет фиксировать изменения в своей части проекта, и они не станут натыкаться друг на друга в репозитории. Для того чтобы получить изменения, сделанные другими, нужно специально вызвать команду
$ cvs update
Если вдруг случайно Петя и Вася бросятся исправлять один и тот же кусок кода, и сделают это по-разному (сама по себе эта ситуация указывает на недостаток общения Пети и Васи друг с другом), то CVS обработает и эту ситуацию. Когда Петя зафиксирует свое исправление, CVS позволит ему сделать это. Когда Вася попытается зафиксировать свой вариант исправления, CVS обнаружит, что эти исправления перекрываются, и предложит ему обновить рабочую копию с помощью cvs update. Эта команда покажет, что в исправляемом файле произошел так называемый "конфликт" и пометит место конфликта в рабочей копии этого файла. Предположим, Петя решил, что важнее исправить синтаксис выводимого сообщения, а Вася -- что нужно использовать более простую функцию puts(). Конфликт будет выглядеть примерно так:
<<<<<<<<
printf("Hello, world!\n");
=========
puts("hello world!");
>>>>>>>>
Васе следует обсудить с Петей причину конфликта, договориться, какое из изменений важнее (или просто объединить их), затем убрать индикаторы конфликта (строчки из символов "больше", "меньше" и "равно"), оставить лучший из двух вариантов и, если нужно, зафиксировать окончательное изменение.
Многие пугаются, услышав о полуавтоматической обработке конфликтов. На самом деле практика показывает, что при совместной работе с использованием CVS конфликтов практически не возникает (я говорю на основании опыта двухмесячной работы трех программистов над одним проектом). За эти два месяца я наблюдал, ну может быть, три или четыре конфликта. Все они были простейшими и исправлялись за три минуты. Никаких проблем, связанных с совместной работой, замечено не было.
Несколько ветвей разработки
Через несколько месяцев, когда вы более-менее освоитесь с повседневным использованием CVS, вам все чаще станут вспоминаться виденные когда-то в документации и в речи старших товарищей словосочетания "стабильная ветка", "сольем изменения на ствол", "поддержка старых версий". Это означает, что вы уже готовы программировать одновременно две версии своей программы. Одна - стабильная, которая уже работает у заказчика, но время от времени требует небольших исправлений или доработок. Вторая - та, разработку которой вы продолжаете, которая будет называться версией 2.0, содержит новые возможности или вообще почти полностью переписана. На помощь приходит CVS, которая с самого начала разрабатывалась для поддержки нескольких ветвей разработки программы.
В какой-то момент вы объявляете, что выпущена Hello Version 1.0. Дистрибутив программы отправлен пользователю, а вам самое время приготовиться к дальнейшей разработке. Пометьте текущее состояние исходников:
$ cvs rtag HELLO-1-0-RELEASE hello
Во-первых, теперь вы всегда сможете вернуться к состоянию программы на момент релиза с помощью команды
$ cvs co -r HELLO-1-0-RELEASE hello
Во-вторых, что важнее, теперь вы сможете создать ветку разработки, в которой будете вести поддержку программы (выпуская версии 1.01, 1.02 и т. д.). Для этого используется команда cvs rtag с ключом -b:
$ cvs rtag -b -r HELLO-1-0-RELEASE HELLO-1-0 hello
Теперь в вашей текущей рабочей копии можно продолжать активную разработку Hello Version 2. Одновременно с этим от пользователя начнут поступать запросы на исправление ошибок, небольшие доработки etc. Создайте себе еще одну рабочую копию в каталоге hello-support:
$ cvs co -r HELLO-1-0 -d hello-support hello
Эта рабочая копия "помнит" о том, что при ее извлечении использовался идентификатор ветки (HELLO-1-0), и теперь все исправления, которые вы сделаете и зафиксируете, окажутся именно на ветке, не затрагивая основной ствол разработки. И наоборот, изменения, вносимые в вашу основную рабочую копию, не окажут влияния на ветки, которые существуют в репозитории.
Повседневное использование
Если ваша операционная система - Linux, то, скорее всего, CVS уже установлена на вашей машине или же может быть установлена в мгновение ока с помощью менеджера пакетов. Если вы используете Windows, то сходите на , и скачайте там клиента и графическую оболочку к нему (если хотите). Создайте репозиторий, руководствуясь инструкциями из обширной документации к CVS.
Теперь начнем создавать где-нибудь в отдельном каталоге (не каталоге с репозиторием!) рабочую копию. Создадим каталог для нашего проекта:
$ cvs co -l .
$ mkdir hello
и поместим его в репозиторий:
$ cvs add hello
Directory /home/cvsroot/hello added to the repository
Создадим внутри этого каталога файл с нашей программой:
=== hello.c ===
#include
int main() {
printf("hello world\n");
}
=== hello.c ===
и поместим этот файл под контроль версий:
$ cvs add hello.c
cvs add: scheduling file `hello.c' for addition
cvs add: use 'cvs commit' to add this file permanently
Проверим, что программа компилируется и выполняется. У нас появилась первая ревизия, вполне пригодная к помещению в репозиторий. Сделаем же это:
$ cvs commit -m "First revision" hello.c
RCS file: /home/cvsroot/myproject/hello.c,v
done
Checking in hello.c;
/home/cvsroot/myproject/hello.c,v <-- hello.c
initial revision: 1.1
done
Отлично. Теперь притворимся, что мы долго и трудно работали, исправляя грамматику сообщения, которое выводит на экран наша программа, и в результате наш исходник начинает выглядеть так:
=== hello.c ===
#include
int main() {
printf("Hello, world!\n");
}
=== hello.c ===
Что же изменилось? Спросим у CVS:
$ cvs diff -u hello.c
Index: hello.c
===============================================
RCS file: /home/cvsroot/myproject/hello.c,v
retrieving revision 1.1
diff -u -r1.1 hello.c
--- hello.c 2001/01/23 22:16:35 1.1
+++ hello.c 2001/01/23 22:19:08
@@ -1,5 +1,5 @@
#include
int main() {
- printf("hello world\n");
+ printf("Hello, world!\n");
}
Вот в таком вот формате ("унифицированном diff-формате") CVS показывает нам изменения, произошедшие с файлом с того момента, когда он последний раз "фиксировался" в репозиторий.
Легко видеть, что одна строка в файле была изменена: мы видим ее старое и новое состояния. Теперь, когда приветствием, выводимым программой, будет доволен любой корректор, можно зафиксировать и это изменение с помощью все той же команды:
$ cvs commit -m "Improved greeting" hello.c
Описание команд CVS выходит за рамки этой небольшой статьи, но в конце ее приведены ссылки на материалы, в которых эта тема обсуждается с недостижимой здесь полнотой. Я же вернусь к более абстрактному описанию сосуществования с системой контроля версий. Первое время, довольно продолжительное, можно безболезненно работать с буквально полудесятком команд CVS:
добавление файла в проект (cvs add); удаление его из проекта при помощи команды cvs remove (заметьте, что вся история изменений в этом файле будет сохранена!); просмотр изменений (cvs diff); фиксация изменений в репозитории (cvs commit); на должность пятой команды в данном случае претендуют почти все остальные команды в зависимости от личных предпочтений. Для получения максимального эффекта от использования CVS следует соблюдать определенную дисциплину. Фиксирование изменений должно происходить каждый раз, когда наличествует это самое изменение, четко определенное и завершенное.
Например, самый распространенный случай: исправлена ошибка. Следует просмотреть изменения (в этот момент вас могут поджидать самые любопытные сюрпризы, например, после многочасовой отладки вдруг может выясниться, что все изменение свелось к двум строкам в двух разных файлах, хоть вы и редактировали десяток этих файлов в поисках ошибки). Теперь нужно зафиксировать изменение, причем обязательно документировать его: CVS запустит для вас редактор и предложит ввести журнальное сообщение. Если вы вдобавок пользуетесь системами отслеживания ошибок (а это тема для отдельной статьи), то журнальное сообщение – отличное место, куда можно вписать номер исправленной ошибки или, например, ссылку на письмо, в котором пользователь сообщил об исправленной ошибке.
Старайтесь не фиксировать несколько ошибок одновременно (еще хуже в качестве журнального сообщения писать "Исправлено несколько ошибок" или "Куча исправлений").В то же самое время есть еще одна часто встречающаяся ситуация: предположим, что вы несколько часов писали новый довольно большой модуль, он в основном работает, и осталось внести буквально несколько изменений (или, например, уже поздно и пора идти домой). В этом случае можно смело фиксировать недоделанный файл, а в качестве комментария ставить "почти работает". Оставшиеся доделки чрезвычайно удобно будет внести уже в новую ревизию, используя команду просмотра изменений относительно "почти работающей версии". По крайней мере, к ней всегда можно будет вернуться.
Ссылки на дополнительную информацию
Домашняя страница CVS:
Основной ресурс по CVS на Open Directory:
Крупнейший ресурс по CVS на русском языке (документация, статьи, список рассылки):
Графический (а также обычный текстовый) CVS-клиент под Win32:
CVS-сервер под Win32:
Ссылки на другие системы управления версиями:
document.write('');
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
класс программных продуктов, нацеленных на
Системы управления версиями - класс программных продуктов, нацеленных на решение ряда задач, с которыми повседневно сталкивается каждый программист. С помощью систем управления версиями вы следите за изменениями кода вашего программного продукта в ходе его разработки, и можете управлять различными его состояниями: новая версия, работа над которой идет прямо сейчас; старая версия, которую придется поддерживать еще некоторое время; или же старая версия, интересная только историкам.
Программисты, чьи исходники контролируются системой управления версиями, чем-то неуловимо отличаются от остальных программистов. Они в каждый момент рабочего дня точно знают, что именно было сделано за день, а после исправления ошибки могут точно сказать, в каком именно месте кода была ошибка. Они не подвержены синдрому "работает - не трогай", потому что могут совершенно безболезненно ударяться в самые сложные эксперименты со своей программой. Они твердо знают, что в любой момент могут вернуться к "исходникам, которые работали", сколько бы экспериментов с новым кодом не было проведено. Более того, если пользователь вдруг захочет небольшое, крошечное изменение, когда программа находится в многообещающем, но совершенно нерабочем состоянии, то все, что для этого потребуется -- переключиться на стабильную ветку, исправить там, что надо и отдать пользователю, затем переключиться обратно на ствол разработки.
В этой статье речь пойдет о CVS (Concurrent Versions System) – одной из систем управления версиями, существующих на рынке. Я впервые начал использовать CVS около трех лет назад, программируя на Delphi, но имея довольно плотный опыт работы под Linux. С тех пор я сменил область деятельности на программирование для Web, участвовал в проектах с несколькими разработчиками, и использовал CVS в каждом своем проекте, сколь бы невелик он был, и даже сколь мало он ни был бы связан с собственно программированием. Признаться, сейчас я вообще не представляю себе, как можно программировать, если не контролируешь собственные исходники: даже этот небольшой текстовый файл со статьей уже имеет ревизию 1.1.
В лучших традициях UNIX CVS занимается относительно небольшим, четко определенным кругом задач, и делает это хорошо. Когда вы начнете использовать CVS, то заметите, что она совершенно не "настаивает" практически ни на чем, включая сам факт своего использования. Все, что вы обнаружите -- один служебный подкаталог в каждом каталоге вашего проекта, и куча преимуществ и услуг, которые предоставит CVS, если дать ему эту возможность.
Заключительная часть
CVS необычайно широко применяется при разработке подавляющего большинства современных проектов с открытым исходным текстом. Среди огромного списка операционных систем и программ: FreeBSD, XEmacs, XFree86, OpenSSL, выделяется, пожалуй, лишь ядро Linux, главный разработчик которой, Линус Торвальдс, в силу особенностей личности отказывается использовать какую бы то ни было систему управления версиями, кроме собственного мозга. Да и то, почти все остальные участники разработки держат свой собственный CVS-репозиторий, которым активно пользуются при разработке (здесь им помогает интересная возможность CVS: т. н. "ветки поставщика" (vendor branches)). Проект , обеспечивающий свободно доступную инфраструктуру для разработчиков свободного программного обеспечения, в качестве стандартной возможности предоставляет использование своего CVS-сервера. Вообще, количество инсталляций и пользователей -- одно из значительных преимуществ CVS.
Список литературы
Кузнецов С. Возвращение микроядерных операционных систем. Открытые системы #05/06 Кузнецов С. Блеск и нищета легковесных процессов. Computerworld №31/96 Кузнецов С. Менталитет программиста, или ностальгия по программированию. Computerworld №31/96 Любченко В. Блеск и нищета отечественного программирования. "СофтМаркет" № №10/97, стр. 6. Любченко В. Фантазия или программирование? "Мир ПК", №10/97, с.116-119.
Литература
Эндрю Троелсен. С# и платформа .NET. Библиотека программиста. - СПб. Питер, 2004. Н. Елманова, С. Трепалин, А. Тенцер. Delphi 6 и технология СОМ. - СПб. Питер, 2002. Техническая документация MSDN. Примеры классов.
Перехват событий Excel
Перехватывая события Excel, Вы получаете возможность отслеживать его состояние и контролировать некоторые действия. Например, Вы можете отследить закрытие рабочей книги и корректно отключиться от Excel, произведя очистку памяти и прочие завершающие процедуры. Для того, чтобы понять, как перехватывать события, проведем небольшой экскурс в события COM объектов. В этом отступлении я предполагаю, что читатель немного знаком с COM архитектурой, хотя это не обязательно, в конце статьи я приведу уже готовое решение, которое можно использовать в своих приложениях, даже не задумываясь о тонкостях COM.
Если объект (будь-то СОМ или RCW объекта .NET) хочет получать события другого COM объекта, то он должен уведомить об этом источник событий, зарегистрировав себя в списке объектов-получателей уведомлений о событиях. Для этого СОМ предоставляет интерфейс IConnectionPointContainer, содержащий метод FindConnectionPoint. С помощью вызова метода FindConnectionPoint, объект-получатель события получает "точку подключения" - интерфейс IConnectionPoint и регистрирует c помощью метода Advise свою реализацию интерфейса IDispatch, методы которого будут реализовываться при возникновении тех или иных событий. Excel определяет интерфейс, который должен реализовываться классом-приемником событий.
interface
["00024413-0000-0000-C000-000000000046"]
{
DispId(0x61d)]
void NewWorkbook(object Wb);
DispId(0x616)]
void SheetSelectionChange(object Sh, object Target);
DispId(0x617)]
void SheetBeforeDoubleClick(object Sh, object Target, ref bool Cancel);
DispId(1560)]
void SheetBeforeRightClick(object Sh, object Target, ref bool Cancel);
DispId(0x619)]
void SheetActivate(object Sh);
DispId(0x61a)]
void SheetDeactivate(object Sh);
DispId(0x61b)]
void SheetCalculate(object Sh);
DispId(0x61c)]
void SheetChange(object Sh, object Target);
DispId(0x61f)]
void WorkbookOpen(object Wb);
DispId(0x620)]
void WorkbookActivate(object Wb);
DispId(0x621)]
void WorkbookDeactivate(object Wb);
DispId(1570)]
void WorkbookBeforeClose(object Wb, ref bool Cancel);
DispId(0x623)]
void WorkbookBeforeSave( object Wb, bool SaveAsUI, ref bool Cancel);
DispId(0x624)]
void WorkbookBeforePrint(object Wb, ref bool Cancel);
DispId(0x625)]
void WorkbookNewSheet(object Wb, object Sh);
DispId(0x626)]
void WorkbookAddinInstall(object Wb);
DispId(0x627)]
void WorkbookAddinUninstall(object Wb);
DispId(0x612)]
void WindowResize(object Wb, object Wn);
DispId(0x614)]
void WindowActivate(object Wb, object Wn);
DispId(0x615)]
void WindowDeactivate(object Wb, object Wn);
DispId(0x73e)]
void SheetFollowHyperlink(object Sh, object Target);
DispId(0x86d)]
void SheetPivotTableUpdate(object Sh, object Target);
DispId(2160)]
void WorkbookPivotTableCloseConnection(object Wb, object Target);
DispId(0x871)]
void WorkbookPivotTableOpenConnection(object Wb, object Target); }
Таким образом наш класс - приемник событий должен реализовывать этот интерфейс и регистрировать себя используя IConnectionPointContainer и IConnectionPoint. Библиотека базовых классов .NET уже определяет managed-версии интерфейсов: для IConnectionPointContainer это UCOMIConnectionPointContainer, а для IConnectionPoint - UCOMIConnectionPoint, которые определены в пространстве имен - System.Runtime.InteropServices.
Регистрация класса-приемника событий будет выглядеть так:
// Объявляем ссылки на IConnectionPointContainer
UCOMIConnectionPointContainer icpc;
// и на IConnectionPoint
UCOMIConnectionPoint icp;
// Получаем ссылку на Excel
FExcel = Marshal.GetActiveObject("Excel.Application");
// Получаем ссылку на интерфейс IConnectionPointContainer
icpc = FExcel as UCOMIConnectionPointContainer;
// Получаем «точку подключения»
Guid guid = new Guid("00024413-0000-0000-C000-000000000046");
icpc.FindConnectionPoint(ref guid, out icp);
// Регистрируем класс - приемник событий, который реализует
// интерфейс с GUID ["00024413-0000-0000-C000-000000000046"]
// При этом наш класс получает уникальный идентификатор
// cookie, который нужно сохранить, чтобы иметь
// возможность отключиться от источника событий
icp.Advise(ExcelEventSink, out cookie);
Для отключения от событий достаточно вызвать метод Unadvise(), и передать ему в качестве параметра идентификатор cookie, который мы получили при регистрации нашего класса-приемника событий методом Advise:
icp.Unadvise(cookie);
Работа со страницами. Объект Range. Использование записи макросов для автоматизации Excel.
Страница имеет ссылку на объект Range, который, по сути представляет собой объект-диапазон ячеек. Через объект Range мы получаем доступ к любой ячейке, а также к ее свойствам. Но объект Range содержит массу методов, и и для позднего связывания нужно знать не только формат передаваемых им формальных параметров, но и точное название метода (или свойства, которое по сути дела является комбинацией методов). Иными словами, нужно знать сигнатуру метода, чтобы успешно вызвать его через позднее связывание. До сих пор мы использовали простые методы типа Open, Close, Save, с которыми, в принципе, все понятно. Они не содержат большое количество параметров, и список параметров интуитивно ясен.
Для того, чтобы узнать, какие методы поддерживает объект Range, можно воспользоваться утилитой tlbimp.exe, и импортировав через нее библиотеку типов Excel, открыть эту библиотеку в дизассемблере IL-кода ildasm.exe. Дизассемблер покажет нам объект Range и все его методы. Можно использовать более продвинутые утилиты сторонних разработчиков (например, всем известный Anakrino).
Но есть более простой способ, который позволит нам существенно сэкономить время. Это сам Excel, а точнее его запись макросов. Например, нам нужно отформатировать ячейки определенным образом, хотя бы так, как показано на рис.:

Рис. 2. Результат работы макроса.
Для этого открываем Excel, включаем запись макросов и форматируем указанные ячейки как нам вздумается. Полученный макрос будет выглядеть следующим образом:
Sub Макрос1()
'
' Макрос1 Макрос
' Макрос записан 17.04.2005 (Powerful)
'
Range("B3").Select
With Selection.Interior
.ColorIndex = 45
.Pattern = xlSolid
End With
Range("C3").Select
Selection.Font.ColorIndex = 3
Range("B3").Select
ActiveCell.FormulaR1C1 = "Привет"
Range("C3").Select
ActiveCell.FormulaR1C1 = "из NET!"
Range("B3:C3").Select
Selection.Borders(xlDiagonalDown).LineStyle = xlNone
Selection.Borders(xlDiagonalUp).LineStyle = xlNone
With Selection.Borders(xlEdgeLeft)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlEdgeTop)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlEdgeBottom)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlEdgeRight)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
With Selection.Borders(xlInsideVertical)
.LineStyle = xlContinuous
.Weight = xlThin
.ColorIndex = xlAutomatic
End With
End Sub
Как видно, здесь очень часто используется вызов метода Select у объекта Range. Но нам это не нужно, ведь мы можем работать с ячейками напрямую, минуя их выделение. Метод Select просто переопределяет ссылки, которые будут возвращаться объектом Selection. Сам объект Selection - это тот же самый Range. Таким образом, наша задача существенно упрощается, так как нам нужно просто получить ссылки на нужные объекты Range, получить доступ к их внутренним объектам и произвести вызов соответствующих методов или свойств, используя уже известный нам метод InvokeMember().
Возьмем, например следующий участок кода:
...
Range("B3").Select With Selection.Interior .ColorIndex = 45 .Pattern = xlSolid End With Range("C3").Select Selection.Font.ColorIndex = 3 ...
Данный код окрашивает цвет фона ячейки B3 в оранжевый, причем заливка ячейки - сплошная, а цвет текста ячейки C3 устанавливает в красный.
Попробуем реализовать этот участок в нашем приложении. Допустим, что мы успешно получили ссылки на нужную книгу и страницу.
Ссылка на страницу у нас храниться в переменной oWorksheet.
// Получаем ссылку на ячейку B3 (точнее на объект Range("B3")),
object oRange = oWorksheet.GetType().InvokeMember("Range", BindingFlags.GetProperty, null, oWorksheet, new object[]{"B3"});
// Получаем ссылку на объект Interior
object oInterior = oRange.GetType().InvokeMember("Interior", BindingFlags.GetProperty, null, oRange, null);
// Устанавливаем заливку (Аналог вызова
// Range("B3").Interior.ColorIndex)
oInterior.GetType().InvokeMember("ColorIndex", BindingFlags.SetProperty, null, oInterior, new object[]{45});
// Устанавливаем способ заливки (Pattern = xlSolid)
/* Для того, чтобы узнать значение константы xlSolid, можно посмотреть документацию, использовать описанный выше импорт библиотеки типов, а можно просто прогнать наш макрос в Visual Basic по шагам и посмотреть значение в контроле переменных, что существенно сэкономит Ваше время. */
// Задаем параметр xlSolid = 1;
object[] args = new object[]{1}
// Устанавливаем свойство Pattern в xlSolid
oInterior.GetType().InvokeMember("Pattern", BindingFlags.SetProperty, null, oInterior, args);
Для того, чтобы задать текст, можно использовать свойство Value объекта Range.
oRange.GetType().InvokeMember("Value", BindingFlags.SetProperty, null, oRange, new object[]{"Привет"});
Далее разбирать код я не буду, советую читателям самим поэкспериментировать с установкой свойств Excel из приложений .NET, по аналогии с приведенными здесь примерами. А сейчас перейдем к событиям Excel и их перехвату, используя позднее связывание.
Управление книгами и страницами.
Позднее связывание подразумевает, что нам неизвестен тип объекта, с которым мы хотим работать, а это значит, что мы не можем применять непосредственно обращаться к его методам и полям, используя оператор ".". Поэтому для вызова метода, нам необходимо знать его название и список формальных параметров, которые он принимает. Для вызова метода в классе Type предусмотрен метод InvokeMember(). Поэтому нам достаточно получить ссылку на экземпляр класса Type, описывающий тип объекта, с которым мы устанавливаем позднее связывание, и вызвать метод InvokeMember()/ Я не буду останавливаться подробно на этом методе, он достаточно хорошо описан в технической документации. Отмечу только самое необходимое, с которым мы будем непосредственно работать.
Метод InvokeMember() перегружен, и имеет три модификации.
public object InvokeMember(string name, BindingFlags flags, Binder binder, object target, object[] args);
public object InvokeMember(string name, BindingFlags flags, Binder binder, object target, object[] args, CultureInfo info);
public abstract object InvokeMember(string name, BindingFlags flags, Binder binder, object target, object[] args, ParameterModifier[] modifiers, CultureInfo info, string[] namedParameters);
В нашей работе мы будем использовать только первую модификацию метода. В качестве первого параметра метод получает строковое название метода, поля, свойства того объекта, с которым мы устанавливаем связь. При этом в названии не должно быть пробелов или лишних символов, кроме того, этот параметр чувствителен к регистру.
Второй параметр принимает на вход флаги, характеризующие связывание. Нам понадобятся только следующие флаги: BindingFlags.InvokeMethod - Найти метод, определить его точку входа, и выполнить передав ему массив фактических параметров. BindingFlags.GetProperty - Установить свойство BindingFlags.SetProperty - Получить значение свойства.
Третий параметр - binder - мы устанавливаем в null - он нам не нужен.
Через четвертый параметр - target - мы передаем ссылку на объект, к методу которого мы хотим обратиться.
Пятый параметр - args - это массив с параметрами, который принимает на вход вызываемый поздним связыванием метод, или массив, который содержит один элемент - значение свойство, которое мы устанавливаем.
Метод InvokeMember() возвращает результат выполнения метода или значение свойства.
Для управления книгами и страницами в первую очередь нужно получить ссылку на их коллекции.
Для получения ссылки на коллекцию книг необходимо выполнить следующий код (считается, что ссылка на oExcel успешно получена):
object oWorkbooks = oExcel.GetType().InvokeMember("Workbooks", BindingFlags.GetProperty, null, oExcel, null);
Объект oWorkbooks и есть managed-ссылка на коллекцию книг. Для получения доступа к конкретной книге выполняем следующий код, используя коллекцию книг:
// Доступ к книге по ее порядковому номеру
// Создаем массив параметров
object[] args = new object[1];
// Мы хотим получить доступ к первой книге Excel
args[0] = 1;
// Получаем ссылку на первую книгу в коллекции Excel
object oWorkbook = oWorkbooks.GetType().InvokeMember("Item", BindingFlags.GetProperty, null, oWorkbooks, args);
// Доступ к книге по ее названию
// (обратите внимание, что расширение в
// названии не указывается)
object[] args = new object[1];
// Указываем название книги, к которой мы хотим получить доступ
args[0] = "Книга1";
// Получаем ссылку на первую книгу в коллекции Excel
object oWorkbook = oWorkbooks.GetType().InvokeMember("Item", BindingFlags.GetProperty, null, oWorkbooks, args);
Если книг с указанным названием не существует, то данный код выбрасывает исключение. Для того, чтобы открыть, закрыть или создать книгу, воспользуемся соответствующими методами коллекции книг oWorkbooks, ссылку на которую мы уже успешно получили. Для создания новой книги у объекта oWorkbooks есть несколько модификаций метода Add. Если мы вызовем этот метод без параметров, то будет создана новая книга, имеющая имя, принятое по умолчанию, и содержащая количество страниц, также принятое по умолчанию.
//Создаем новую книгу
object oWorkbook = oWorkbooks.GetType().InvokeMember("Add", BindingFlags.InvokeMethod, null, oWorkbooks, null);
Для создания книги на основе шаблона, достаточно передать полное имя файла, содержащее этот шаблон:
// Заносим в массив параметров имя файла
object[] args = new object[1]; args[0] = "D:\MyApp\Templates\invoice.xls";
//Создаем новую книгу
object oWorkbook = oWorkbooks.GetType().InvokeMember("Add", BindingFlags.InvokeMethod, null, oWorkbooks, args);
Для открытия файла с книгой, воспользуемся методом Open объекта oWorkbooks:
// Открытие файла d:\book1.xls
// Заносим в массив параметров имя файла
object[] args = new object[1];
args[0] = "D:\book1.xls";
// Пробуем открыть книгу
object oWorkbook = oWorkbooks.GetType().InvokeMember("Open", BindingFlags.InvokeMethod, null, oWorkbooks, args);
Закрытие книги возможно с помощью метода Close объекта oWorkbook. При этом он принимает несколько необязательных параметров. Рассмотрим два варианта (Обратите внимание, что мы вызываем метод Close книги, а не коллекции книг, и target-объектом у нас выступает oWorkbook, а не oWorkbooks):
// Вариант 1. Закрываем книгу с принятием всех изменений
object[] args = new object[1];
// с принятием всех изменений
args[0] = true;
// Пробуем закрыть книгу
oWorkbook.GetType().InvokeMember("Close", BindingFlags.InvokeMethod, null, oWorkbook, args);
// Вариант 2. Закрываем книгу с принятием всех изменений
object[] args = new object[2]; args[0] = true;
// И под определенным названием
args[1] = @"D:\book2.xls";
// Пробуем закрыть книгу
oWorkbook.GetType().InvokeMember("Close", BindingFlags.InvokeMethod, null, oWorkbook, args);
Отмечу сразу, что сохранение произойдет только в том случае, если вы произвели какие-либо изменения в рабочей книге. Если Вы создали рабочую книгу и ходите ее сразу же закрыть, причем с сохранением под другим именем - у Вас ничего не выйдет. Excel просто закроет книгу и все. Для того, чтобы просто сохранить изменения в книге, достаточно вызвать для нее метод Save или SaveAs, передав последнему в качестве параметра имя файла, под которым нужно сохранить книгу.
// Просто сохраняем книгу
oWorkbook.GetType().InvokeMember("Save", BindingFlags.InvokeMethod, null, oWorkbook, null);
// Задаем параметры метода SaveAs - имя файла
object[] args = new object[2];
args[0] = @"d:\d1.xls";
// Сохраняем книгу в файле d:\d1.xls
oWorkbook.GetType().InvokeMember("SaveAs", BindingFlags.InvokeMethod, null, oWorkbook, args);
// Просто сохраняем рабочую книгу. По умолчанию новая книга без
// изменений будет сохранена в папку «Мои Документы»
// текущей учетной записи Windows
oWorkbook.GetType().InvokeMember("Save", BindingFlags.InvokeMethod, null, oWorkbook, null);
Для работы со страницами нам необходимо получить доступ к их коллекции. Естественно, мы уже должны иметь ссылку на рабочую книгу. Для получения ссылки на коллекцию страниц, нужно вызвать свойство Worksheets рабочей книги:
object oWorksheets = oWorkbook.GetType().InvokeMember("Worksheets", BindingFlags.GetProperty, null, oWorkbook, null);
Объект oWorksheets - это managed-ссылка на коллекцию страниц текущей книги. Зная ссылку на эту коллекцию мы можем получить доступ к конкретной странице по ее имени или порядковому номеру (Аналогично коллекции рабочих книг):
//Задаем порядковый номер страницы - 1
object[] args = new object[1];
args[0] = 1;
// Получаем ссылку на эту страницу
object oWorksheet = oWorksheets.GetType().InvokeMember("Item", BindingFlags.GetProperty, null, oWorksheets, args);
//Задаем имя страницы
object[] args = new object[1];
args[0] = "Лист1";
//Получаем ссылку на страницу с именем Лист1
oWorksheet = oWorksheets.GetType().InvokeMember("Item", BindingFlags.GetProperty, null, oWorksheets, args);
Вступление.
Многим разработчикам рано или поздно приходится сталкиваться с задачами, которые подразумевают использование Microsoft Excel (далее по тексту просто Excel) в своей работе. Не будем перечислять подобные задачи, думаю, читатель сам уже с этим столкнулся. Многие вопросы покажутся Вам очень знакомыми, кое-кто скажет, а зачем такие сложности? Ведь можно применить утилиту tlbimp.exe, импортировать библиотеку типов, создать RCW сборку, добавить на нее ссылку и вам станет доступно пространство имен Excel, со всеми RCW классами, которые отображают в себя "внутренности" Excel. Или еще проще, просто добавить ссылку на COM-объекты Excel в Visual Studio, и она сделает все сама. Все это хорошо, конечно. И просто. Но иногда возникают условия, когда описанное вкратце "раннее связывание" неприемлемо. И тогда на помощь приходит т.н. "позднее связывание", когда типы становятся известными не на этапе компиляции, а на этапе выполнения.
Описывать позднее связывание в этой статье нет смысла, в литературе, как и в Интернете достаточно материала по этой теме. По поводу языка, то все примеры приведены с использованием C#, но, надеюсь программисты, использующие в своей работе другие .NET языки, смогут разобраться в коде без особого труда.
Взаимодействие Microsoft Excel с приложениями .NET. Позднее связывание.
ведущий .NET-разработчик компании
Microsoft Certified Application Developer
Содержание:
с MS Excel взаимодействие COM
Мы рассмотрели в статье на примере с MS Excel взаимодействие COM и NET, используя позднее связывание. Используя аналогичный подход, можно организовать управление любым COM сервером. (Чаще всего автоматизируют приложения пакета MS Office и MS Internet Explorer). В приложенном к данной статье файле находится класс, с помощью которого можно организовать обработку событий Excel в любом приложении .NET.
Запуск и завершение работы Excel.
Запуск Excel и его корректное завершение - это самая первая задача, которую нужно решить программисту, если он собрался использовать Excel в своем приложении. Возможно, Excel уже запущен, и операция запуска уже не нужна, достаточно получить на него ссылку, и начать с ним работу. В получении ссылки на уже работающую копию Excel кроется один неприятный момент, связанный с ошибкой в самом приложении Excel (которую вроде бы исправлена в MSOffice 2003)[2]. Эта ситуация подробно описана в конце этой главы.
А сейчас по порядку.
В первую очередь Вы должны подключить к своему приложению два пространства имен:
using System.Runtime.InteropServices;
using System.Reflection;
Типы, которые необходимы для организации позднего связывания, описаны в этих пространствах имен. Один из них: класс Marshal, который предоставляет богатые возможности для организации взаимодействия между кодом с автоматически управляемой памятью (managed code), и объектами "неуправляемым кодом" (unmanaged code).
Для получения ссылки на процесс Excel, нужно знать GUID Excel. Однако можно поступить намного проще, зная программный идентификатор Excel: "Excel.Application".
Для получения ссылки на работающий Excel, воспользуйтесь статическим методом GetActiveObject(), класса Marshal:
string sAppProgID = "Excel.Application";
object oExcel = Marshal.GetActiveObject(sAppProgID);
Если Excel уже запущен (COM-объект Excel присутствует), то вызов данного метода вернет ссылку на объект-отображение Excel в .NET, которые Вы сможете использовать для дальнейшей работы. Если Excel не запущен, то возникнет исключение.
Для запуска Excel необходимо воспользоваться классом Activator, описанным в пространстве имен System.
string sAppProgID = "Excel.Application";
// Получаем ссылку на интерфейс IDispatch
Type tExcelObj = Type.GetTypeFromProgID(sAppProgID);
// Запускаем Excel
object oExcel = Activator.CreateInstance(tExcelObj);
После того, как Вы получили ссылку на работающее приложение Excel, или же запустили его, Вам становится доступно вся объектная модель Excel.
С точки зрения программиста она выглядит так:

Marshal.ReleaseComObject(oExcel);
// Вызываем сборщик мусора для немедленной очистки памяти
GC.GetTotalMemory(true); Отмечу сразу, что если вызов GC.Collect() не помогает, то попробуйте очистку памяти этим способом. Если проигнорировать эту операцию, то в памяти останутся объекты Excel, которые будут существовать даже после того, как Вы завершите свое приложение и Excel. Если после этого запустить приложение NET и попытаться получить ссылку на работающий Excel, то мы без проблем ее получим. Но если мы заходим сделать Excel видимым (Установив ему свойство Visible в true), то при наличии MSExcel версии ранней, чем 2003, основное окно Excel прорисовывалось не полностью. На экране присутствовали только панели инструментов и окантовка основного окна. В MS Excel 2003 вроде бы такого не наблюдается. Но, тем не менее, если Ваша программа получает ссылки на какие-либо объекты Excel, Вы обязательно должны вызвать для них ReleaseComObject() класса Marshal. А перед завершением работы с Excel обязательно произведите очистку памяти: GC.GetTotalMemory(true);
Компонент ExcelDDEConnection.
Компонент ExcelDDEConnection представляет готовое решение, позволяющее организовать «горячий» канал DDE между приложением .NET и Excel. Компонент состоит из нескольких классов, главный из которых - ExcelDDEHotConnection. Экземпляр данного класса автоматически инициализируется в библиотеке DDEML при создании и отключается от ее при завершении своего существования.
Ниже приведены основные методы и свойства класса ExcelDDEHotConnection:
|
Название |
Описание |
|
ExcelDDEHotConnection() |
Конструктор. Осуществляет регистрацию в библиотеке DDEML |
|
TopicDescriptorCollection Topics |
Свойство. Ссылка на коллекцию разделов. Раздел адресуется названием книги и названием страницы |
|
void Dispose() |
Завершить работу объекта. Закрывает все каналы и производит отключение от библиотеки DDEML |
|
event AdviseDelegate Data |
Событие. Происходит при изменении содержимого любой из подписанных ячеек. Событие вызывается для каждой изменившейся ячейки. |
Коллекция разделов TopicDescriptorCollection.
Коллекция разделов представляет собой набор объектов, описывающий разделы. При добавлении раздела в коллекцию, происходит автоматическое создание канала, а при удалении – закрытие канала. Коллекция не допускает дублирование одинаковых разделов. Раздел добавляется в коллекцию только в том случае, если удалось создать канал для этого раздела.
| Название | Описание |
|
Result Add(TopicDescriptor descriptor) |
Добавить дескриптор раздела в коллекцию. В качестве параметра передается дескриптор раздела. При добавлении происходит попытка создать канал с разделом, который описывает данный дескриптор. Если такой раздел уже есть в коллекции, или не удалось создать канал, то данный дескриптор добавлен не будет. В первом случае функция вернет код возврата Result.AlreadyExists, а во втором случае – Result.ConversStartError. В случае успешного выполнения, дескриптор раздела добавляется в коллекцию, а метод возвращает код возврата Result.OK. |
|
Result Add(string book, string sheet) |
Добавить дескриптор раздела в коллекцию. В качестве параметра передается название книги book и страницы - sheet. При добавлении происходит попытка создать канал с разделом, который описывает дескриптор. Если такой раздел уже есть в коллекции, или не удалось создать канал, то данный дескриптор добавлен не будет. В первом случае функция вернет код возврата Result.AlreadyExists, а во втором случае – Result.ConversStartError. В случае успешного выполнения, дескриптор раздела добавляется в коллекцию, а метод возвращает код возврата Result.OK. |
|
Result Remove(TopicDescriptor descriptor) |
Удалить дескриптор из коллекции. В качестве параметра передается дескриптор раздела. При удалении происходит закрытие канала связи, при этом для всех ячеек раздела выполняется транзакция завершения. Если дескриптор не существовал в коллекции, метод вернет код возврата Result.NonExistingItem, а в случае ошибок, возникших при закрытии канала – Result.ConversStopError, но при этом дескриптор будет все равно удален из раздела. В случае удачного выполнения дескриптор удаляется из коллекции, а метод возвращает код Result.OK. |
|
Result Remove(string book, string sheet) |
Удалить дескриптор из коллекции. В качестве параметра передается название книги - book и страницы - sheet. При удалении происходит закрытие канала связи, при этом для всех ячеек раздела выполняется транзакция завершения. Если дескриптор не существовал в коллекции, метод вернет код возврата Result.NonExistingItem, а в случае ошибок, возникших при закрытии канала – Result.ConversStopError, но при этом дескриптор будет все равно удален из раздела. В случае удачного выполнения дескриптор удаляется из коллекции, а метод возвращает код Result.OK; |
|
void Clear() |
Метод удаляет все дескрипторы разделов из коллекции, при этом происходит закрытие всех каналов. |
|
void Dispose() |
Метод завершает работу коллекции – закрывает все каналы и удаляет все дескрипторы. |
|
int Count |
Свойство возвращает количество разделов, зарегистрированных в коллекции. |
|
TopicDescriptor this[string book, string sheet] |
Возвращает дескриптор по названию книги и страницы. |
|
TopicDescriptor this[int index] |
Возвращает дескриптор по его порядковому номеру в коллекции. |
|
TopicDescriptor this[string topic] |
Возвращает дескриптор по названию раздела в формате Excel. |
Дескриптор раздела TopicDescriptor.
Экземпляр класса описывает раздел данных. Каждый раздел содержит в себе коллекцию элементов данных типа ItemDescriptor, описывающих ячейки. При добавлении ячейки происходит отправка Excel транзакции на подписку на эту ячейку, при удалении – транзакция на завершение работы с ячейкой.
| Название | Описание |
|
TopicDescriptor(string book, string sheet) |
Конструктор. В качестве параметров получает название книги и страницы. |
|
Result Add(ItemDescriptor descriptor) |
Добавить дескриптор ячейки в список подписанных ячеек. В качестве параметров получает дескриптор ячейки . При добавлении происходит отправка транзакции Excel на подписку на эту ячейку. В случае успешного выполнения метод вернет код возврата Result.OK, а дескриптор будет добавлен в коллекцию. Если такой дескриптор уже существовал, или произошла ошибка при подписке, то дескриптор не будет добавлен в коллекцию. В первом случае метод вернет код возврата Result. AlreadyExists, а во втором – Result.SubscribeError. |
|
Result Add(int row, int col) |
Добавить дескриптор ячейки в список подписанных ячеек. В качестве параметров метод получает номер строки row и номер столбца col. При добавлении происходит отправка транзакции Excel на подписку на эту ячейку. В случае успешного выполнения метод вернет код возврата Result.OK, а дескриптор будет добавлен в коллекцию. Если такой дескриптор уже существовал, или произошла ошибка при подписке, то дескриптор не будет добавлен в коллекцию. В первом случае метод вернет код возврата Result. AlreadyExists, а во втором – Result.SubscribeError. |
|
Result Remove(ItemDescriptor descriptor) |
Удалить ячейку из списка подписанных ячеек. В качестве параметров принимает дескриптор ячейки. При удалении происходит отправка транзакции Excel на отписку от данной ячейки. Если при выполнении функции не произошло никаких ошибок, то метод вернет код возврата Result.OK. Если ячейка не существовала или при удалении произошли ошибки, то метод вернет в первом случае код
Result.NonExistingItem, а во втором – Result.UnsubscribeError, при этом ячейка будет удалена из списка подписанных ячеек. |
|
Result Remove(int row, int col) |
Удалить ячейку из списка подписанных ячеек. В качестве параметров принимает номер строки row и номер столбца col. При удалении происходит отправка транзакции Excel на отписку от данной ячейки. Если при выполнении функции не произошло никаких ошибок, то метод вернет код возврата Result.OK. Если ячейка не существовала или при удалении произошли ошибки, то метод вернет в первом случае код Result.NonExistingItem, а во втором – Result.UnsubscribeError, при этом ячейка будет удалена из списка подписанных ячеек. |
|
void Clear() |
Метод отменяет подписку на все ячейки из списка подписанных ячеек и очищает список. |
|
void Dispose() |
Метод отменяет подписку на все ячейки из списка подписанных ячеек и очищает список. |
|
int Count |
Свойство возвращает количество дескрипторов ячеек в списке. |
|
string Book |
Свойство возвращает название книги раздела, который описывает данный дескриптор. |
|
string Sheet |
Свойство возвращает название страницы раздела, который описывает данный дескриптор. |
|
string Topic |
Свойство возвращает название раздела в формате Excel, который описывает данный дескриптор. |
|
ItemDescriptor this[int index] |
Получить дескриптор ячейки по его порядковому номеру в списке подписанных ячеек. |
|
ItemDescriptor this[int row, int col] |
Получить дескриптор ячейки по номеру строки row и столбца col ячейки. |
|
ItemDescriptor this[string item] |
Получить дескриптор ячейки по названию в формате Excel. |
Дескриптор ячейки ItemDescriptor.
Описывает ячейку Excel.
| Название | Описание |
|
ItemDescriptor(int row, int col) |
Конструктор. Создает дескриптор ячейки строки номер row и столбца номер col. |
|
int Row |
Номер строки ячейки |
|
int Col |
Номер столбца ячейки |
|
string Item |
Название ячейки в формате MS Excel |
|
byte[] Data |
Массив с текущим содержимым ячейки. |
Экземпляр класса передается в качестве аргумента в событии Data.
| Название | Описание |
|
ItemDescriptor ItemDescriptor |
Дескриптор ячейки, в которой произошли изменения. Получить новое содержимое ячейки можно, воспользовавшись свойством Data |
|
TopicDescriptor TopicDescriptor |
Дескриптор раздела, в котором находится ячейка, содержимое которой изменилось. |
Литература и ссылки.
Фролов А.В. Фролов Г.В. Операционная система Microsoft Windows 3.1. для программиста. Дополнительные главы – М.: «ДИАЛОГ-МИФИ» 1995. (Библиотека системного программиста. Т.17) Троелсен Э. С# и платформа .NET. Библиотека программиста – СПб.: Питер, 2004. – Описание отображения функций WINAPI в .NET. Техническая документация MSDN – протокол DDE.
Описание протокола DDE
Начнем с краткого описания протокола DDE. Материал статьи охватывает только ту часть API протокола, которая необходима для организации «горячего» канала DDE.
Протокол DDE подразумевает клиент-серверную архитектуру. Это значит, что одно их приложений выступает в качестве сервера, а второе – клиента. В нашем случае сервером выступает приложение MS Excel, а приложения .NET являются для него клиентами. Обмен данными между приложениями происходит посредством транзакций. Управляет всем процессом специальное расширение ОС Windows - динамическая библиотека DDEML.
По протоколу DDE, сервер в первую очередь должен зарегистрировать себя в библиотеке DDEML. После этого он регистрирует предоставляемые сервисы.
Клиентское приложение также сначала регистрирует себя в библиотеке DDEML. После этого клиентское приложение создает канал связи с сервером.
Протокол DDE поддерживает три вида обмена данными между клиентом и сервером:
По явному запросу «Теплый канал» «Горячий канал»В первом случае клиент явным образом посылает серверу запрос, указывая нужный элемент данных. Сервер, получив подобный запрос, предоставляет клиенту эти данные.
В случае организации «теплого канала» сервер, при изменении данных, отправляет клиенту извещение. Клиент, получив это извещение, может послать запрос серверу на получение этих данных, после чего сервер предоставляет данные клиенту.
В случае «горячего канала» сервер будет отправлять клиенту данные, не ожидая явного запроса при их изменении.
На практике, как правило, используется либо передача данных по явному запросу, либо «горячий канал», причем второй очень удобен при организации быстрого обмена данными между приложениями в режиме реального времени. Именно «горячий» канал и будет рассматриваться в этой статье.
В библиотеке DDEML данные адресуются трехступенчатой схемой: сервис (service), раздел (topiс) и элемент данных (data item). Для сервера DDE приложения MS Excel, эта схема выглядит следующим образом:
Зарегистрированный сервис (service): “EXCEL” Разделы данных (topics): “[название_книги]название_страницы”, например “[Книга1]Лист1”. Элемент данных(item) – описание ячейки: “Rномер_строкиСномер_столбца”, например “R1C2” адресует ячейку в первой строке и во втором столбце.При этом нумерация строк в MS Excel начинается с единицы. Для установления связи, приложение должно сначала зарегистрировать себя в библиотеке DDEML и получить свой программный идентификатор. Этот идентификатор необходимо хранить в течение всей работы, так как для каждого приложения, которое регистрируется в библиотеке DDEML, создается своя копия необходимых структур данных.
Регистрация в библиотеке DDEML происходит с помощью функции DdeInitialize, которая имеет следующую сигнатуру:
UINT WINAPI DdeInitialize(
DWORD FAR* pidInst,
PFNCALLBACK pfnCallback,
DWORD afCmd,
DWORD ulRes);
Параметры, которые передаются функции при вызове:
pidInst – ссылка на переменную типа «двойное слово», в которую функция запишет программный идентификатор, присваиваемый приложения библиотекой DDEML. Перед вызовом функции программа должна обнулить значение этой переменной. pfnCallback – указатель на функцию обратного вызова. afCmd – набор битовых флагов инициализации, а также устанавливающий некоторые специфические условия работы с библиотекой. ulRes – зарезервировано и должно быть равно нулю. В случае успешной регистрации, функция DdeInitialize возвращает нулевое значение. Если при инициализации произошла ошибка, то функция вернет код ошибки.
Если приложение больше не собирается работать с библиотекой DDEML, то оно должно вызвать функцию DdeUninitialize, передав ей в качестве параметра программный идентификатор, полученный при регистрации:
BOOL WINAPI DdeUninitialize(DWORD idInst);
После успешной инициализации, клиентское приложение должно создать канал связи с сервером. Для каждого сервиса и раздела создается свой канал связи. После успешного создания канала, ему присваивается идентификатор, который указывается в дальнейших транзакциях, как клиентом, так и сервером.
Адресация происходит посредством строк, однако в транзакциях используются их идентификаторы. Эти идентификаторы присваиваются каждой строке библиотекой DDEML и хранятся в специальной системной таблице идентификации строк.
Для создания идентификатора строки, необходимо воспользоваться функцией DdeCreateStringHandle:
HSZ WINAPI DdeCreateStringHandle(
DWORD idInst,
LPCSTR psz,
Int iCodePage);
Функция получает следующие параметры:
idInst – программный идентификатор приложения, полученный при регистрации в библиотеке DDEML; psz – адрес текстовой строки, завершенной двоичным нулем. Длина строки не должна превышать 255 байт. iCodePage – кодовая страница, определяющая тип строки, получаемой на вход. При указании константы CP_WINANSI данная строка рассматривается как строка ANSI. Если указать константу CP_WINUNICODE, то строка рассматривается как состоящая из символов Unicode. Функция возвращает идентификатор, который библиотека DDEML присвоила данной строке.
Для того, чтобы освободить ресурсы, связанные с зарегистрированной строкой, клиентское приложение должно вызвать функцию отмены регистрации данной строки DdeFreeStringHandle:
BOOL WINAPI DdeFreeStringHandle(
DWORD idInst,
HSZ hsz);
В качестве параметров функция получает следующее:
idInst – программный идентификатор приложения, полученный при регистрации в библиотеке DDEML; hsz – идентификатор строки. Функция возвращает значение true, если операция прошла успешно, и false - если при выполнении функции произошли ошибки.
Для того, чтобы получить строку по ее идентификатору, необходимо воспользоваться функцией DdeQueryString:
DWORD WINAPI DdeQueryString(
DWORD idInst,
HSZ hsz,
LPSTR psz,
DWORD cchMax,
Int iCodePage
);
В качестве параметров функция получает следующее:
idInst - программный идентификатор приложения, полученный при регистрации в библиотеке DDEML; hsz – идентификатор строки, которую нужно получить. psz – указательна буфер, в который будет записана строка cchMax – максимальная длина строки в символах. Вид символа определяется следующим по порядку параметром и может быть ANSI (1 байт) или Unicode (2 байта) iCodePage – определяет тип символов строки. Возможные значения CP_WINANSI – для символов стандарта ANSI (1 байт) и CP_WINUNICODE – для символов стандарта Unicode (2 байта). Функция возвращает количество скопированных символов.
При этом если фактическая длина строки (в символах) меньше указанной в параметре cchMax, то функция скопирует cchMax символов и вернет это значение. Если cchMax больше фактической длины строки, то функция скопирует всю строку и вернет количество скопированных символов. Если передать через параметр psz нулевое значение, то функция проигнорирует значение параметра cchMax и вернет фактическую длину строки в символах. Размер буфера в байтах для строки зависит от размера символа и определяется параметром iCodePage.
Для получения данных из глобальной области памяти по их идентификатору нужно воспользоваться функцией DdeGetData:
DWORD WINAPI DdeGetData(
HDDEDATA hData,
void FAR* pDst,
DWORD cbMax,
DWORD cbOff
);
Функция должна получить на вход следующие параметры:
hData - идентификатор порции данных в глобальной области памяти; pDst – указатель на буфер, куда будут скопированы данные из глобальной области. cbMax – размер буфера в байтах. Если фактический размер данных больше размера области в буфере, которая выделяется под эти данные(см. ниже параметр cbOff), то будут скопированы только первые (cbMax – cbOff) байт. Иначе функция скопирует все данные в буфер. cbOff – смещение в буфере относительно начала, с которого функция поместит в буфер данные из глобальной области. Функция возвратит количество фактически скопированных байт данных. Если вместо ссылки на буфер через параметр pDst передать нулевое значение, то функция вернет фактический размер порции данных в глобальной области памяти, при этом значение параметров cbMax и cbOff будут проигнорированы.
Канал связи DDE создается с помощью функции DdeConnect:
HCONV WINAPI DdeConnect(
DWORD idInst,
HSZ hszService,
HSZ hszTopic,
CONVCONTEXT FAR* pCC);
В качестве параметров функция должна получить следующее:
idInst - программный идентификатор приложения, полученный при регистрации в библиотеке DDEML; hszService – идентификатор строки названия сервиса, который необходимо предварительно получить вызовом функции DdeCreateStringHandle hszTopic – идентификатор строки названия раздела, который также заранее запрашивается у библиотеки DDEML вызовом функции DdeCreateStringHandle; pCC – указатель на специальную структуру типа CONVCONTEXT, в которой указывается информация о национальном языке и кодовой странице.
В большинстве случаев ( в нашем тоже) достаточно указать нулевое значение, что означает использование кодовой страницы ANSI. Функция возвращает идентификатор созданного канала связи. В случае ошибки функция вернет нулевое значение. Полученный идентификатор канала необходимо хранить в течение всего сеанса связи.
Когда приложение завершает работу с каналом, оно должно закрыть его, вызвав функцию DdeDisconnect:
BOOL WINAPI DdeDisconnect(HCONV hConv);
В качестве параметра функция получает идентификатор канала, который нужно закрыть. Функция возвращает true, если канал успешно закрыт и false в случая возникновения ошибок при закрытии канала.
После того, как был создан канал связи, можно начинать обмен данными. Обмен происходит посредством транзакций с помощью функции DdeClientTransaction и функции обратного вызова DdeCallbackFunction. Если приложение (независимо от того, клиент или сервер) хочет отправить данные, то оно должно подготовить их, оформить контекст с помощью функций библиотеки DDEML , а потом вызвать функцию DdeClientTransaction. При этом принимающему приложению будет отправлено сообщение, которое осуществит вызов функцию обратного вызова принимающей стороны. Функции обратного вызова представляют особой обработчик с множественным ветвлением, каждая ветвь которого обрабатывает соответствующую ей транзакцию. Если транзакция не поддерживается, то функция обратного вызова должна вернуть нулевое значение, иначе – один из допустимых для обработанной транзакции, кодов возврата.
Функция обратного вызова имеет следующий заголовок:
HDDEDATA EXPENTRY DdeCallbackFunction(
WORD wType,
WORD wFmt,
HCONV hConv,
HSZ hsz1,
HSZ hsz2,
HDDEDATA hData,
DWORD dwData1,
DWORD dwData2
);
где:
wType - Код транзакции. Коды транзакций предопределены протоколом DDE. Значения и названия соответствующих им констант можно посмотреть в технической документации. Забегая вперед, отмечу, что в нашем примере будут использоваться транзакции XTYP_ADVSTART для запуска потока данных по каналу, XTYP_ADVSTOP – для остановки потока данных, XTYP_ADVDATA – транзакция с уведомлением наличии данных от сервера. wFmt – формат данных (в нашем случае данные представляют собой текстовую строку, поэтому этому параметру при вызове будет присвоено значение CF_TEXT, равное единице). hConv – идентификатор канала.
Этот идентификатор получен при создании канала. hsz1 – идентификатор строки названия раздела. hsz2 – идентификатор строки названия элемента данных. hData – идентификатор глобальной области в памяти, где находятся данные от сервера. Данные необходимо получить с помощью функции DdeGetData. В свою очередь функция запуска транзакции DdeClientTransaction имеет следующий заголовок:
HDDEDATA WINAPI DdeClientTransaction(
void FAR* pData,
DWORD cbData,
HCONV hConv,
HSZ hszItem,
UINT uFmt,
UINT uType,
DWORD dwTimeout,
DWORD FAR* pdwResult
);
pData - ссылка на данные, передаваемые транзакцией. cbData - размер передаваемых данных hConv - идентификатор канала связи, полученный заранее функцией DdeConnect hszItem - идентификатор элемента данных, в нашем случае - ячейки. Идентификатор должен быть получен заранее, с помощью функции DdeCreateStringHandle. uFmt - формат данных. Для случая с Excel указывается константа CF_TEXT(1) uType - код транзакции. Определяется комбинацией битовых флагов. В случае организации горячего канала выполняется транзакция XTYP_ADVSTART - для начала цикла получения данных из ячейки (подписки на ячейку) и XTYP_ADVSTOP - для прекращения цикла получения данных из ячейки (отписки от ячейки). dwTimeout - тайм-аут для синхронных транзакций - максимальное время выполнения синхронной транзакции. Если в качестве параметра передать 0, то будет запущена асинхронная транзакция. При запуске синхронной транзакции, приложение ждет ее завершения. При этом максимальное время выполнения транзакции определяется значением параметра. При запуске асинхронной транзакции приложение не ждет завершения транзакции и продолжает свою работу. По завершению транзакции клиент получит транзакцию XTYP_XACT_COMPLETE. pdwResult - ссылка на двойное слово, в которое будет записан код завершения транзакции. Изначально эта переменная должна быть приравнена к нулю. (По рекомендации Microsoft, не рекомендуется использовать этот параметр, так как, возможно, в дальнейшем он поддерживаться не будет). Возвращает нулевое значение, если транзакция была выполнена с ошибкой, или ненулевую величину, смысл которой зависит от транзакции, (В нашем случае будет возвращена единица) при нормальном выполнении.
Организация горячего канала Excel – приложение DDE.
В этой главе вкратце описано, как осуществить корректное подключение и отключение от ячеек Excel. Например, необходимо получить доступ к ячейке, расположенной во втором столбце и первой строке на странице с названием «Лист1» рабочей книги «Книга1». Для начала необходимо зарегистрироваться в библиотеке DDEML и получить программный идентификатор idInst:
// Создаем делегат-переходник для функции обратного вызова
_DDECallBack = new DDECallBackDelegate(DDECallBack);
// Регистрация в библиотеке DDEML
DDEML.DdeInitialize(ref idInst, _DDECallBack, 0, 0);
После этого создаем канал связи с нужным разделом. В нашем случае, как было упомянуто выше, название сервиса: «EXCEL», а название раздела «[Книга1.xls]Лист1». Необходимо помнить, что расширение файла необходимо указывать, если эта книга открыта из файла. Если осуществляется подключение к созданной, но еще не сохраненной книге, то расширение не указывается.
// Формируем название раздела
string szTopic = “[Книга1.xls]Лист1”;
// Получение идентификатора сервиса
IntPtr hszService = DDEML.DdeCreateStringHandle(_idInst, "EXCEL", DDEML.CP_WINANSI);
// Получаем идентификатор раздела
IntPtr hszTopic = DDEML.DdeCreateStringHandle(_idInst, szTopic, DDEML.CP_WINANSI);
// Подключаемся к разделу
IntPtr hConv = DDEML.DdeConnect(_idInst, hszService, hszTopic , (IntPtr) null);
// Проверяем результат
if(hConv!=IntPtr.Zero)
{
...
}
// Освобождаем идентификаторы строк
DDEML.DdeFreeStringHandle(_idInst, hszService);
DDEML.DdeFreeStringHandle(_idInst, hszTopic);
После создания канала информируем Excel о том, чтобы приложение получало содержимое нужной ячейки, как только оно изменится («горячий канал»). Для этого посылаем Excel транзакцию XTYP_ADVSTART:
// Формируем название ячейки
string szItem = “R1C2”;
// Создаем идентификатор строки
IntPtr hszItem = DDEML.DdeCreateStringHandle(_idInst, szItem, DDEML.CP_WINANSI);
// Подписываемся на тему
uint pwdResult = 0;
IntPtr hData = DDEML.DdeClientTransaction((IntPtr)null, 0, hConv, hszItem, DDEML.CF_TEXT, DDEML.XTYP_ADVSTART, 1000,ref pwdResult);
if(hData!=IntPtr.Zero)
{
...
}
// Освобождаем идентификатор строки
DDEML.DdeFreeStringHandle(_idInst, hszItem);
Отключение производим в обратном порядке, сначала информируем сервер о том, что данные из ячейки нам больше не нужны, посылая Excel транзакцию XTYP_ADVSTOP:
// Формируем название ячейки
string szItem = “R1C2”;
// Создаем идентификатор строки
IntPtr hszItem = DDEML.DdeCreateStringHandle(_idInst, szItem, DDEML.CP_WINANSI);
// Подписываемся на тему
uint pwdResult = 0;
IntPtr hData = DDEML.DdeClientTransaction((IntPtr)null, 0, hConv, hszItem, DDEML.CF_TEXT, DDEML.XTYP_ADVSTOP, 1000, ref pwdResult);
if(hData!=IntPtr.Zero)
{
...
}
// Освобождаем идентификатор строки
DDEML.DdeFreeStringHandle(_idInst, hszItem);
После завершения транзакции, закрываем канал:
//Закрываем канал
DDEML.DdeDisconnect(hConv);
И завершаем работу с библиотекой DDEML:
// Отключаемся от DDEML
DDEML.DdeUninitialize(idInst);
Необходимо отметить, что для всех трех режимов создается одинаковый канал. При этом для одних ячеек мы можем указывать «горячий» режим, для других – «теплый», а с третьими работать по явному запросу. Для того, чтобы включить «теплый» канал, необходимо отправить Excel транзакцию, код которой состоит из побитной комбинации кода транзакции XTYP_ADVSTART и флага XTYPF_NODATA.
Организация "горячего" обмена по DDE между Microsoft Excel и приложением .NET
ведущий .NET-разработчик компании
Microsoft Certified Application Developer
Отображение библиотеки DDEML в .NET
Библиотека DDEML представляет собой 32-разрядную библиотеку платформы Win32. Ее функции не могут быть вызваны непосредственно из приложения .NET. Для того, чтобы иметь возможность работать с этой библиотекой, нужно создать ее «отображение» в среде .NET, используя специальные средства. Таким образом, типы и структуры, с которыми работает библиотека будут автоматически преобразовываться средствами .NET в типы .NET и наоборот. Для доступа к функциям используется класс DLLImportAttribute, который описан в пространстве имен System.Runtime.InteropServices. Что касается типов параметров функций, как уже было сказано, среда .NET в большинстве случаев автоматически осуществляет все необходимые преобразования. В таблице 1 показаны подобные преобразования:
| Win32 | .NET |
| DWORD | uint |
| HCONV | IntPtr |
| HSZ | IntPtr |
| UINT | uint |
| DWORD * | ref uint |
| void* far | IntPtr или можно указать [Out] byte[], где [Out] – класс System.Runtime.InteropServices, который организовывает передачу данных от вызываемого объекта к вызывающему. |
Для функции обратного вызова необходимо создать делегат, который имеет соответствующую сигнатуру, и указать его в качестве параметра в функции DdeInitialize:
/// <summary>
/// Делегат функции обратного вызова DDE
/// </summary>
internal delegate IntPtr DDECallBackDelegate(
uint wType, // Код транзакции
uint wFmt, // Формат данных
IntPtr hConv, // Идентификатор канала
IntPtr hsz1, // Идентификатор строки (в нашем случае, строки раздела)
IntPtr hsz2, // Идентификатор строки (в нашем случае, элемента данных)
IntPtr hData, // Идентификатор глобальной области данных, где находятся данные
uint dwData1, // Дополнительный параметр (В нашей работе не рассматривается)
uint dwData2 // Дополнительный параметр (В нашей работе не рассматривается)
);
При этом отображение функции DdeInitialize в среде .NET будет выглядеть так:
internal class DDEML
{
[DllImport("user32.dll", EntryPoint="DdeInitialize", CharSet=CharSet.Ansi)]
internal static extern uint DdeInitialize(
ref uint pidInst, DDECallBackDelegate pfnCallback, uint afCmd, uint ulRes);
...
}
Ниже, я привожу пример вызова функции DdeInitialize в среде .NET:
public class ExcelDDEHotConnection
{
// Ссылка на делегат-переходник для функции обратного вызова DDE
private DDECallBackDelegate _DDECallBack = null;
// Обработчик функции обратного вызова
private IntPtr DDECallBack(
uint uType,
uint uFmt,
IntPtr hConv,
IntPtr hsz1,
IntPtr hsz2,
IntPtr hData,
uint dwData1,
uint dwData2)
{
switch(uType)
{
// Мы обрабатываем только транзакции с данными
case DDEML.XTYP_ADVDATA:
// Выполняем обработку транзакции
...
// Возвращаем управление
return new IntPtr(DDEML.DDE_FACK);
}
// Все остальные транзакции мы не обрабатываем
return IntPtr.Zero;
}
// Идентификатор приложения
private uint idInst = 0;
public ExcelDDEHotConnection()
{
// Создаем делегат-переходник для функции обратного вызова
_DDECallBack = new DDECallBackDelegate(DDECallBack);
// Регистрация в библиотеке DDEML
DDEML.DdeInitialize(ref idInst, _DDECallBack, 0, 0);
// выполняем остальные инициализирующие действия
...
}
...
}
Прошу обратить внимание на то, что ссылку на делегат функции обратного вызова мы храним все время работы с DDEML. Если этого не сделать, то сборщик мусора .NET уничтожит этот делегат при очередной сборке мусора, что приведет к тому, что во внутренних структурах библиотеки DDEML ссылка на функцию обратного вызова будет указывать на уничтоженный объект.
Это, естественно, вызовет NullPointerException при попытке библиотеки DDEML вызвать функцию обратного вызова. Поэтому вызов функции DdeInitialize следующего вида нежелателен:
// Регистрация в библиотеке DDEML
DDEML.DdeInitialize(ref idInst, new DDECallBackDelegate(DDECallBack), 0, 0);
Забегая вперед, отмечу, что для отображения необходимых функций и констант библиотеки DDEML в компоненте ExcelDDEHotConnection служит класс DDEML.
Ниже приведен список остальных функций для работы с DDE:
Делегат функции обратного вызова:
internal delegate IntPtr DDECallBackDelegate(
uint wType, //Код транзакции
uint wFmt, // Формат данных
IntPtr hConv, // Идентификатор канала
IntPtr hsz1, // Идентификатор строки (в нашем случае, строки раздела)
IntPtr hsz2, // Идентификатор строки (в нашем случае, элемента данных)
IntPtr hData, // Идентификатор глобальной области данных, где находятся данные
uint dwData1, // Дополнительный параметр (В нашей работе не рассматривается)
uint dwData2 // Дополнительный параметр (В нашей работе не рассматривается)
);
Отображение функции DdeInitialize:
[DllImport("user32.dll", EntryPoint="DdeInitialize", CharSet=CharSet.Ansi)]
internal static extern uint DdeInitialize(
ref uint pidInst, DDECallBackDelegate pfnCallback, uint afCmd,uint ulRes);
Отображение функции DdeUninitialize:
[DllImport("user32.dll", EntryPoint="DdeUninitialize", CharSet=CharSet.Ansi)]
internal static extern bool DdeUninitialize(uint idInst);
Отображение функции DdeCreateStringHandle:
[DllImport("user32.dll", EntryPoint="DdeCreateStringHandle", CharSet=CharSet.Ansi)]
internal static extern IntPtr DdeCreateStringHandle(
uint idInst, string psz,int iCodePage);
Отображение функции DdeFreeStringHandle:
[DllImport("user32.dll", EntryPoint="DdeFreeStringHandle", CharSet=CharSet.Ansi)]
internal static extern bool DdeFreeStringHandle(uint idInst, IntPtr hsz);
Отображение функции DdeConnect:
[DllImport("user32.dll", EntryPoint="DdeConnect", CharSet=CharSet.Ansi)]
internal static extern IntPtr DdeConnect(
uint idInst, IntPtr hszService, IntPtr hszTopic, IntPtr pCC);
Отображение функции DdeDisconnect:
[DllImport("user32.dll", EntryPoint="DdeDisconnect", CharSet=CharSet.Ansi)]
internal static extern bool DdeDisconnect(IntPtr hConv);
Отображение функции DdeClientTransaction:
[DllImport("user32.dll", EntryPoint="DdeClientTransaction", CharSet=CharSet.Ansi)]
internal static extern IntPtr DdeClientTransaction(
IntPtr pData, uint cbData, IntPtr hConv, IntPtr hszItem, uint uFmt,uint uType,
uint dwTimeout, ref uint pdwResult);
Отображение функции DdeGetData:
[DllImport("user32.dll", EntryPoint="DdeGetData", CharSet=CharSet.Ansi)]
internal static extern uint DdeGetData(
IntPtr hData, [Out] byte[] pDst, uint cbMax, uint cbOff);
Отображение функции DdeQueryString:
[DllImport("user32.dll", EntryPoint="DdeQueryString", CharSet=CharSet.Ansi)]
internal static extern uint DdeQueryString(
uint idInst, IntPtr hsz, StringBuilder psz, uint cchMax, int iCodePage);
Вступление.
В данной статье я хочу поделиться решением, которое наверняка будет многим полезно. Началось с того, что передо мной была поставлена задача организовать чтение данных из книги MS Excel, причем данные из ячеек нужно было считывать только в том случае, если они изменились. При этом были выдвинуты жесткие требования к скорости и оперативности обработки информации в изменившихся ячейках.
Перепробовав несколько решений, я остановился на механизме Dynamic Data Exchange, который, несмотря на преклонный возраст (DDE появился еще в Windows 3.0) и относительную громоздкость и трудоемкость в программировании остается наилучшим решением для организации быстрого обмена данными между приложениями. Однако программирование DDE приложения, тем более в среде .NET, которая не приветствует явного использования указателей и использование памяти вне ведома Garbage Collector, может вызвать вопросы, особенно у начинающих программистов. Вот на эти вопросы, которые в свое время возникли у меня, я и постараюсь ответить в данной статье. В конце статьи я приведу готовое решение – компонент ExcelDDEHotConnection, позволяющий организовать подписку на любую ячейку любой открытой книги, и скрывающий в себе все низкоуровневые операции. Данный компонент может быть свободно использован разработчиками в своих приложениях, при этом я не устанавливаю никаких ограничений или авторских прав на исходный код.